【 使用环境 】测试环境
【 OB or 其他组件 】OceanBase 4.2.1.7
【问题描述】清晰明确描述问题
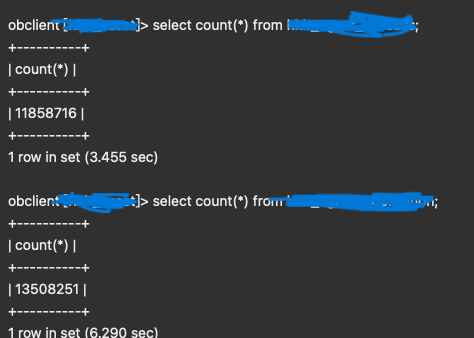
测试环境某一个表里面有千万级数据,执行select count(*) from xxx;查总数需要6秒钟,这个是为什么
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
【 使用环境 】测试环境
【 OB or 其他组件 】OceanBase 4.2.1.7
【问题描述】清晰明确描述问题
测试环境某一个表里面有千万级数据,执行select count(*) from xxx;查总数需要6秒钟,这个是为什么
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
推荐使用 obdiag 工具进行根因分析和日志采集,以便确认问题所在。
根因分析场景: SQL性能问题
根因分析命令: obdiag rca run --scene=sql_perf --env “{db_connect=’-h127.0.0.1 -P2881 -utest@test -p****** -Dtest’, sql=‘select count(*) from xxx;’}”
日志采集场景: SQL性能问题
日志采集命令: obdiag gather scene run --scene=observer.perf_sql --env “{db_connect=’-h127.0.0.1 -P2881 -utest@test -p****** -Dtest’, trace_id=‘Yxx’}”
请使用上述命令进行日志采集和根因分析,并将采集到的日志提供给我们以便确认问题所在。此外,为了更好地帮助您定位问题,请提供以下信息:
感谢您的配合!
附上敏捷诊断工具 obdiag 使用帮助链接
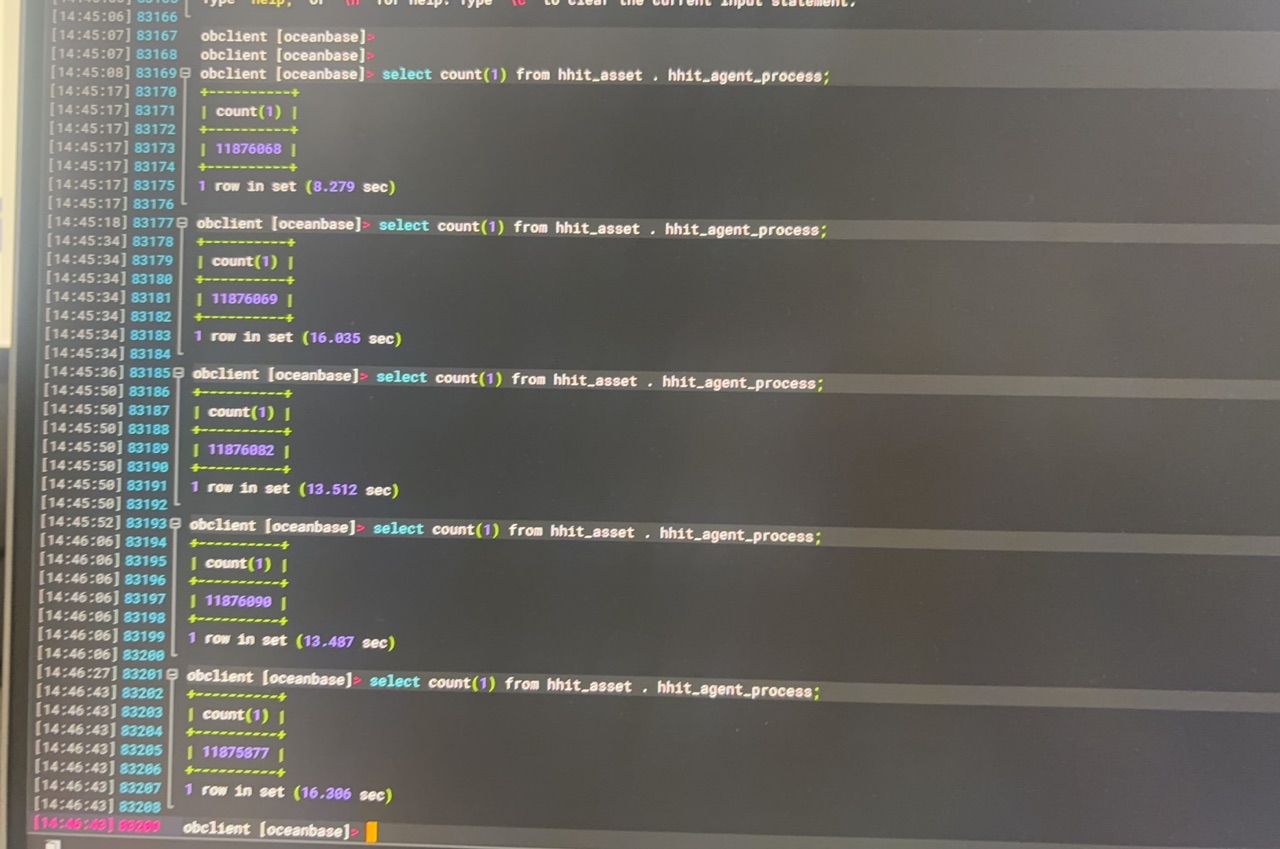
试试 count(1)
obclient [oceanbase]> select count(1) from xxx. xxx;
±---------+
| count(1) |
±---------+
| 11876054 |
±---------+
1 row in set (7.456 sec)
obclient [oceanbase]> select count(1) from xxx. xxx;
±---------+
| count(1) |
±---------+
| 13510094 |
±---------+
1 row in set (9.264 sec)
这种慢一般就是正常情况了。有试过多次执行么,第一次需要硬解析是会慢一点。
学习
正常现象吧,毕竟数据量这么大,需要全部扫描一遍