【 使用环境 】测试环境
【 OB or 其他组件 】Oceanbase 4.4.2
【 使用版本 】Oceanbase 4.4.2 & OCP 4.4.1
【问题描述】
老师,您好,
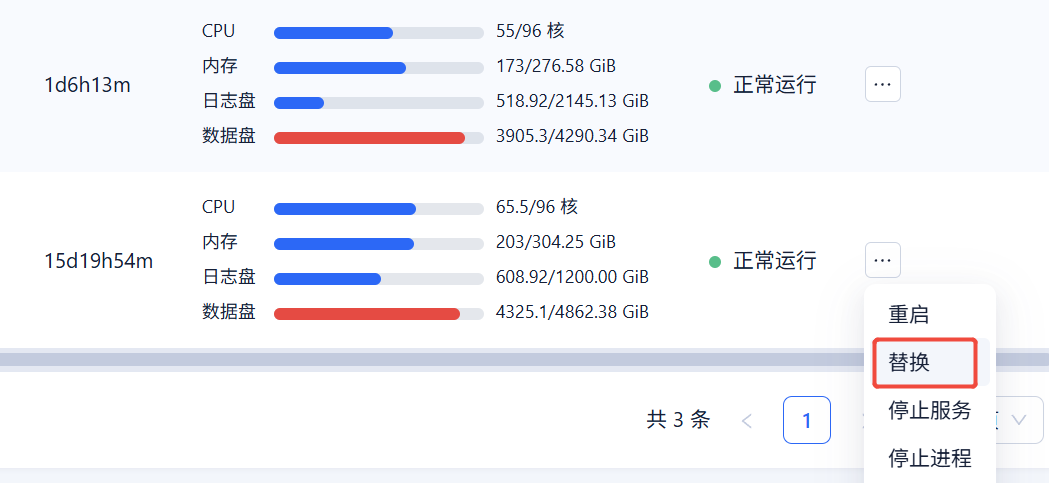
我们因为服务器配置调整,计划对Oceanbase集群中的节点进行“替换”,
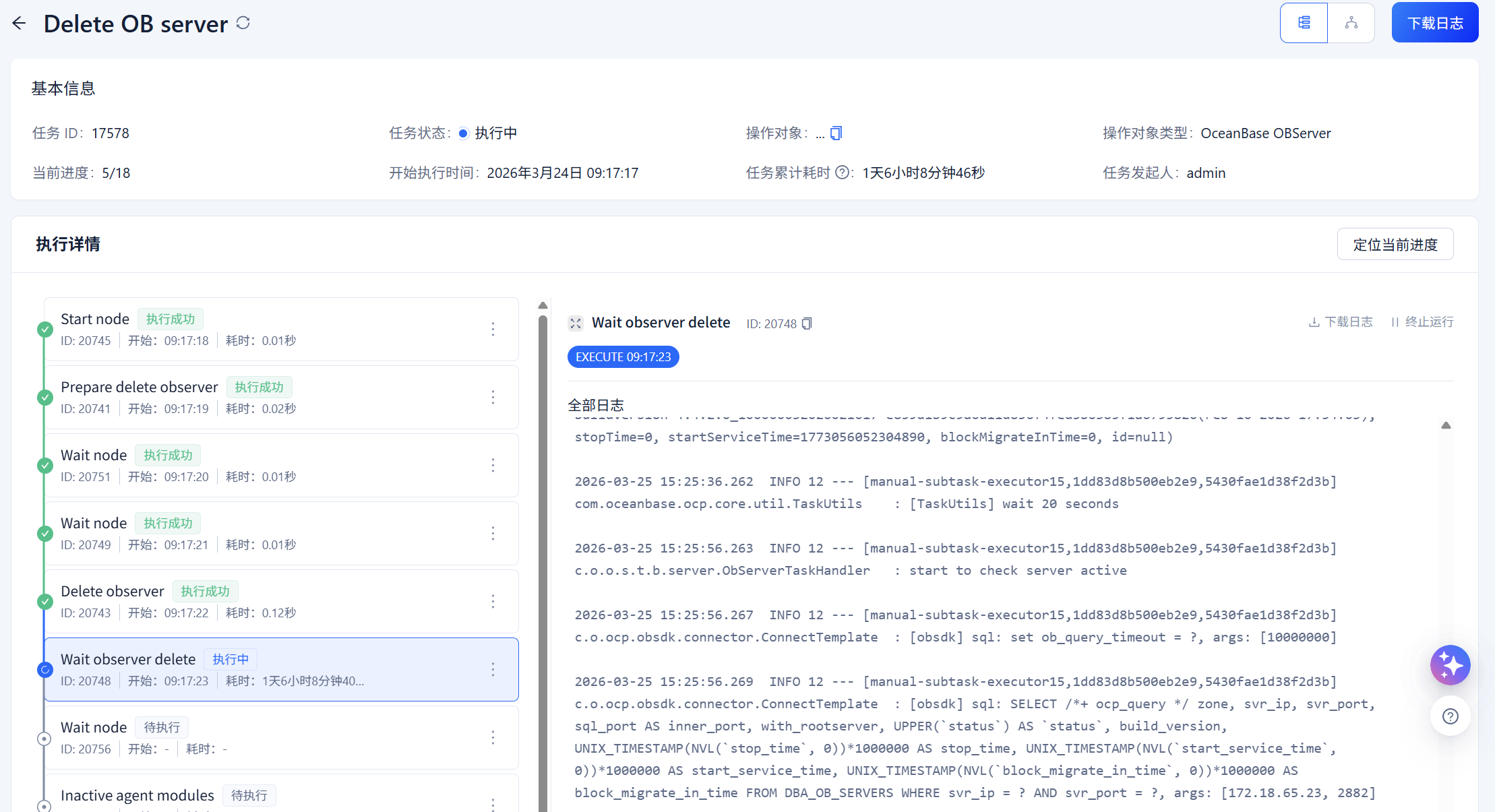
但是,这个任务持续了好久,1天6小时,
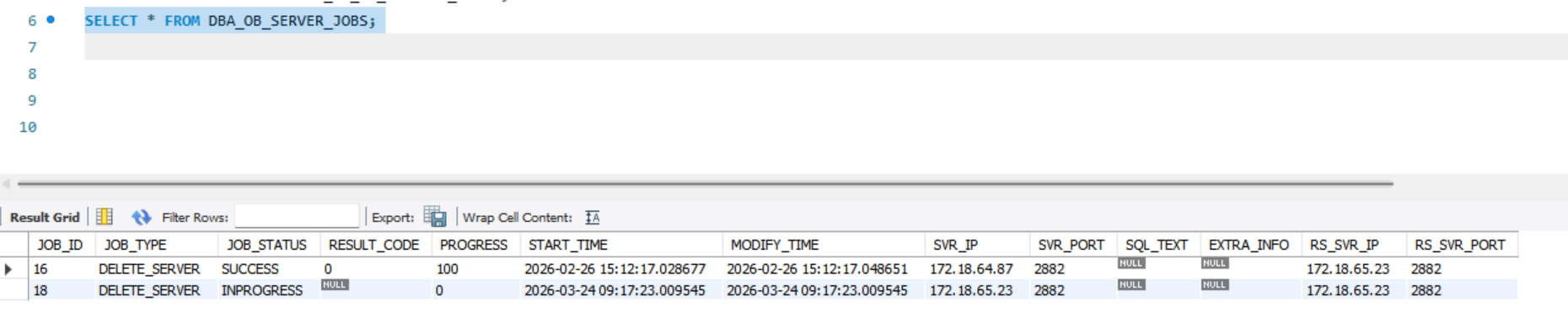
SELECT * FROM DBA_OB_SERVER_JOBS;
oceanbase的作业还在进行中,所以,感觉应该不是OCP的问题。请问,我该如何操作,还是继续等待呢?
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【SOP系列 22 】——故障诊断第一步(自助诊断和诊断信息收集)
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
4 个赞
论坛小助手
#3
推荐使用 obdiag 工具进行日志采集,以便我们可以进一步分析问题。
日志采集场景: 卡合并场景
日志采集命令: obdiag gather scene run --scene=observer.major_hold
请您先执行上述命令,并将采集到的日志提供给我们以便确认问题所在。
另外,为了确定具体的问题,在此需要您提供一些信息:
- 当前集群的状态是什么样的?
- 在执行节点替换之前,是否有过任何异常操作或错误日志?
- 能否提供具体的任务日志或相关错误信息?
- 节点替换任务是否涉及到主备切换或其他关键操作?
- 在等待删除 observer 期间,是否有任何系统资源(如 CPU、内存、磁盘 I/O)出现异常?
谢谢您的配合!
