朝暾
#1
【 使用环境 】测试环境
【 OB or 其他组件 】observer4.2.5.2
【 使用版本 】
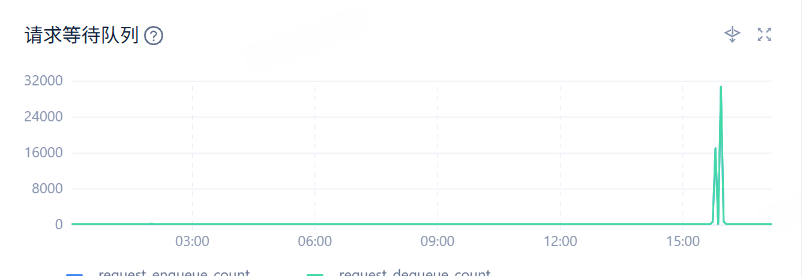
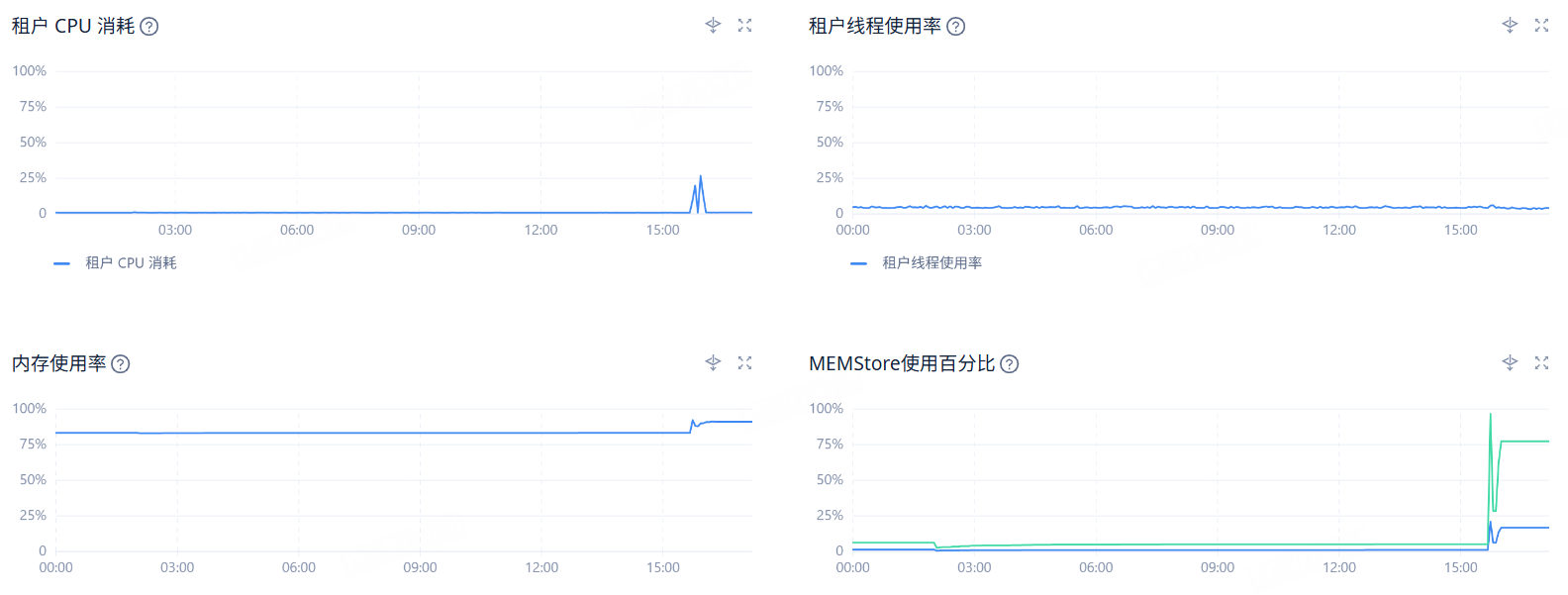
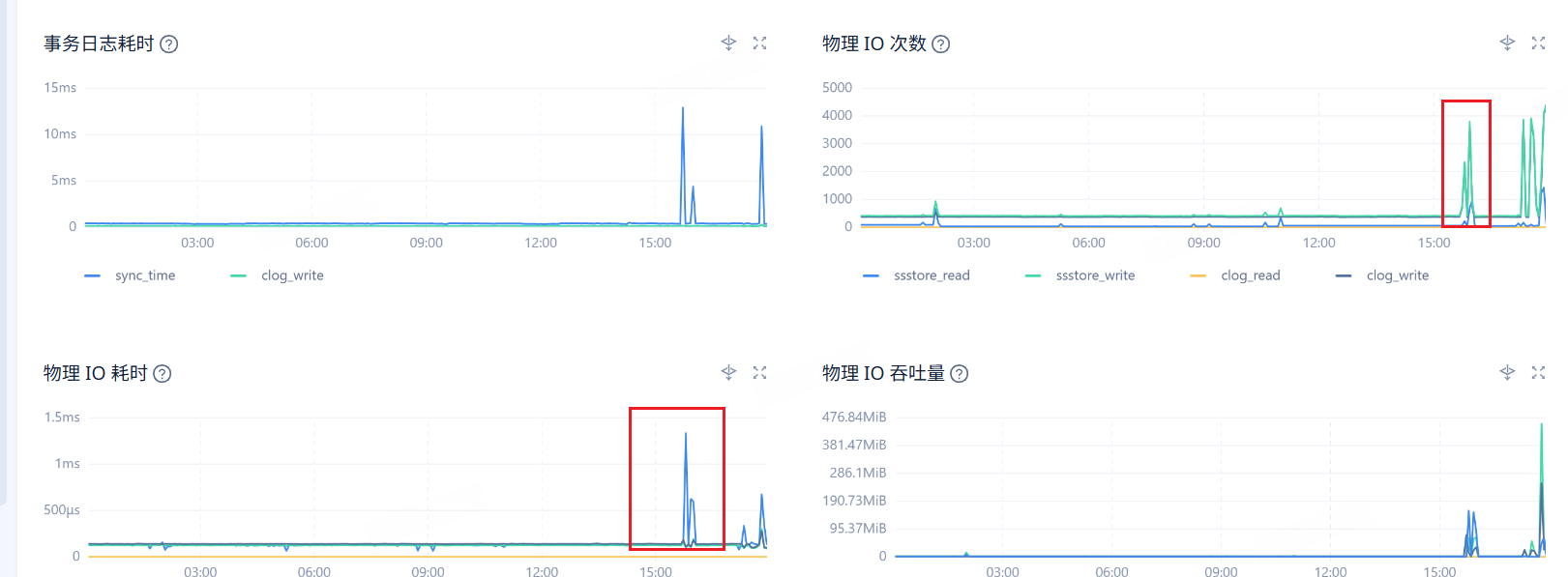
【问题描述】MySQL模式租户规格为16C/32G,使用sysbench对oceanbase租户进行压测时,发现cpu/内存未达到瓶颈,查看ocp界面性能你监控,memstore使用百分比,请求等待队列值较大,是否有对应的参数可优化?
memory_limit_percentage这些是跟内存相关的,内存应该不是瓶颈。
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【SOP系列 22 】——故障诊断第一步(自助诊断和诊断信息收集)
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
1 个赞
论坛小助手
#3
推荐使用 obdiag 工具进行日志采集,以便确认具体的问题所在,并且将采集到的日志提供给我们以便进一步分析。
日志采集场景: 内存问题
日志采集命令: obdiag gather scene run --scene=observer.memory
另外,为了确定具体的问题,在此需要您提供一些信息:
- 当前租户的配置参数是什么样的?特别是与内存管理相关的参数设置,例如
