

AI 系列课程第一季 ——《Easy Data x AI》完整课程内容传送门
今天更新了 Easy Data x AI 课程的第二讲 —— AI Agent 全景图:从对话到智能体。欢迎大家点击上方链接,学习完整课程内容~
在上节课《大模型的本质与边界》中,我们聊了大模型的本质与边界,核心公式是:
AI 能力上限 = 数据质量 × 模型能力
这节课,公式升级了:
Agent 能力上限 = 数据质量 × 模型能力 + 流程编排
什么意思?往下看这期课程的大纲 ![]()
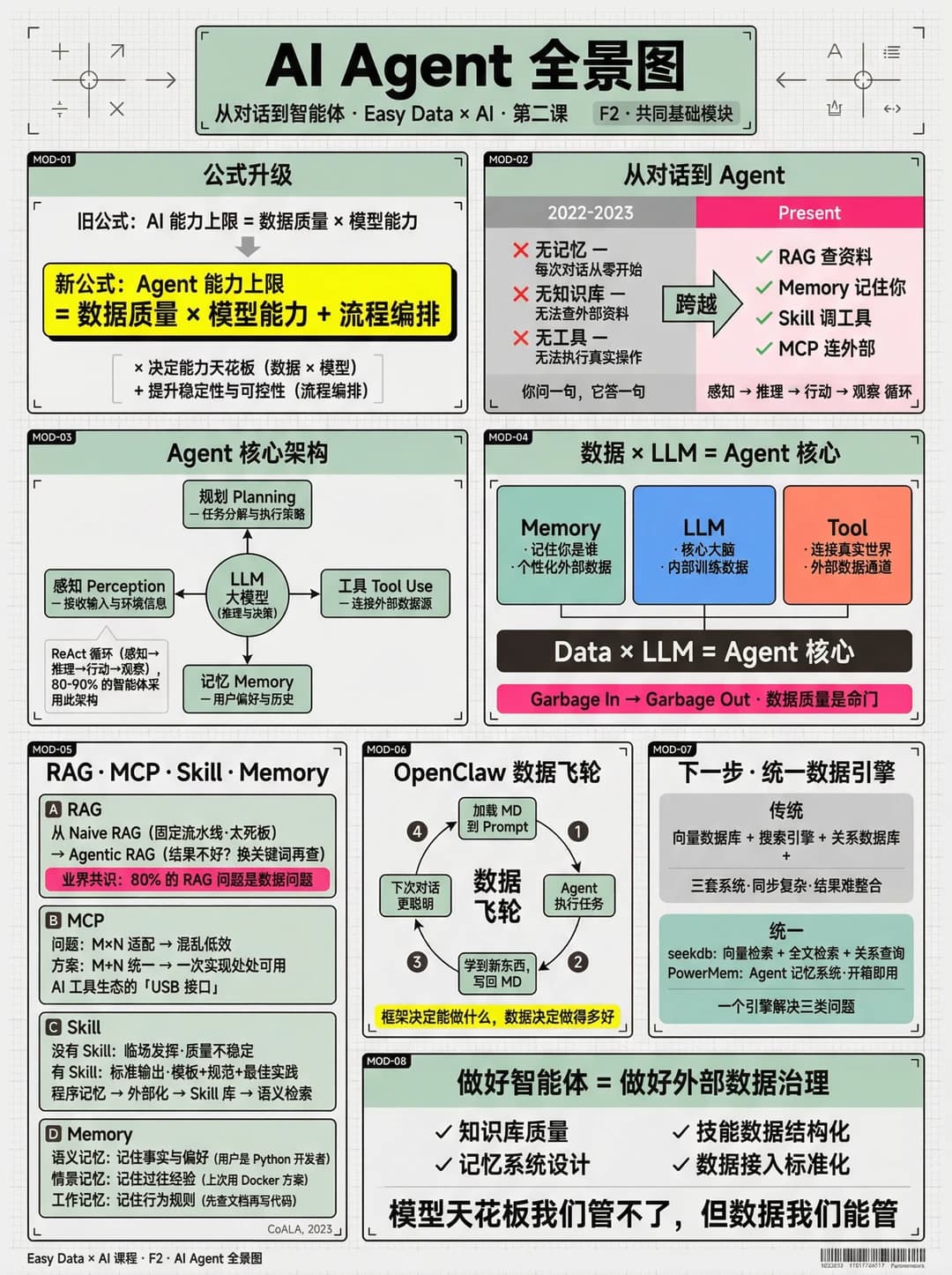
![]() 从对话到 Agent 的跨越
从对话到 Agent 的跨越
2022-2023 年的 ChatGPT:你问一句,它答一句。
没记忆、没知识库、没工具——本质是个「无状态的回答机器」。
而 Agent 能做的事完全不同:
RAG 查资料 + Memory 记住你 + Skill 调工具 + MCP 连外部
![]() Agent 的核心架构
Agent 的核心架构
一句话:LLM 是大脑,外挂四大能力——
规划、工具、记忆、感知。
80-90% 的智能体都在用 ReAct 循环:
感知 → 推理 → 行动 → 观察 → 循环
![]() 四大组件速览
四大组件速览
· RAG:从固定流水线到 Agentic RAG,结果不好就换关键词再查。业界共识:80% 的 RAG 问题是数据问题。
· MCP:AI 工具生态的「USB 接口」,一次实现处处可用。
· Skill:把专业经验变成数据,从临场发挥到标准输出。
· Memory:语义记忆 + 情景记忆 + 工作记忆,让 Agent 真正记住你。
![]() 最重要的一句话
最重要的一句话
做好智能体 = 做好外部数据治理
模型天花板我们管不了,但数据我们能管。
知识库质量、记忆系统设计、技能数据结构化、数据接入标准化——这四件事才是你该花时间的地方。