附上敏捷诊断工具 obdiag 使用帮助链接
2 个赞
辞霜
#4
select * from gv$ob_servers;
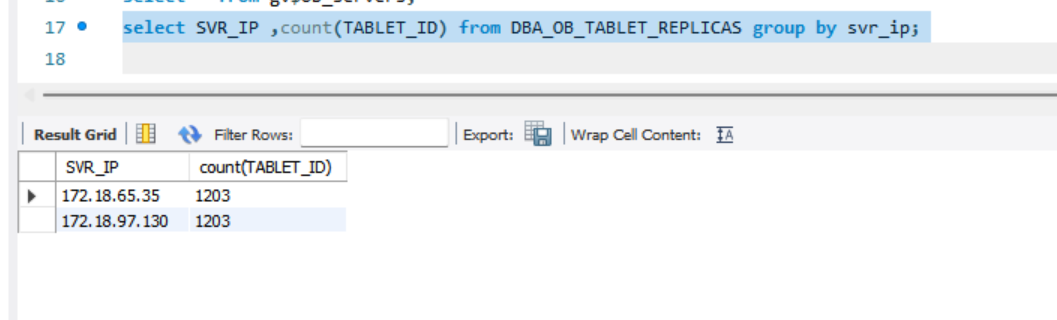
select SVR_IP ,count(TABLET_ID) from DBA_OB_TABLET_REPLICAS group by svr_ip;
1 个赞
1、select * from gv$ob_servers;
2、select SVR_IP ,count(TABLET_ID) from DBA_OB_TABLET_REPLICAS group by svr_ip;
obdiag 还没整,稍等。
老师,
原来是:172.18.65.23
我们计划用:172.18.97.130,这个服务器进行替换。
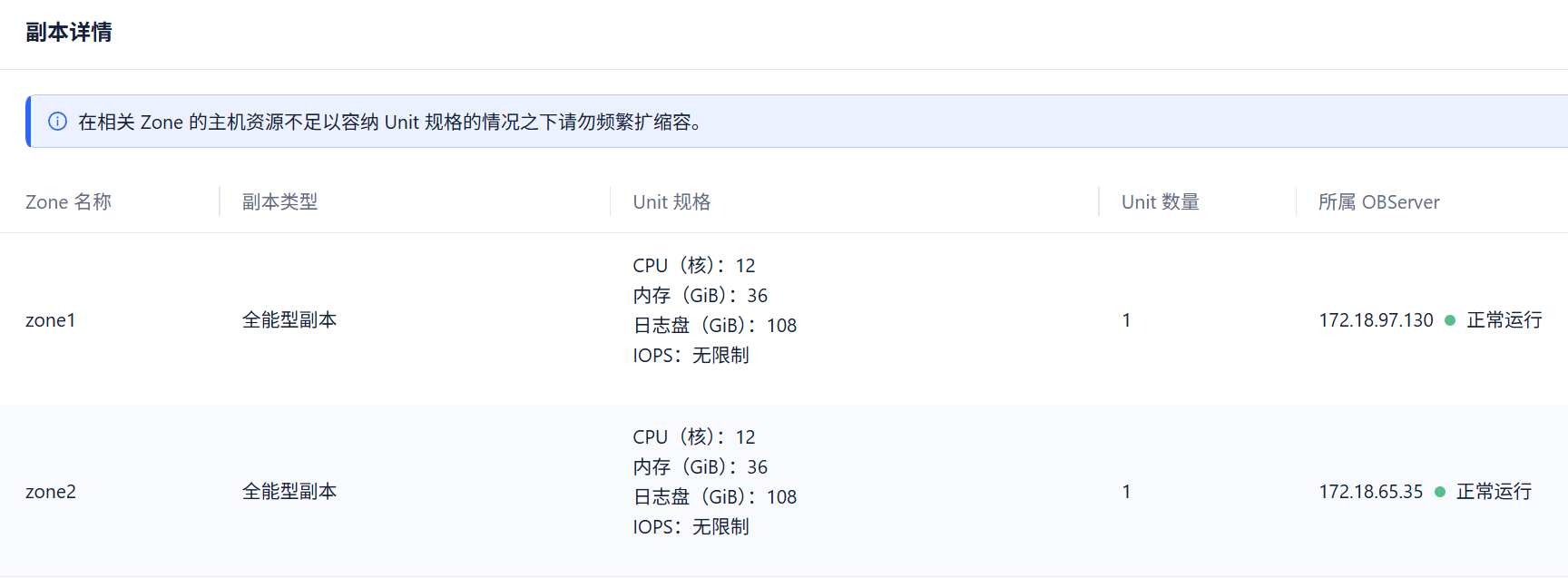
本来是一个3节点的集群,后面删除了zone3。所以,目前这个集群只有,zone1 & zone2
1 个赞
老师,另外,
obdiag rca run --scene=major_hold 的结果如下:
[root@test-all-ob-obproxy-1 obdiag_major_hold_20260325172257]# cat record.table
obdiag version: 4.2.0
observer Version: 4.4.2.0
