

实验环境
| 系统 | 环境 |
|---|---|
| Centos 7.9 | Docker、Python 3.9.19、OpenSSL 1.1.1k、pip、git、mariadb.x86_64 |
注意:
-
后续实验导包 Python 版本与 OpenSSL 有关系,在进行后续步骤前先确定 Python 版本与 OpenSSL 是否对应;若是干净的环境可以先确定 OpenSSL 版本是否要升级,先升级再部署 Python 环境,反之,若是在已有的 Python 环境下进行的升级则需要重新编译安装 Python 环境 携带参数–with-openssl,
./configure --prefix=/usr/local/python3 --with-openssl=/usr/local/openssl -
有一方法是通过调整 urllib3 的版本来不用更新 OpenSSL(
pip install urllib3==1.26.5),但是在后续模型下载载入过程同样的错误会再报(有可能是我没处理好),所以在后续多次推倒测试写步骤中我选择了先升级 OpenSSL 再进行 Python 环境编辑部署 -
如果 OpenSSL 一下子更新至 3.x 则需要 cpan IPC::Cmd 模块
-
至少需要 16G 运行内存以及 50G 磁盘空间(为什么这么清楚,因为我一开始就在起容器的时候爆红,滑稽)
-
如若参加了线下实战营可以直接跳到设置环境变量
-
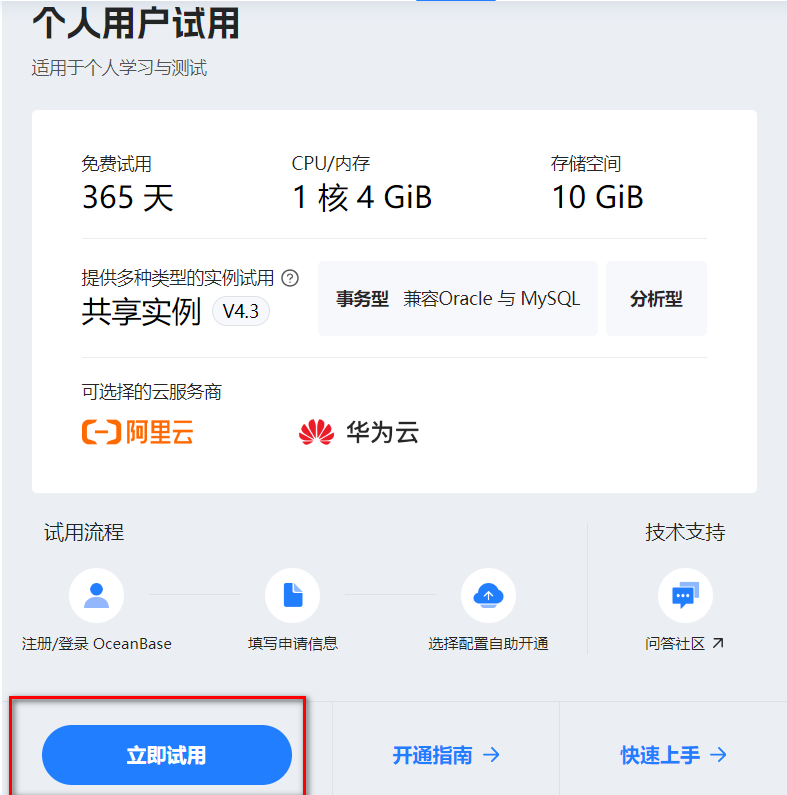
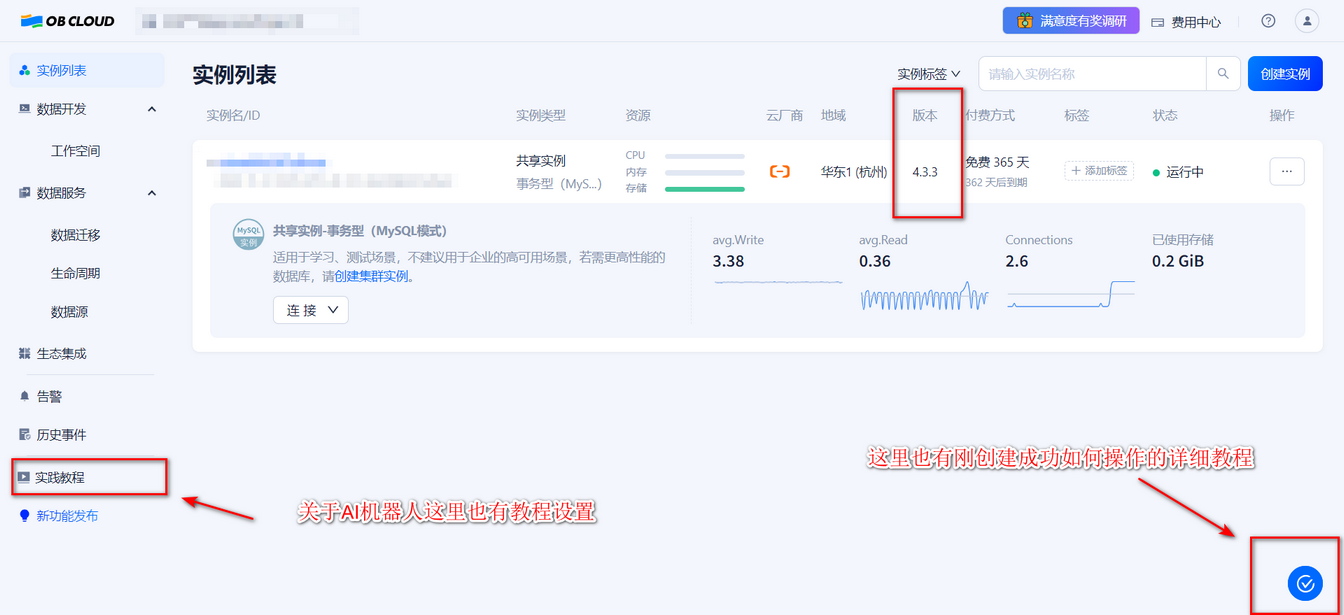
官方最近有活动可以申请免费试用365天的云数据库,版本也更新到了4.3,支持向量功能。后面参考链接也有老师是利用云数据库加个人资源搭建的,可以去参考实操,就可以不用起 Docker 环境了(现场也是有二维码提前开通云数据库),申请地址:https://www.oceanbase.com/free-trial,申请创建成功需要5~10 分钟
-
现场使用云数据库,需要准备好阿里云百炼 账号并获取 API Key(首次注册用户请留意上方有提示开通服务,选择开通并同意,不然后面模型加载会报错),然后关于后面环境变量文件的设置请注意里面说明要对应填写信息
-
确保实例工作台中设置了
ob_vector_memory_limit_percentage参数,以启用向量检索功能。推荐设置值为30 -
在进行验证数据库连接的时候,请确保你的实例所选择的账号是否具备权限(当时在现场创建的时候选择的是超级账户,进去之后没有去进行验证,就在说这对吗?这不对吧?不是数据导入成功了吗?库呢?怎么没显示?算了先进行后面步骤),在项目文档中有提到有个脚本会进行验证,在实例控制台获取连接串把对应信息填写进去即可,现场做到脚本验证提示权限不足,这时候

懂了,肯定账户创建有问题,跑回去实例工作台选择账号管理一看,怎么是普通账号且还没有授权数据库,因为当时和朋友现场选择的是超级账户。后面处理好之后,前面的问题都解决了
-
粗体文本可以跳到最后看参考链接,有各位老师对这些步骤详解
一、Docker 安装与启动镜像
打开阿里源的docker-ce源里面也有教程:docker-ce镜像_docker-ce下载地址_docker-ce安装教程-阿里巴巴开源镜像站
镜像加速
这里采用阿里云的镜像加速,阿里云登录 - 欢迎登录阿里云,安全稳定的云计算服务平台
mkdir -p /etc/docker
tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://niphmo8u.mirror.aliyuncs.com"]
}
EOF
systemctl daemon-reload
systemctl enable --now docker
拉取镜像并启动容器
docker run --ulimit stack=4294967296 --name=ob433 -e MODE=mini -e OB_MEMORY_LIMIT=8G -e OB_DATAFILE_SIZE=10G -e OB_CLUSTER_NAME=ailab2024 -p 127.0.0.1:2881:2881 -d quay.io/oceanbase/oceanbase-ce:4.3.3.1-101000012024102216
如果上述命令执行成功,将会打印容器 ID,如下所示:
9e52cf57b90b7276fd937273e2482451787b7617e43eaf77f5c5518e629b9a3e
检查 OceanBase 初始化是否完成
docker logs -f ob433
看到以下消息时,说明 OceanBase 数据库初始化完成:
check tenant connectable
tenant is connectable
boot success!
