不会写SQL
#1
【 使用环境 】测试环境
【 OB or 其他组件 】observer
【 使用版本 】4.3.3
【问题描述】测试环境有1-1-1的集群,clog和data共用一块盘,现在有2个节点的data盘占用100%,如何在不扩容的情况下,手动清除一部分clog而不影响集群正常运行。
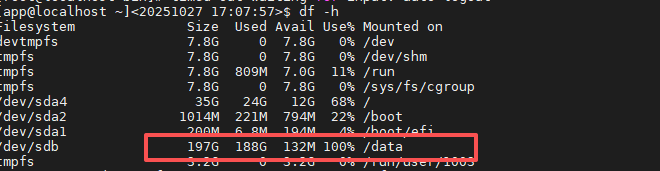
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【SOP系列 22 】——故障诊断第一步(自助诊断和诊断信息收集)
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
2 个赞
论坛小助手
#3
根据您的描述,您当前面临的问题是 clog 盘满,即 OceanBase 4.3.3 版本测试环境中,1-1-1 集群的两个节点的 data 盘占用 100%。这种情况会导致系统无法正常运行,因为 clog 和 data 共用同一块磁盘。为了帮助您解决问题,我建议首先使用 obdiag 工具进行日志采集,以便我们了解具体情况。
日志采集场景: clog盘满
日志采集命令:
obdiag gather scene run --scene=observer.clog_disk_full
这个命令会收集与 clog 磁盘空间相关的信息,包括但不限于 clog 文件的大小、分布情况等。请执行上述命令,并将生成的日志文件压缩包提供给我们,这将有助于我们进一步分析问题。
为了更有效地解决您的问题,请您回答以下问题:
- 您是否有定期清理 clog 的策略或计划?
- 最近是否执行了大量写操作或大事务,导致 clog 快速增长?
- 当前集群的租户配置中,是否有设置
__all_zone_clog_disk_usage_limit_ratio 参数?如果有,其值是多少?
- 您是否尝试过手动删除 clog 文件?如果有,具体操作步骤是什么?
- 集群中是否有其他异常日志或告警信息?
这些信息将帮助我们更准确地定位问题并提供解决方案。如果您有任何疑问或需要进一步的帮助,请随时告知。
附上敏捷诊断工具 obdiag 使用帮助链接
1 个赞
淇铭
#4
看着是磁盘空间满了 目前ob集群有问题么?还能查看信息么?
1 个赞
有没有指定OBServer的运行日志保留期限,可以删一删运行日志
cwa
#9
为啥会满呢,ob不应该是先划90%空间出来然后自己用么
淇铭
#11
应该刚搭建的集群的时候 日志和数据文件设置的有点大 如果能登陆的话 还可以操作一下 运行日志也不在这个盘上 估计要重新搭建了

