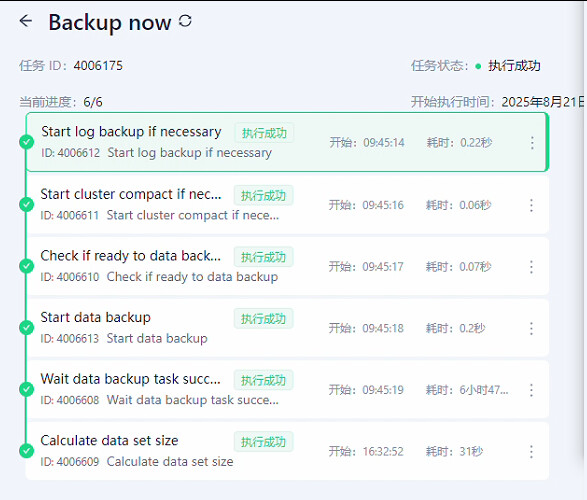
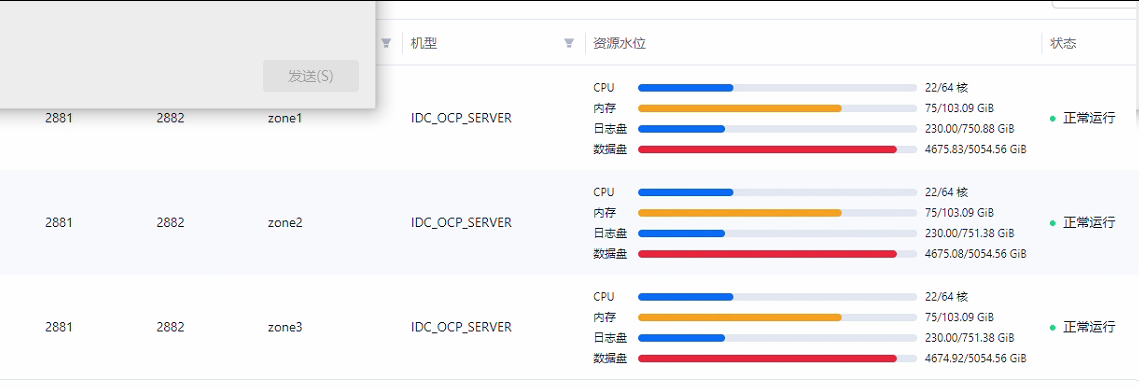
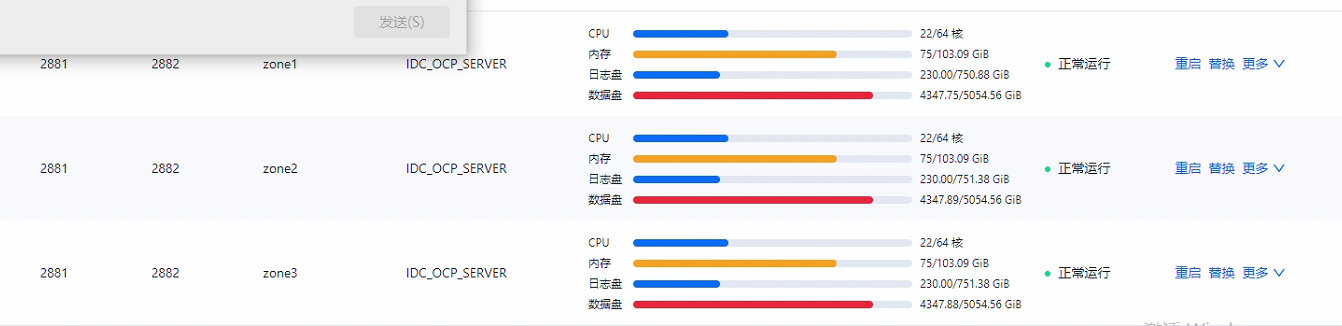
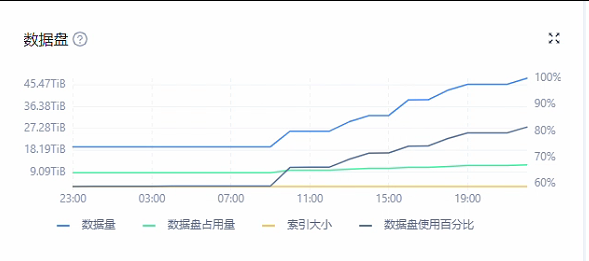
select * from oceanbase.CDB_OB_SPACE_USAGE order by USAGE_BYTES desc;
select * from oceanbase.CDB_OB_SERVER_SPACE_USAGE order by USAGE_BYTES desc;
select * from oceanbase.CDB_OB_TABLE_SPACE_USAGE order by REQUIRED_SIZE desc limit 50;
修改参数 : alter table $tablename set progressive_merge_num = 1, 然后执行 alter system major freeze,合并结束后,设置 alter table $tablename set progressive_merge_num = 0(以上操作仅针对磁盘放大严重的表)。数据重整后,磁盘空间释放。