【 使用环境 】生产环境 or 测试环境
【 OB or 其他组件 】
【 使用版本 】
【问题描述】清晰明确描述问题
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【SOP系列 22 】——故障诊断第一步(自助诊断和诊断信息收集)
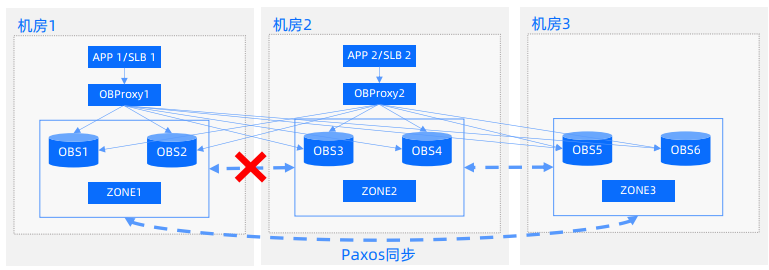
问题:机房1和2出现故障,1,2和3都正常,会出现什么情况??
【 使用环境 】生产环境 or 测试环境
【 OB or 其他组件 】
【 使用版本 】
【问题描述】清晰明确描述问题
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【SOP系列 22 】——故障诊断第一步(自助诊断和诊断信息收集)
问题:机房1和2出现故障,1,2和3都正常,会出现什么情况??
这种情况不会存在脑裂情况。
这种情况所有节点都正常工作吗??
可以正常工作,但是zone1 2之间的follow副本可能会出现数据异常。
sys的 rs服务 仅仅是一个日志流, 如果这个日志流的leader在 1上, 会不会把 机房2的所有机器 标记为不可用状态,从而导致 机房2的所有 observer不可用呢 ??
会,rs 在 z1,收不到 z2 所有机器的心跳,一段时间后会永久下线掉zone2机器
一致性问题可能会存在吧
那样的话,是不是虽然集群可以正常工作,但是机房2的zone就会被下线掉,也会导致机房2的所有leader发生切换。
超过时间限制可能会永久下线
时间长有多长? 那个参数控制了?
zone2的leader副本在这期间能还会提供服务,超过永久下线后zone2会被RS永久下线掉.
不存在脑裂问题,zone2 上的 leader 可以和 zone3 连通,还是多数派
如果 机房3 仅仅是 仲裁节点, 等到 server_permanent_offline_time 后,还能正常工作不??
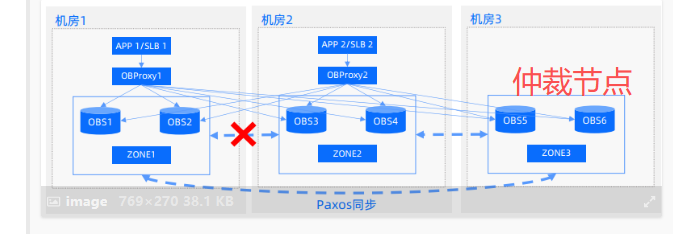
1和2链路中断,2收不到日志流吧,时间长了会下线?
涉及zone1 2的分布式事务肯定是无法执行的。协调节点会将子计划分发到各参与者
我的意思是: 机房3是仲裁节点。 当机房1 和机房2 网络断开,机房1和机房2 和机房3的网络是正常的。 rs在机房1 当机房2超过server_permanent_off_time时下线。 这个集群还能提供正常服务不?
可以
总结如下: