【 使用环境 】生产环境 or 测试环境
【 OB or 其他组件 】ob 4.2.1.7
【 使用版本 】ocp 4.2.2
【问题描述】清晰明确描述问题
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【SOP系列 22 】——故障诊断第一步(自助诊断和诊断信息收集)
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
根据官方文档收集:
PID=$(cat /home/admin/ocp_agent/run/ocp_monagent.pid)
SOCKET=$PID
内存采样数据
curl --unix-socket /home/admin/ocp_agent/run/ocp_monagent.$(cat /home/admin/ocp_agent/run/ocp_monagent.pid).sock http://localhost/debug/pprof/heap --output pprof.heap.gz
内存占用:
占比最高的有方法处理吗
参考了帖子:
monagent频繁自动重启 - 社区问答- OceanBase社区-分布式数据库
1 个赞
论坛小助手
#3
根据文档库中的信息,当遇到 monagent 进程频繁自动重启的问题时,可以通过以下步骤进行 pprof 分析,并根据分析结果采取相应的措施:
1. 收集环境上下文信息
首先,需要收集 monagent 进程的环境上下文信息,包括当前进程所占内存、父子进程所占内存(ocp_agentd 为当前进程的父进程),以及当前进程的内存性能分析文件。具体操作如下:
PID=$(cat /home/admin/ocp_agent/run/ocp_monagent.pid)
SOCKET=$PID
# 协程性能数据
curl --unix-socket /home/admin/ocp_agent/run/ocp_monagent.$PID.sock http://11/debug/pprof/goroutine?debug=1 --output /tmp/goroutine.txt
# CPU 性能采样数据
curl --unix-socket /home/admin/ocp_agent/run/ocp_monagent.$PID.sock http://localhost/debug/pprof/profile?seconds=30 --output pprof.profile.gz
# 内存采样数据
curl --unix-socket /home/admin/ocp_agent/run/ocp_monagent.$PID.sock http://localhost/debug/pprof/heap --output pprof.heap.gz
2. 分析内存采样数据
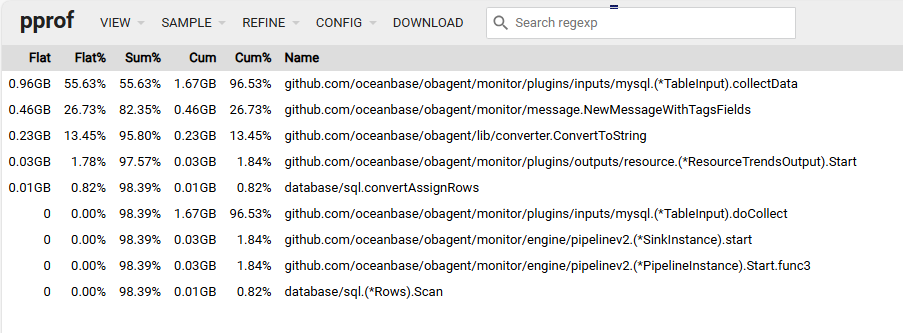
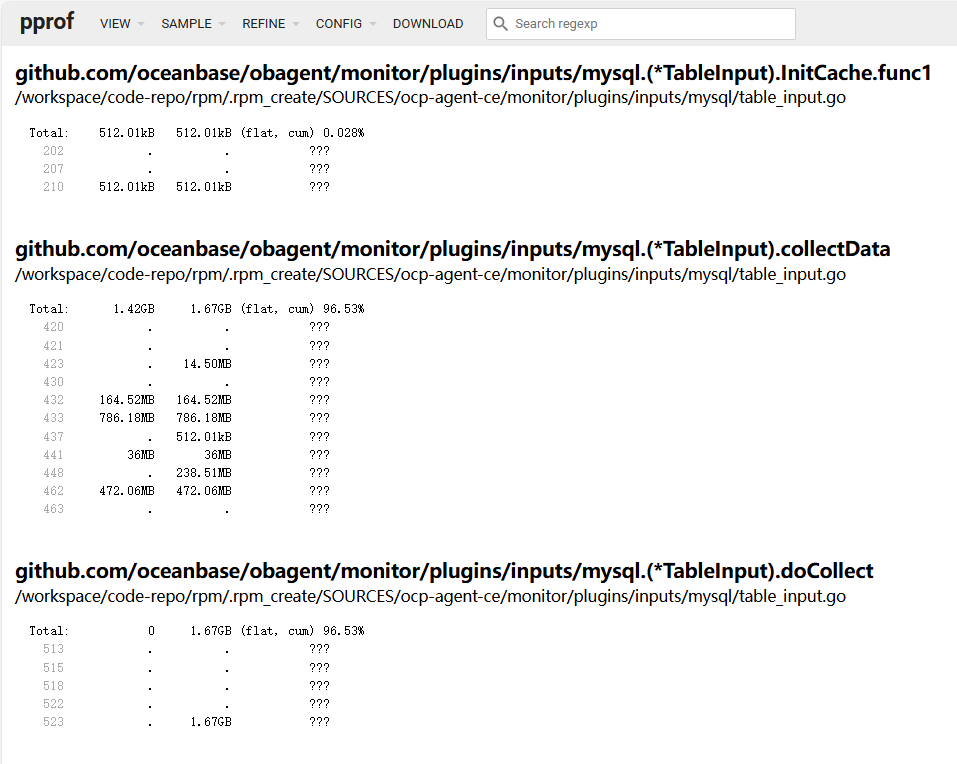
根据您提供的内存采样数据,可以看到 github.com/oceanbase/obagent/monitor/plugins/inputs/mysql.(*TableInput).collectData 方法占用了较高的内存。这可能是导致 monagent 进程频繁重启的原因之一。
3. 采取措施
3.1 重启 Agent 进程
如果内存占用过大(超过 10 GB)或 Go 协程数量超过 10 万,应立即重启 Agent 进程,防止问题影响 OceanBase 数据库组件正常运行。
