【 使用环境 】生产环境
【 OB or 其他组件 】三节点observer,ocp
【 使用版本 】OceanBase-CE 4.3.4.0
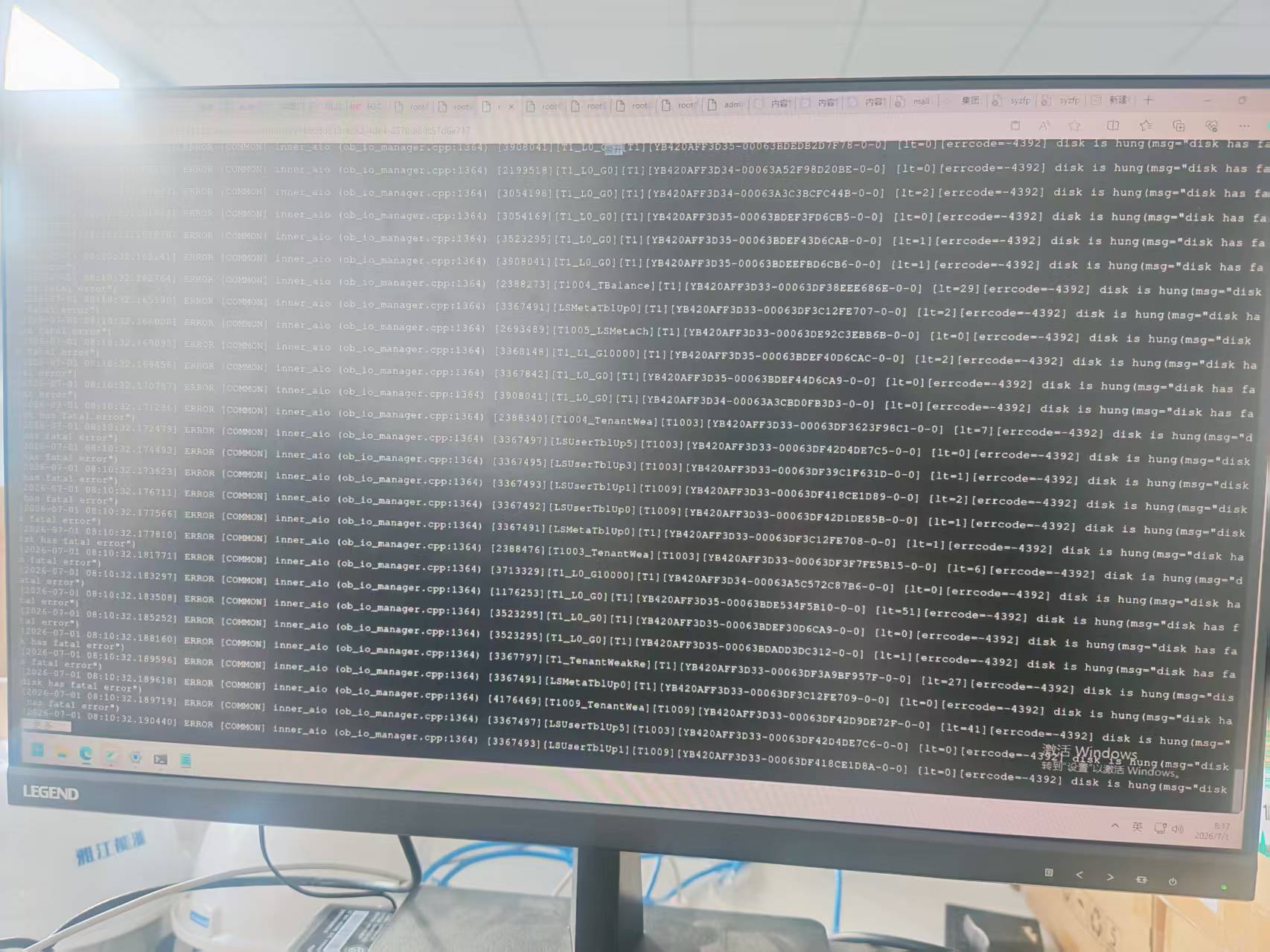
【问题描述】社区版的三节点的ob集群搭建到云主机上,云主机磁盘问题导致ob集群不可用,三台observer.log中都有【errcode=-4392】disk is hung。
【复现路径】
1、查看observer.log
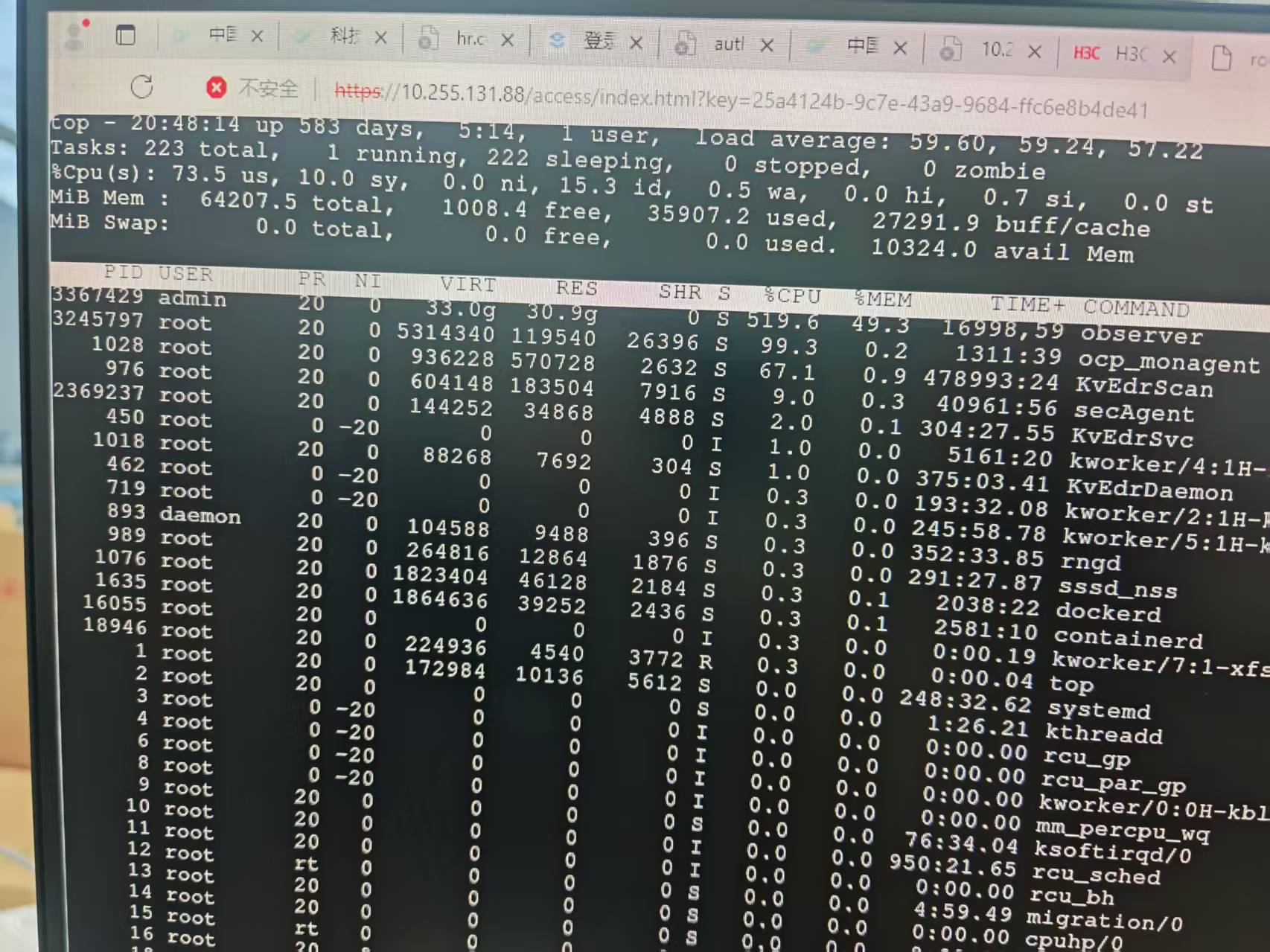
2、查看负载
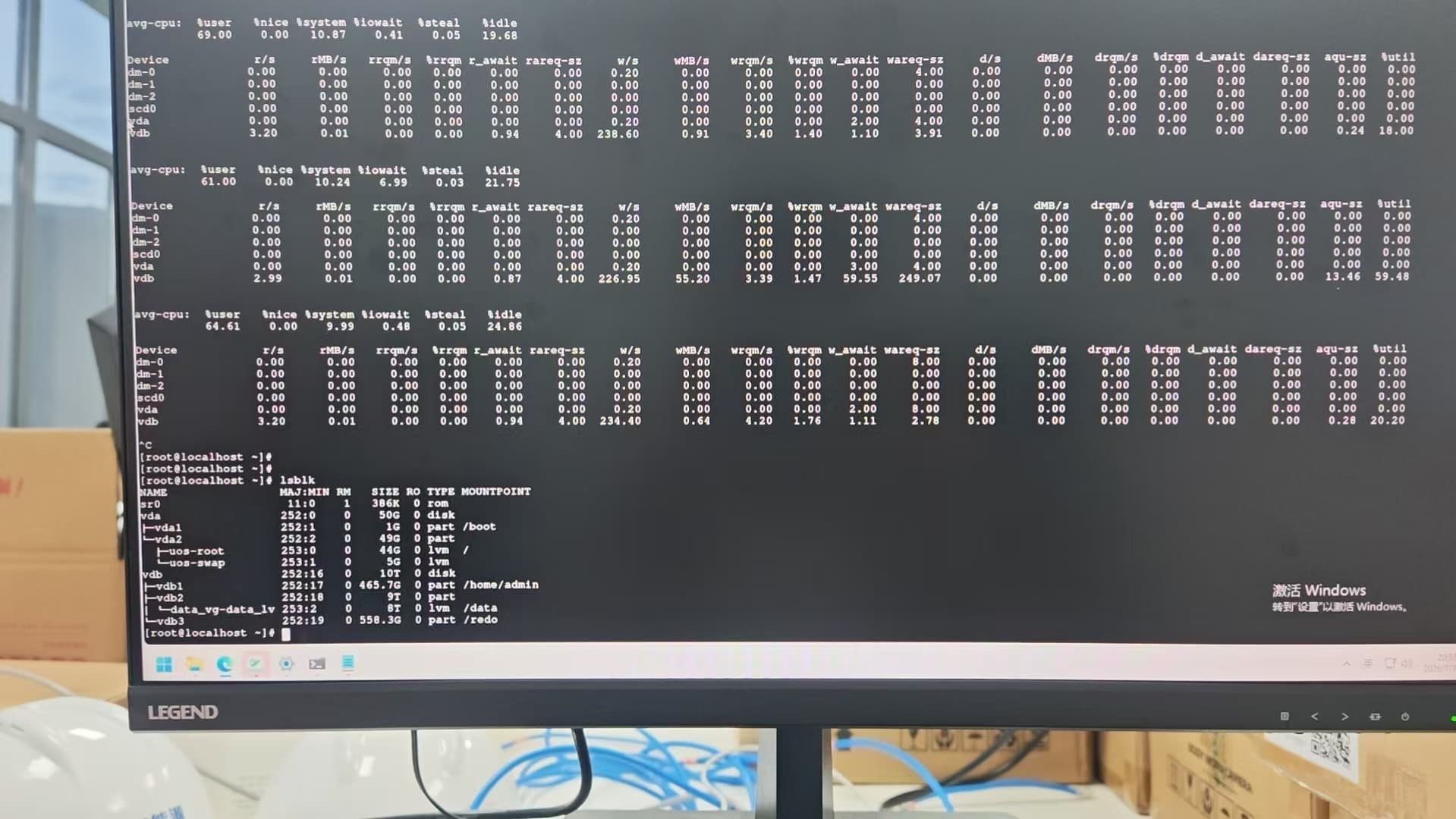
3、查看io
4、关闭所有业务连接,等待ob集群自愈,没有效果
【附件及日志】
rootservice.log (15.4 KB)
alert.log (297.2 KB)
observer.log.20260701141120564.txt (276.2 KB)
