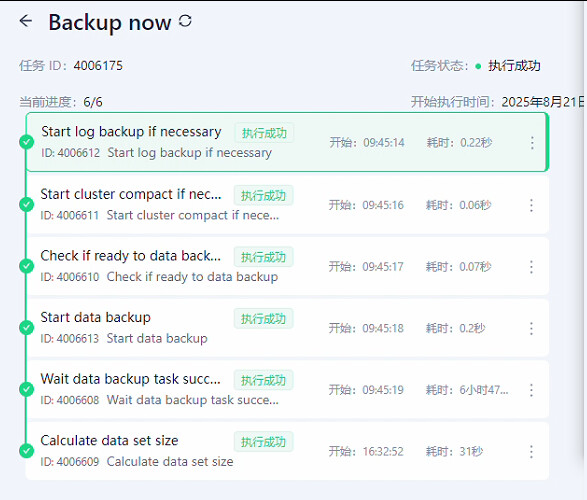
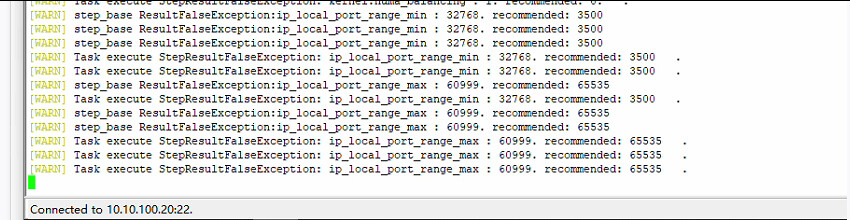
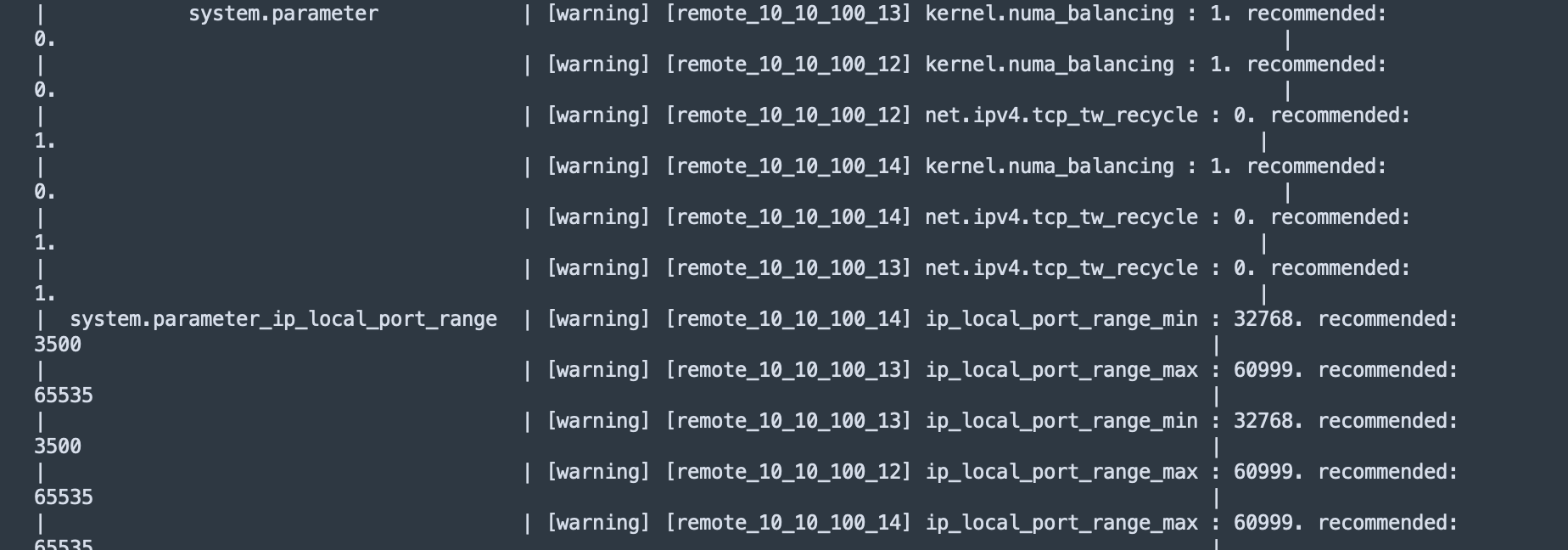
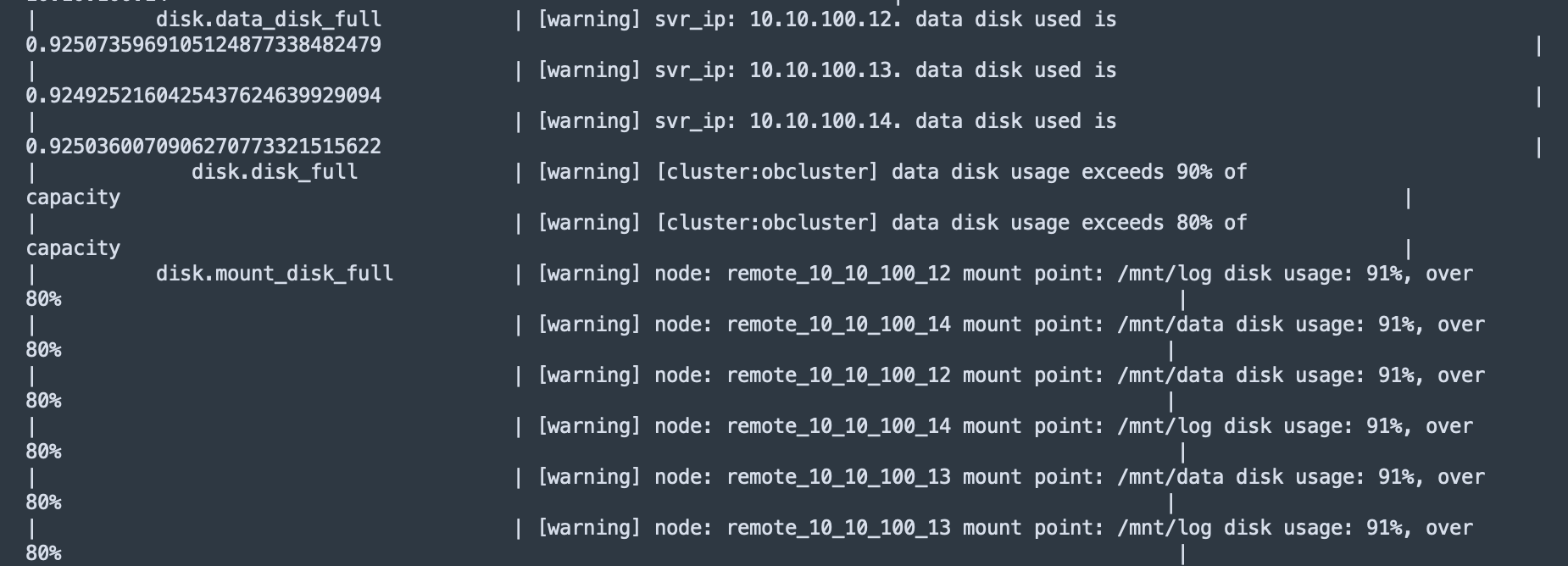
cluster.core_file_find | [critical] [remote_10_10_100_12] The core file exists.