使用 Ctrl + C 退出日志查看界面。
测试数据库部署情况
yum -y install mariadb.x86_64 # 直接起一个 mariadb 来当客户端
mysql -h127.0.0.1 -P2881 -uroot@test -A -e "show databases"
部署成功的话,会出现以下表
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| oceanbase |
| test |
+--------------------+
二、安装依赖
Python
Python 版本要求 3.9 +
安装 Python 和 pip
安装 poetry
python3 -m pip install poetry
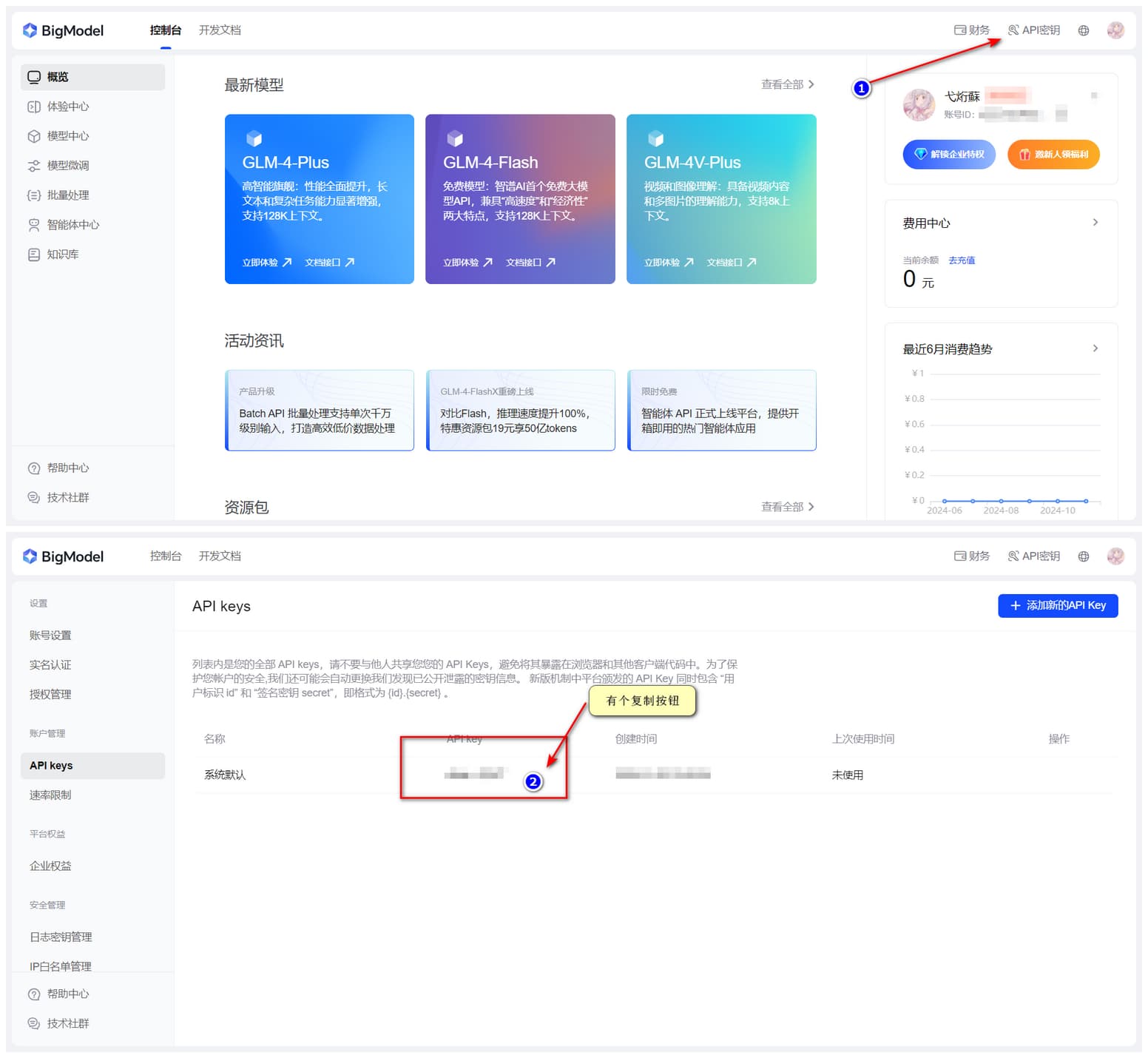
注册 智谱 AI 账号并获取 API Key
Git
克隆项目
mkdir /OB && cd !$
git clone https://gitee.com/oceanbase-devhub/ai-workshop-2024.git
进入目录
cd ai-workshop-2024
更改 poetry 源并管理依赖项
不改的话,网络不好的时候巨痛苦
# 修改 ai-workshop-2024/pyproject.toml 文件
cp pyproject.toml pyproject.toml-bak`date +%F`
vim pyproject.toml
# 原
[[tool.poetry.source]]
name = "PyPI"
priority = "primary"
# 改成
[[tool.poetry.source]]
name = "tsinghua"
url = "https://pypi.tuna.tsinghua.edu.cn/simple/"
priority = "supplemental"
国内一些 Pypi 源
阿里云 http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
豆瓣(douban) http://pypi.douban.com/simple/
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/
将 pyproject.toml 文件中手动添加的依赖项固定到 poetry.lock
不执行直接 poetry install 会报错
# poetry lock
Updating dependencies
Resolving dependencies... (1.5s)
通过运行 poetry lock,Poetry 处理pyproject.toml文件中的所有依赖项并将它们锁定到 poetry.lock 文件中。诗歌并不止于此。运行时poetry lock,Poetry 还会递归遍历并锁定您的直接依赖项的所有依赖项。
注意:
poetry lock如果有适合您的版本限制的新版本可用,该命令还会更新您现有的依赖项。如果您不想更新 poetry.lock 文件中已有的任何依赖项,则必须将 --no-update 选项添加到 poetry lock 命令中:poetry lock --no-update
使用 Poetry 来管理聊天机器人项目的依赖项
poetry install
成功如下
Installing dependencies from lock file
No dependencies to install or update
设置环境变量
cp .env.example .env
# 更新 .env 文件中的值,特别是 API_KEY 和数据库连接信息
vim .env
更新 API_KEY 为从智谱 AI 控制台获取的值,其他值可以保留为默认值
API_KEY=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx # 把这个配置项更新为您从智谱 AI 上获取到的 API_KEY
LLM_BASE_URL="https://open.bigmodel.cn/api/paas/v4/"
LLM_MODEL="glm-4-flash"
........