+-----------------------------------------------------------------------------+
| record |
+------+----------------------------------------------------------------------+
| step | info |
+------+----------------------------------------------------------------------+
| 1 | observer version: 4.4.2.0 |
| 2 | Starting major compaction hold diagnosis... |
| 3 | Step 1: Checking CDB_OB_MAJOR_COMPACTION for errors |
| 4 | No compaction errors found (IS_ERROR='YES') |
| 5 | Step 2: Checking for suspended compactions |
| 6 | No suspended compactions found |
| 7 | Step 3: Checking __all_virtual_compaction_diagnose_info for failures |
| 8 | No failed compaction tasks in diagnose info |
| 9 | Step 4: Checking for long-running compaction tasks (>20 minutes) |
| 10 | No long-running compaction tasks found |
| 11 | Step 5: Analyzing compaction speed |
+------+----------------------------------------------------------------------+
The suggest: No major compaction issues detected
辞霜
#10
查询下面sql
SELECT * FROM oceanbase.DBA_OB_UNIT_JOBS ;
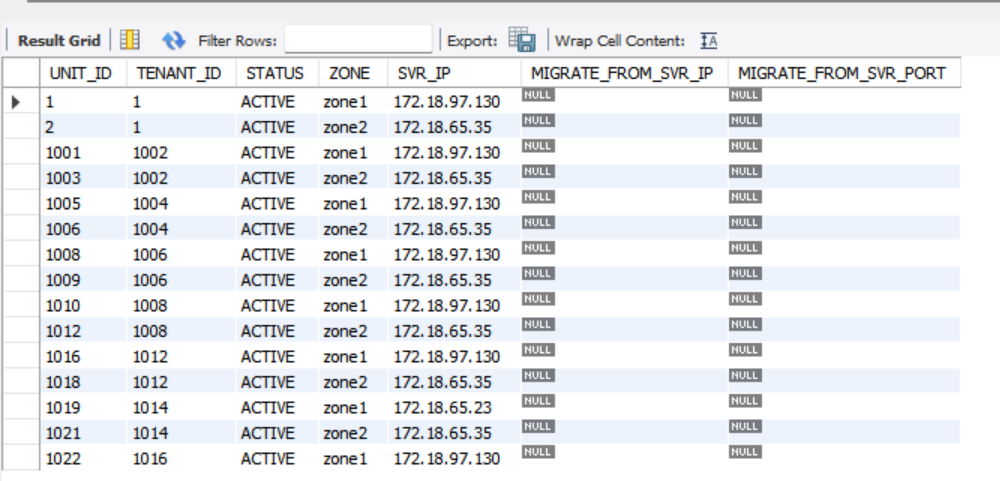
SELECT UNIT_ID, TENANT_ID, STATUS, ZONE, SVR_IP, MIGRATE_FROM_SVR_IP, MIGRATE_FROM_SVR_PORT FROM oceanbase.DBA_OB_UNITS;
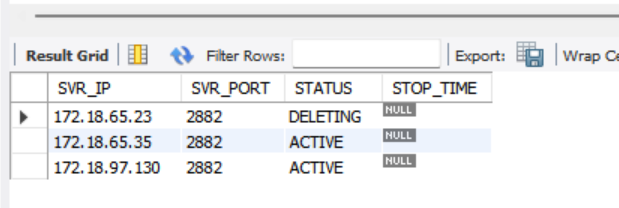
SELECT SVR_IP, SVR_PORT, STATUS, STOP_TIME FROM oceanbase.DBA_OB_SERVERS;
SELECT * FROM oceanbase.DBA_OB_LS_REPLICA_TASKS;
老师,相关结果如下:
1、SELECT * FROM oceanbase.DBA_OB_UNIT_JOBS ;
2、SELECT UNIT_ID, TENANT_ID, STATUS, ZONE, SVR_IP, MIGRATE_FROM_SVR_IP, MIGRATE_FROM_SVR_PORT FROM oceanbase.DBA_OB_UNITS;
3、SELECT SVR_IP, SVR_PORT, STATUS, STOP_TIME FROM oceanbase.DBA_OB_SERVERS;
4、SELECT * FROM oceanbase.DBA_OB_LS_REPLICA_TASKS;
辞霜
#12
SELECT * FROM DBA_OB_SERVER_JOBS;
查询这个看看,任务还在么。看23节点正在执行delete操作
是呢
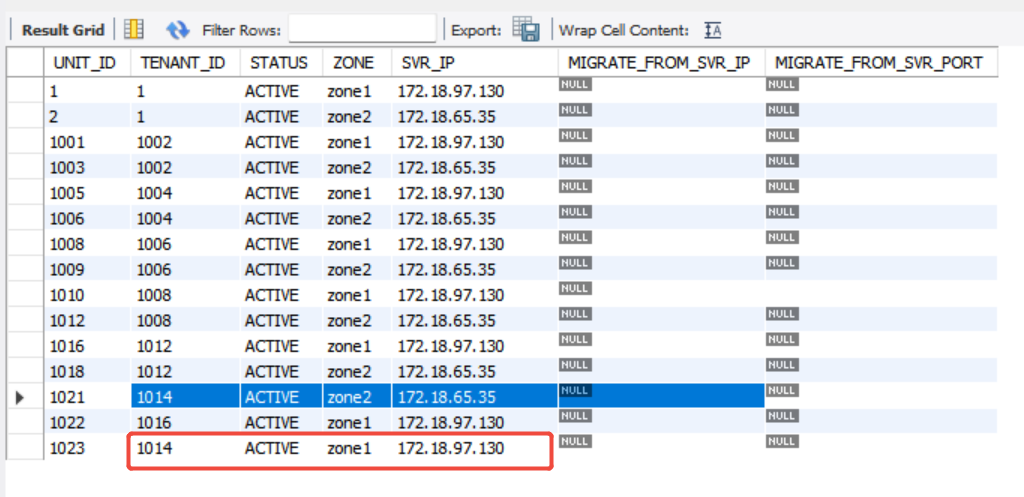
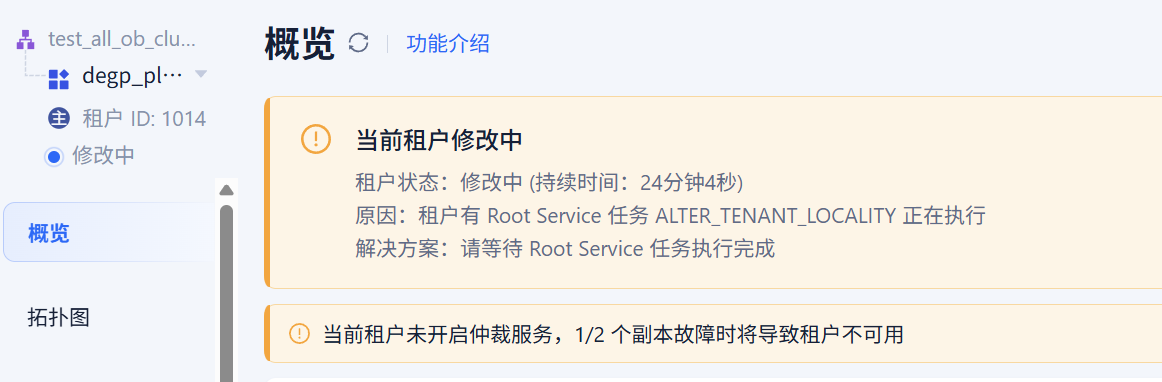
不知道是不是,1014这个租户有点问题。
我看这个租户,还在delete操作的节点
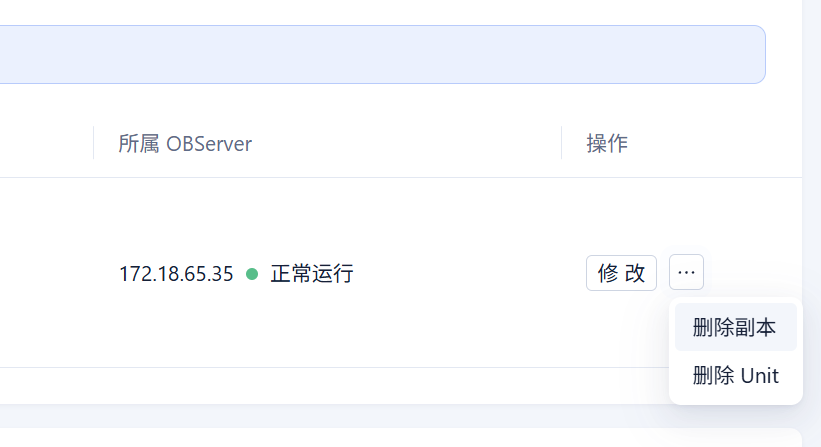
老师,我将租户ID:1014,在zone1,172.18.65.23的副本删除了,任务就可以了。
OCP界面有个删除副本的功能。
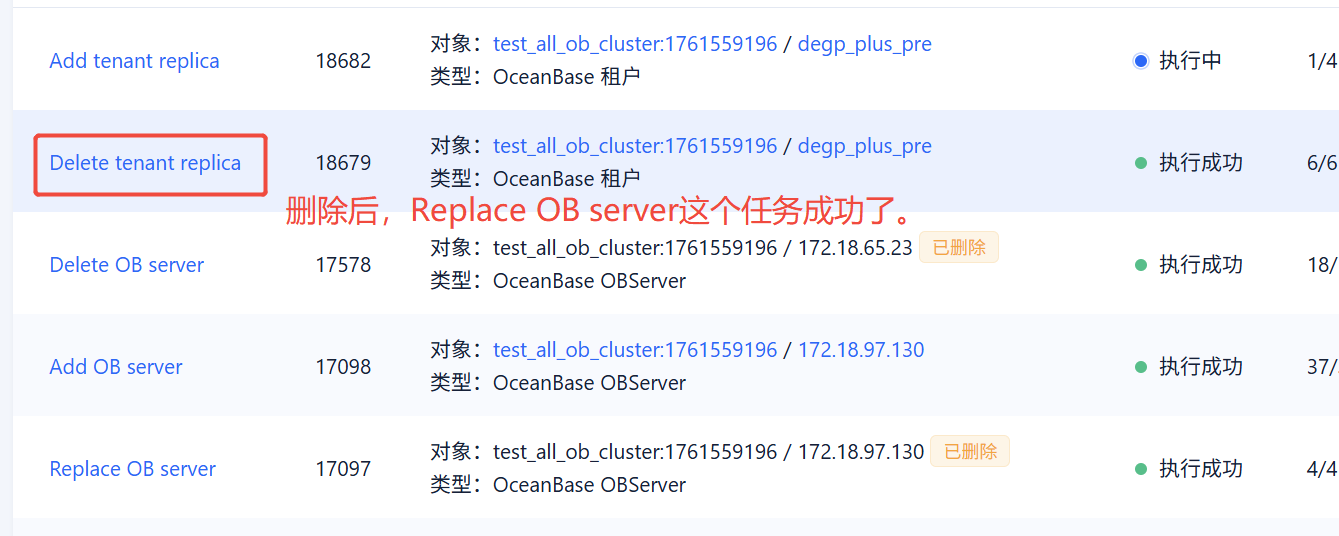
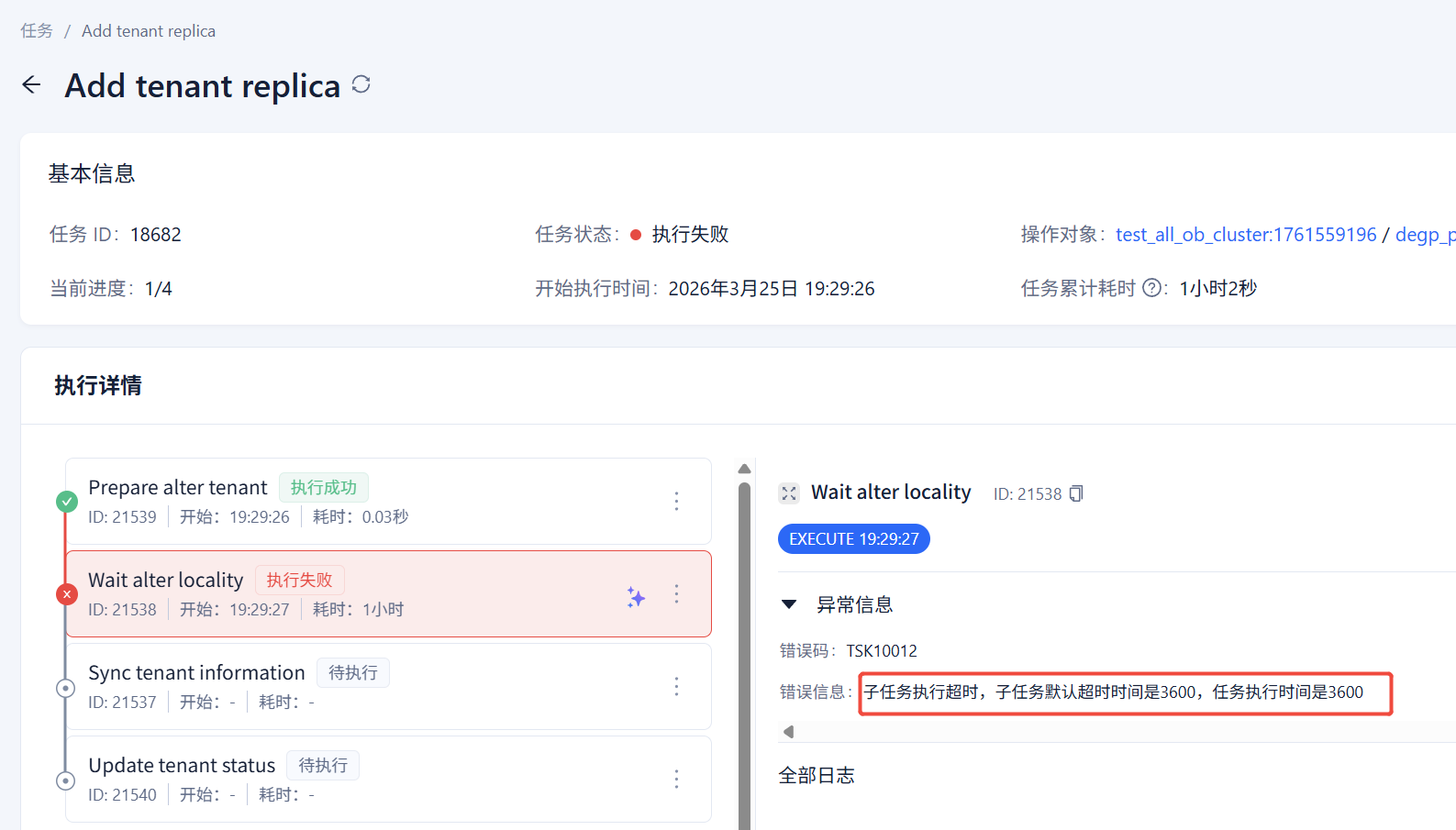
