niki
2024 年12 月 23 日 13:43
#1
【 使用环境 】测试环境
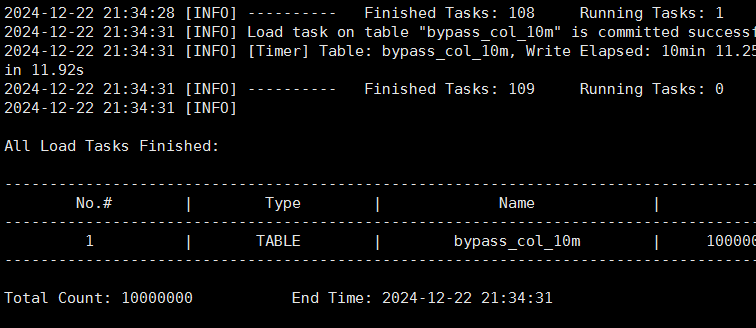
以上看到显示信息也是导入了1000万条
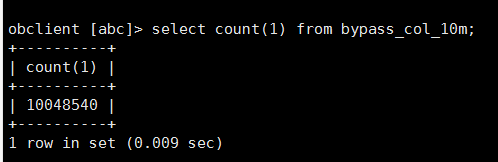
但是查询就不太对了(我确定我导入之前是空表、并且遇到这个问题我truncate表之后重复了几次这个导入验证都是数据有出入)
【复现路径】问题出现前后相关操作
【SOP系列 22 】——故障诊断第一步(自助诊断和诊断信息收集)
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手 ] 即可召唤小助手,欢迎试用!
1 个赞
论坛小助手
2024 年12 月 23 日 13:44
#3
根据您提供的信息,关于 obloader 导入的数据量有出入的问题,以下是详细的分析和建议:
确认导入日志
从您提供的日志片段来看,obloader 的导入任务确实已经成功完成,并且显示导入了 1000 万条记录。具体日志如下:
2024-12-22 21:34:31 [INFO] Load task on table “bypass_col_10m" is committed success
2024-12-22 21:34:31 [INFO] [Timer] Table: bypass_col_10m, Write Elapsed: 10min 11.2s
检查表结构和数据类型
请确保表 bypass_col_10m 的定义与导入的 CSV 文件中的数据格式完全匹配。特别是字段类型、长度等,避免因数据类型不匹配导致部分数据未能正确插入。
验证导入命令
您的导入命令如下:
obloader -h 192.168.5.88 -P 2883 -u root@brd -t brd -c racdb -p '+oB38QrB^R/nyZ;2e&(' --sys-password 'IMAVf~^64CIfeS' -D abc --table bypass_col_10m --external-data --csv -f /data/1000wgenerated_data.csv --truncate-table --column-separator=',' --thread 16 --rpc-port=2885 --direct --parallel=16
确保以下几点:
--truncate-table 选项会在导入前清空表,确保没有残留数据。
--column-separator=',' 确保 CSV 文件的列分隔符是逗号。
--thread 16 和 --parallel 16 表示使用多线程和并行导入,这可能会加速导入过程,但也可能引入一些并发问题。可以尝试减少线程数和平行度,观察是否能解决问题。
检查查询结果
您提到查询结果不对,但未提供具体的查询语句和结果。请确保查询时使用的表名和数据库名正确无误。您可以尝试以下步骤:
使用 DESCRIBE bypass_col_10m; 检查表结构。
使用 SELECT COUNT(*) FROM bypass_col_10m; 确认数据量。
如果可能,尝试导出部分数据并与原始 CSV 文件进行对比,确保数据一致性。
启用详细日志
为了进一步排查问题,建议启用 obloader 的详细日志输出,查看是否有任何警告或错误信息。可以通过添加 --log-level=DEBUG 参数来启用详细日志:
obloader ... --log-level=DEBUG
检查系统资源
确保在导入过程中,服务器的 CPU、内存、磁盘 I/O 等资源充足,避免因资源不足导致部分数据未能成功导入。
联系技术支持
如果以上步骤仍无法解决问题,建议收集详细的诊断信息(如 obdiag 日志)并联系 OceanBase 技术支持团队,获取更专业的帮助。
希望以上建议能帮助您解决数据导入量不一致的问题。如果有更多细节或疑问,请随时告知。
更多信息请查看:
0001 ~ 3999 4000 ~ 4499 9000 ~ 9499
2 个赞
淇铭
2024 年12 月 23 日 16:33
#4
可以提供表结构信息和数据么?内部想复现一下 看看具体的问题
2 个赞
niki
2024 年12 月 24 日 17:54
#5
bypass_col_10m.sql(去掉doc).doc (7.9 KB)https://anxia.com/s/swhdyhj332o?password=h2f4&#
2 个赞
论坛小助手
2024 年12 月 24 日 18:03
#6
感谢您提供的更多信息和附件。为了更准确地帮助您解决问题,我将详细检查您提供的建表语句和导入命令,并结合您的问题进行分析。
检查建表语句
请先查看您提供的 bypass_col_10m.sql 文件中的建表语句。以下是关键点:
表结构 :确保表的字段定义与 CSV 文件中的数据格式完全匹配。
分区类型 :确认是否使用了合适的分区类型(如 Range、Hash 等),并确保分区规则正确。
索引和约束 :检查是否有局部索引或约束可能影响数据插入。
假设建表语句如下(请根据实际内容调整):
CREATE TABLE bypass_col_10m (
id INT,
col1 VARCHAR(255),
col2 DATE,
...