12这台机器上有core文件,可以确认下是否为OB的core,如果是OB的core 这个OB实例大概宕过,需要取下当时的日志以及解析下core文件
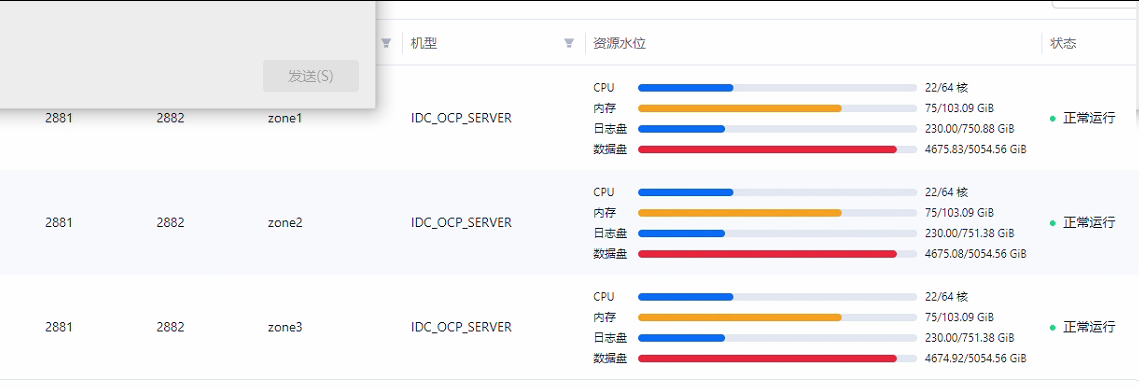
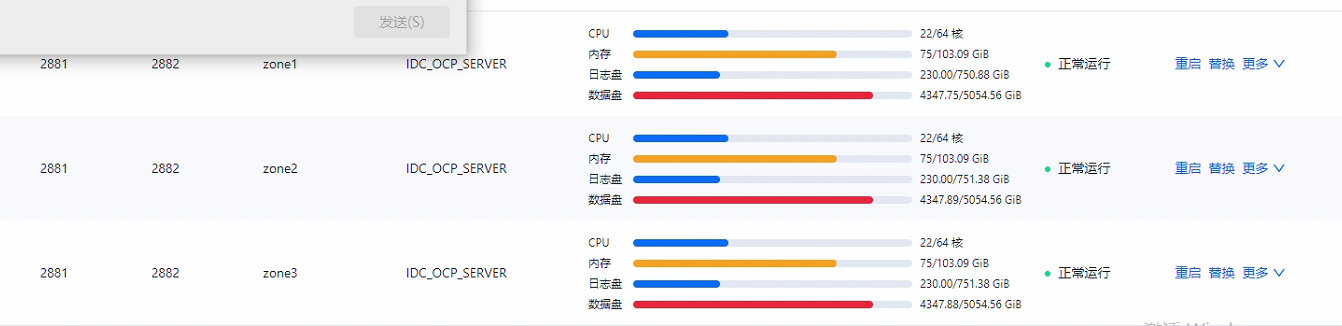
需要在这个在这三台机器执行 ip -s link show em1 看下
| network.network_drop | [critical] [remote_10_10_100_12] network: em1 RX drop is not 0, please check by ip -s link show em1 |
| | [critical] [remote_10_10_100_14] network: em1 RX drop is not 0, please check by ip -s link show em1 |
| | [critical] [remote_10_10_100_13] network: em1 RX drop is not 0, please check by ip -s link show em1 |
| system.kernel_bad_version | [critical] node: remote_10_10_100_12 kernel version is 3.10.0-1160.119.1.el7.x86_64, There is a risk of system downtime when deploying OBServer using cgroup method on an operating system with kernel version 3.10 issue #910 |
| | [critical] node: remote_10_10_100_14 kernel version is 3.10.0-1160.119.1.el7.x86_64, There is a risk of system downtime when deploying OBServer using cgroup method on an operating system with kernel version 3.10 issue #910 |
| | [critical] node: remote_10_10_100_13 kernel version is 3.10.0-1160.119.1.el7.x86_64, There is a risk of system downtime when deploying OBServer using cgroup method on an operating system with kernel version 3.10 issue #910 |