老师,昨晚我尝试用 OCP, 新增副本的形式,再将这个1014租户的副本增加到新节点,结果,OCP报子任务超时了。
但是,我检查oceanbase.DBA_OB_UNITS记录,看到,1014已经添加好了。
SELECT UNIT_ID, TENANT_ID, STATUS, ZONE, SVR_IP, MIGRATE_FROM_SVR_IP, MIGRATE_FROM_SVR_PORT FROM oceanbase.DBA_OB_UNITS;
然后,我在OCP上点击“跳过”这个子任务,任务反馈成功了,目前看应该是正常了。
集群上看,新节点除了数据盘,新节点看着少了一些,好像没什么问题。
辞霜
#16
任务不要随意跳过呀。1014这个租户是一直存在什么问题么
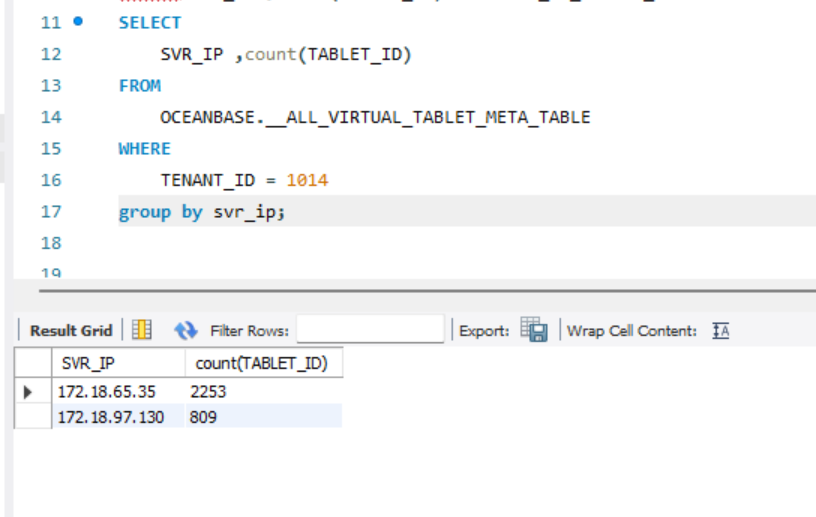
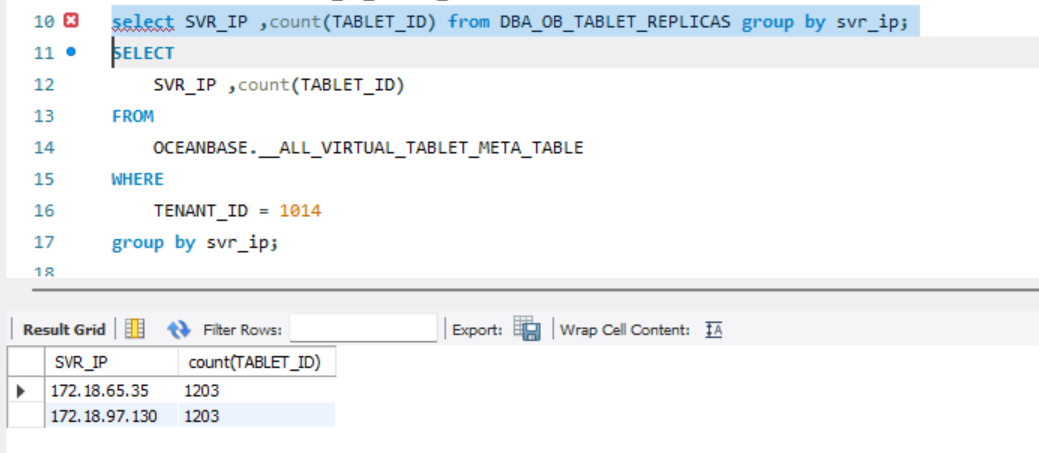
select SVR_IP ,count(TABLET_ID) from DBA_OB_TABLET_REPLICAS where tenant_id=1014 group by svr_ip;
老师,果然,好像确实有点问题。
DBA_OB_TABLET_REPLICAS这个视图似乎没有 tenant id,我用了__ALL_VIRTUAL_TABLET_META_TABLE,
DBA_OB_TABLET_REPLICAS,剔除tenant_id条件,结果是一致的?