memstore_limit_percentage 和 minor_freeze_times。
- 在压测过程中,memstore 使用率最高达到了多少?请求等待队列的最大值是多少?
- 压测的具体脚本或命令是什么?包括所使用的 sysbench 测试模型、数据量大小等信息。
- 除 memstore 使用率高和请求等待队列值大之外,是否还有其他异常表现?例如响应时间、吞吐量等性能指标的变化。
- 是否尝试过调整相关参数来观察其对性能的影响?如果有,请详细说明调整的内容及结果。
- 该测试环境中的硬件配置如何?例如服务器型号、网络带宽等。
附上敏捷诊断工具 obdiag 使用帮助链接
辞霜
#4
队列高可能是场景耗cpu,线程处理慢导致。并无参数优化,但是可以调大队列最大值 受集群级 配置项tenant_task_queue_size 控制。当前默认1.6w
朝暾
#7
就是目前使用sysbench压测,目前看监控cpu使用率不高,队列等待较高,想着能不能调整对应参数能让cpu等资源充分利用,然后压测qps结果值能更好
靖顺
#9
这种情况用诊断工具obdiag巡检一下
执行 sysbench 时的巡检任务集合
obdiag check run --cases=sysbench_run
文档:https://www.oceanbase.com/docs/common-obdiag-cn-1000000003242092
1 个赞
辞霜
#14
你好obdiag收集一下信息麻烦发出来一份看看。并使用sar 观察一下集群磁盘情况
朝暾
#17
解决了,瓶颈不在oceanbaase侧,在前端lb侧,调整后可以了,谢谢大佬