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
3 个赞
论坛小助手
#3
根据您描述的问题,OceanBase集群遇到了磁盘挂起的问题,导致了集群无法正常访问。针对这一情况,建议使用obdiag工具来收集相关的诊断信息,并通过根因分析功能来定位问题的具体原因。
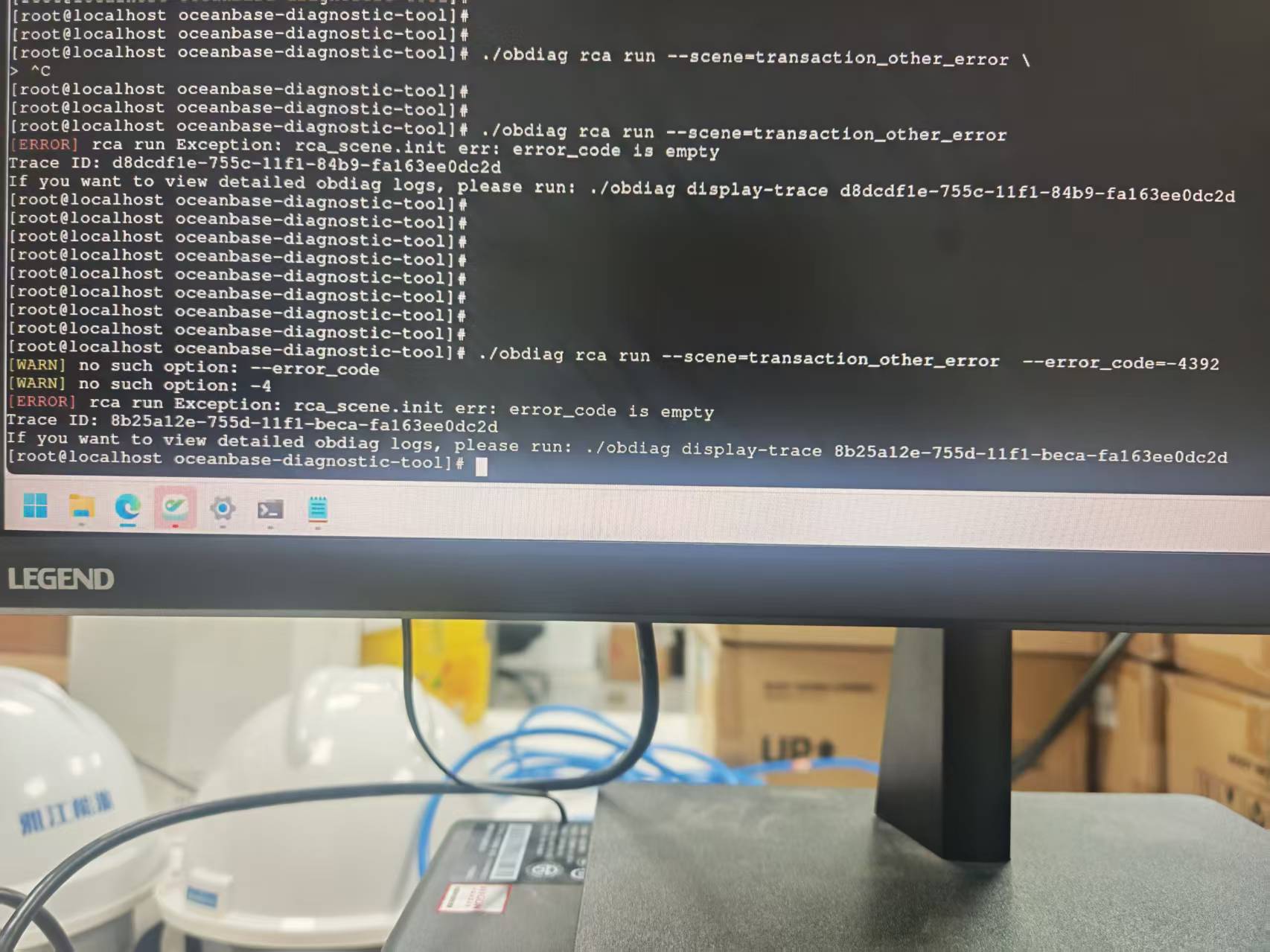
根因分析场景: 事务其他错误
根因分析命令: obdiag rca run --scene=transaction_other_error
日志采集场景: 集群无法连接
日志采集命令: obdiag gather scene run --scene=observer.cluster_down
上述命令将帮助我们从您的系统中获取关于集群当前状态的重要信息,特别是与磁盘相关以及集群连接性相关的信息。执行完这些命令后,请提供生成的日志压缩包给我们以进行进一步的分析。
为了更准确地诊断此问题,能否请您回答以下几项问题以便提供更多背景细节:
- 在发生该问题之前,是否有执行过大规模的数据导入、导出或修改操作?
- 问题出现时,是否同时观察到了服务器硬件层面(如硬盘故障指示灯亮起)或其他软件服务也表现出异常行为?
- 是否能告知受影响的Observer节点编号或者IP地址?这有助于我们在提供的日志中快速定位相关信息。
- 您的OceanBase集群配置详情,比如版本号、部署模式(单机还是多机)、使用的存储介质类型等。
- 如果可能的话,可以分享下
observer.log中具体的错误日志片段吗?直接引用含有错误代码-4392及其上下文的内容即可。
感谢您的配合!
附上敏捷诊断工具 obdiag 使用帮助链接
4 个赞
现在ocp的服务已关闭,开启后,clog日志目录疯狂增长,现在已经达到95%
3 个赞
rca_scene.init err: error_code is empty
1 个赞
淇铭
#10
ob434这个版本不建议使用了 社区也不再维护了 如果使用oltp LTSob425bp7或者olap LTSob435bp5版本
淇铭
#11
[2026-07-01 14:11:14.515716] WDIAG [SHARE] alloc_block (ob_local_device.cpp:580) … [errcode=-4184]
Fail to alloc block(ret=-4184, free_block_cnt_=0, total_block_cnt_=3773956)
[2026-07-01 14:11:14.515747] WDIAG [MDS] on_flush_ … [errcode=-4184]
[FLUSH]flush failed(ret=-4184, ret=“OB_SERVER_OUTOF_DISK_SPACE”, …)
看着数据盘 macro block 已完全耗尽,盘满导致 IO 变慢/失败,IO 失败触发 hung 保护;hung 保护又阻止合并回收空间。看着是 -4184 (盘满)与 -4392 (disk hung)同时存在,互为加重
tangzh
#12
那现在这种情况,能不能根据sstable回复一点数据呢?
淇铭
#13
你可以使用ob_admin解析一下 看看 是否能解析出来数据
tangzh
#14
有没有详细的操作步骤,现在数据库登录不上
使用如下命令:
./ob_admin dumpsst -d macro_block -f <block_file_path> -a <macro_id>
<macro_id>:宏块的下标这也查不到
-4392 disk is hung 是 OB 检测到磁盘 IO 长时间无响应触发的保护,根子在底层云盘 IO,不是 OB 自己能自愈的,所以关业务硬等没用。先从系统层确认:dmesg、云盘监控看是不是云盘故障或 IO 延迟飙高、util 打满。处理思路:优先联系云厂商修复磁盘 IO(换盘/迁移云盘),盘恢复正常后 observer 一般能重新拉起;如果是单节点盘坏而另外两副本还在(多数派健康),可以先把坏节点 observer 停掉、让集群用剩余副本继续对外服务,等盘修好再把该节点重新加回。核心是先解决云盘,OB 层面等不出来。
2 个赞