/home/admin/ocp_agentctl service restart ocp_monagent
3.2 调整内存限制
如果内存占用在可接受范围内(如 2G 以内),可以尝试调整 monagent 的内存限制。修改 /home/admin/ocp_agent/conf/agentd.yaml 文件中的 ocp_monagent.imit.memoryQuota 参数,如将内存调整为 2.5 GB。
ocp_monagent:
imit:
memoryQuota: 2.5G
3.3 检查日志
检查 ocp_monagent.error.log 文件,搜索 panic 关键字,确认是否存在进程 BUG 导致的问题。如果发现相关日志,可以尝试启动进程(守护进程会尝试拉起,若失败请人工拉起)。
/home/admin/ocp_agentctl service start ocp_monagent
3.4 更正配置
如果配置错误导致进程重启失败,可尝试先更正自定义配置,然后启动进程。
4. 提供环境上下文信息给运维人员
将收集到的环境上下文信息提供给运维人员,以便进一步分析和解决问题。信息包括:
- 当前进程所占内存
- 父子进程所占内存(ocp_agentd 为当前进程的父进程)
- 当前进程的内存性能分析文件
希望以上步骤能帮助您解决 monagent 进程频繁自动重启的问题。如果问题仍然存在,请联系 OceanBase 的技术支持人员获取更多帮助。
更多信息请查看:
- 进程常驻内存
- 进程线程数
- OCP-Agent 进程协程数
- host_agent_goroutine_count_over_threshold 服务器 Agent 协程数超限
- monagent_process_stop ocp_monagent 进程停止
- host_agent_open_fd_count_over_threshold 服务器 Agent 文件句柄数超限
- 系统内存不足/泄漏
- ODP 端故障
- 租户内存写满
- 常见内存问题
- OceanBase 数据库社区版 V3.1.4
旭辉
#4
先扩大agent的内存配置观察下
1.执行 /home/admin/ocp_agent/bin/ocp_agentctl config -u monagent.limit.memory.quota=4096MB 命令修改ocp_monagent进程内存限制的参数值,monagent.limit.memory.quota 默认值是2048MB;
2.重启ocp_agent后生效
论坛小助手
#6
根据您提供的信息,即使将 ocp_monagent 的内存限制调大到 4G,仍然会出现 OOM(Out of Memory)的情况。这表明 ocp_monagent 进程的内存使用可能存在问题,需要进一步排查和优化。
1. 深入分析内存使用情况
您可以使用 pprof 工具进一步分析内存使用情况,特别是 github.com/oceanbase/obagent/monitor/plugins/inputs/mysql.(*TableInput).collectData 方法的内存使用情况。
1.1 收集内存采样数据
PID=$(cat /home/admin/ocp_agent/run/ocp_monagent.pid)
SOCKET=$PID
# 内存采样数据
curl --unix-socket /home/admin/ocp_agent/run/ocp_monagent.$PID.sock http://localhost/debug/pprof/heap --output pprof.heap.gz