辞霜
#18
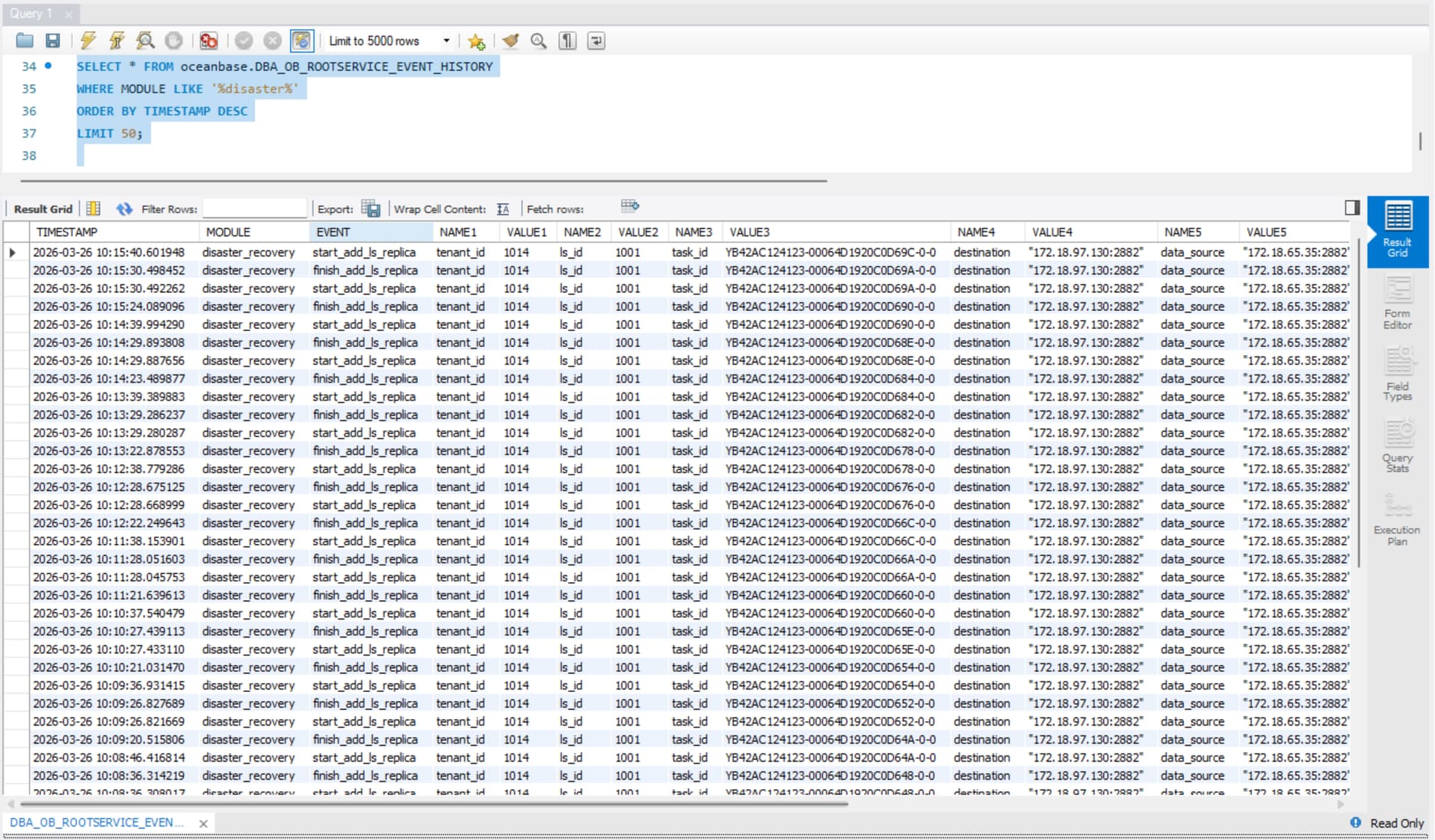
SELECT * FROM oceanbase.DBA_OB_ROOTSERVICE_EVENT_HISTORY
WHERE MODULE LIKE ‘%disaster%’
ORDER BY TIMESTAMP DESC
LIMIT 50;
老师,结果如下:
数据较多,我们导出来了。
export_1.zip (1.3 KB)
辞霜
#20
存在4184问题,磁盘不足。目标节点上可能已经创建了部分/残留的 LS 元信息导致触发死循环
上面ocp截的数据盘图磁盘缺失已经达到90%左右了 这种情况是不推荐进行unit及日志流迁移复制操作的。
还有看了下你的操作流程,执行节点替换操作本就会将23节点副本迁移到130节点,你又执行了依次副本增加到新节点。这里操作应该是无法执行的,130已经存在1014租户副本了,这里在OCP是如何操作的截图看下