准备 BGE-M3 模型
poetry run python utils/prepare_bgem3.py
等待ing(速度取决于网络状况),成功如下
===================================
BGEM3FlagModel loaded successfully!
===================================
克隆文档仓库并处理(速度慢)
克隆 OceanBase 开源文档仓库并处理它们,生成文档的向量数据和其他结构化数据后将数据插入到部署好的 OceanBase 数据库中,速度看资源配置
cd doc_repos
git clone --single-branch --branch V4.3.3 https://github.com/oceanbase/oceanbase-doc.git
git clone --single-branch --branch V4.3.0 https://github.com/oceanbase/ocp-doc.git
git clone --single-branch --branch V4.3.1 https://github.com/oceanbase/odc-doc.git
git clone --single-branch --branch V4.2.5 https://github.com/oceanbase/oms-doc.git
git clone --single-branch --branch V2.10.0 https://github.com/oceanbase/obd-doc.git
git clone --single-branch --branch V4.3.0 https://github.com/oceanbase/oceanbase-proxy-doc.git
cd ..
格式转换
# 把文档的标题转换为标准的 markdown 格式
poetry run python convert_headings.py \
doc_repos/oceanbase-doc/zh-CN \
doc_repos/ocp-doc/zh-CN \
doc_repos/odc-doc/zh-CN \
doc_repos/oms-doc/zh-CN \
doc_repos/obd-doc/zh-CN \
doc_repos/oceanbase-proxy-doc/zh-CN
生成文档向量和元数据
# 生成文档向量和元数据
poetry run python embed_docs.py --doc_base doc_repos/oceanbase-doc/zh-CN
poetry run python embed_docs.py --doc_base doc_repos/ocp-doc/zh-CN --component ocp
poetry run python embed_docs.py --doc_base doc_repos/odc-doc/zh-CN --component odc
poetry run python embed_docs.py --doc_base doc_repos/oms-doc/zh-CN --component oms
poetry run python embed_docs.py --doc_base doc_repos/obd-doc/zh-CN --component obd
poetry run python embed_docs.py --doc_base doc_repos/oceanbase-proxy-doc/zh-CN --component odp
预处理数据获取
poetry run python utils/extract.py --output_file ~/my-data.json
三、启用
OS:这时候就该进行紧张刺激的启动环节了,鸣潮启动(啊?不是?那崩铁启动了)
启动聊天界面
poetry run streamlit run --server.runOnSave false chat_ui.py
访问终端中显示的 URL 来打开聊天机器人应用界面
You can now view your Streamlit app in your browser.
.........
四、天马行空
看到《试用 OceanBase 4.3.3 构建《黑神话:悟空》智能游戏助手 12》,我在想如果说在某一段时间把原神、鸣潮、崩铁等游戏进行 AI 机器人搭建融合对于游戏玩家的体验是否有所提高,在查询某角色培养攻略的时候可以做到武器、圣遗物、声骇等单一爆率爆伤计算、武器增幅计算,综合计算来提前对即将登场的角色进行抽取预估或者角色的数值面板生成。虽然说这些看起来都已经是有各种 APP 或者小程序或者QQ群机器人做到,但是大部分都只是做到角色评估是否毕业、哪个部位需要调整等。像原神都由玩家衍生出《高等元素论》、《元素反应基础》、《普通破盾学》、《伤害乘区论》、《韧性力学》、《元素反应详解》等等,这些计算理论都出现在了很多学生课堂之中(为什么知道呢?因为我就是试过,滑稽),可以和数学、物理等结合。让游戏玩家体验有所提高的同时,还可以通过这些计算之类详解辅助学生之间的知识吸取,因为在各种平台上也有各种 UP 对知识理论套进了游戏里面进行解释。