1.2 分析内存采样数据
使用 pprof 工具分析内存采样数据:
go tool pprof pprof.heap.gz
在 pprof 交互界面中,可以使用以下命令来查看内存使用情况:
-
top:显示内存使用最多的函数。
-
list github.com/oceanbase/obagent/monitor/plugins/inputs/mysql.(*TableInput).collectData:查看特定函数的内存使用情况。
-
web:生成一个 HTML 报告,方便可视化分析。
2. 优化 collectData 方法
根据 pprof 分析结果,如果 github.com/oceanbase/obagent/monitor/plugins/inputs/mysql.(*TableInput).collectData 方法确实占用了大量内存,可以考虑以下优化措施:
2.1 减少数据采集频率
降低 collectData 方法的数据采集频率,减少内存消耗。可以在 agentd.yaml 配置文件中调整相关参数,例如:
ocp_monagent:
plugins:
mysql:
collect_interval: 60s # 增加采集间隔时间
2.2 优化数据处理逻辑
检查 collectData 方法的实现,确保没有不必要的内存分配和数据拷贝。可以尝试以下优化:
- 使用更高效的数据结构。
- 减少临时对象的创建。
- 释放不再使用的内存。
3. 监控和报警
设置监控和报警,及时发现和处理内存使用异常情况。可以在 OCP 平台上配置以下监控指标:
-
ocp_monagent 进程的内存使用情况。
-
ocp_monagent 进程的 CPU 使用情况。
-
ocp_monagent 进程的 Goroutine 数量。
4. 日志分析
检查 ocp_monagent 的日志文件,特别是 ocp_monagent.error.log,查找是否有内存相关的错误信息。这些日志可以帮助您定位问题的具体原因。
5. 联系技术支持
如果以上措施仍然无法解决问题,建议联系 OceanBase 的技术支持团队,提供详细的日志和分析报告,以便他们能够更好地帮助您解决问题。
希望以上步骤能帮助您解决 ocp_monagent 进程频繁 OOM 的问题。如果有任何其他问题或需要进一步的帮助,请随时联系 OceanBase 的技术支持团队。
详情请参考:
- cpu_quota_concurrency
- GV$OB_MEMORY
- V$OB_MEMORY
- writing_throttling_maximum_duration
- GV$OB_PLAN_CACHE_PLAN_STAT
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
旭辉
#9
应该是业务集群的分区数太多,可以查下
select count(*) from CDB_OB_TABLE_LOCATIONS;
如果不太关注租户-资源管理的话,可以将分区磁盘的采集给停掉
旭辉
#11
目前ocp老师给出解决方案:
1.停掉租户-资源管理磁盘的监控
命令:/home/admin/ocp_agent/bin/ocp_agentctl config -u monagent.pipeline.tenant.disk.collect.disabled=true
2.如果节点内存够可以调大内存,也可以偶尔重启一下agent