)
PARTITION BY RANGE (id) (
PARTITION p0 VALUES LESS THAN (1000000),
PARTITION p1 VALUES LESS THAN (2000000),
...
);
验证 CSV 文件格式
下载并解压您提供的 CSV 文件,确保以下几点:
列分隔符 :确认 CSV 文件的列分隔符是逗号(,),与导入命令中指定的一致。
行结束符 :确保每行以换行符结束。
字段格式 :确认 CSV 文件中的字段格式与表结构中的字段定义一致,特别是日期、数字等类型的字段。
检查导入命令
再次确认您的 obloader 导入命令:
obloader -h 192.168.5.88 -P 2883 -u root@brd -t brd -c racdb -p '+oB38QrB^R/nyZ;2e&(' --sys-password 'IMAVf~^64CIfeS' -D abc --table bypass_col_10m --external-data --csv -f /data/1000wgenerated_data.csv --truncate-table --column-separator=',' --thread 16 --rpc-port=2885 --direct --parallel=16
确保以下参数设置正确:
--truncate-table:确保在导入前清空表。
--column-separator=',':确保 CSV 文件的列分隔符是逗号。
--thread 16 和 --parallel 16:多线程和并行导入可能会加速导入过程,但也可能引入并发问题。可以尝试减少线程数和平行度,观察是否能解决问题。
启用详细日志
为了进一步排查问题,建议启用 obloader 的详细日志输出,查看是否有任何警告或错误信息。可以通过添加 --log-level=DEBUG 参数来启用详细日志:
obloader ... --log-level=DEBUG
检查查询结果
确保查询时使用的表名和数据库名正确无误。您可以尝试以下步骤:
使用 DESCRIBE bypass_col_10m; 检查表结构。
使用 SELECT COUNT(*) FROM bypass_col_10m; 确认数据量。
如果可能,尝试导出部分数据并与原始 CSV 文件进行对比,确保数据一致性。
具体问题分析
根据您提供的信息,导入 1000 万条记录后,查询结果不一致。以下是可能的原因及解决方法:
数据重复或丢失
检查唯一键 :如果表中有唯一键或主键,确保 CSV 文件中没有重复的数据。
检查导入日志 :查看 obloader 的日志文件,确认是否有任何关于数据重复或丢失的警告或错误信息。
分区问题
检查分区规则 :确保分区规则正确,且所有数据都能正确落入相应的分区。
检查分区数量 :确保分区数量足够大,避免因分区过少导致性能问题或数据分布不均。
并发问题
减少线程数和平行度 :尝试减少 --thread 和 --parallel 参数值,观察是否能解决问题。
单线程导入测试 :使用单线程导入(即 --thread 1 --parallel 1),确保数据导入正确后再逐步增加并发度。
收集更多诊断信息
如果以上步骤仍无法解决问题,建议收集详细的诊断信息(如 obdiag 日志)并联系 OceanBase 技术支持团队,获取更专业的帮助。
示例验证
为了进一步验证问题,您可以尝试以下操作:
导入少量数据 :创建一个包含 100 条记录的小型 CSV 文件,使用相同的导入命令进行测试,确认是否能正确导入。
手动插入数据 :使用 INSERT INTO 语句手动插入几条记录,确认表结构和数据类型是否正确。
请按照上述步骤逐一排查问题,并提供更多的日志信息或诊断结果。如果有更多细节或疑问,请随时告知。希望这些建议能帮助您解决问题。
如果您需要进一步的帮助或有其他问题,请随时联系 OceanBase 技术支持团队。
更多信息请查看:
OceanBase 官方文档 obloader 使用指南
如果您有任何其他问题或需要进一步的帮助,请随时告诉我!
检索到的文档如下:
创建表 使用 SQL 快速进行向量检索 使用 Python 快速进行向量检索 Truncate 分区 指定分区查询数据 创建分区表 插入数据 分区操作 oceanbase.DBA_PART_INDEXES
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
1 个赞
niki
2024 年12 月 25 日 09:14
#8
170多个字段的1000万条数据 有60个G 我压缩后有2个G 附件它提示我只能传10兆大小的,或者有没有其他方法oceanbase 官方有云盘吗
2 个赞
niki
2024 年12 月 25 日 11:11
#11
好的!现在是这么个情况 我反复测试了一下 1000万条的文件我拆分成100万一个的文件入库 就不会count有差值,但是我拆分成500万的 入库也有差值
1 个赞