【 使用环境 】生产环境
【 OB or 其他组件 】OMS
【 使用版本 】4.2.8_CE
【问题描述】
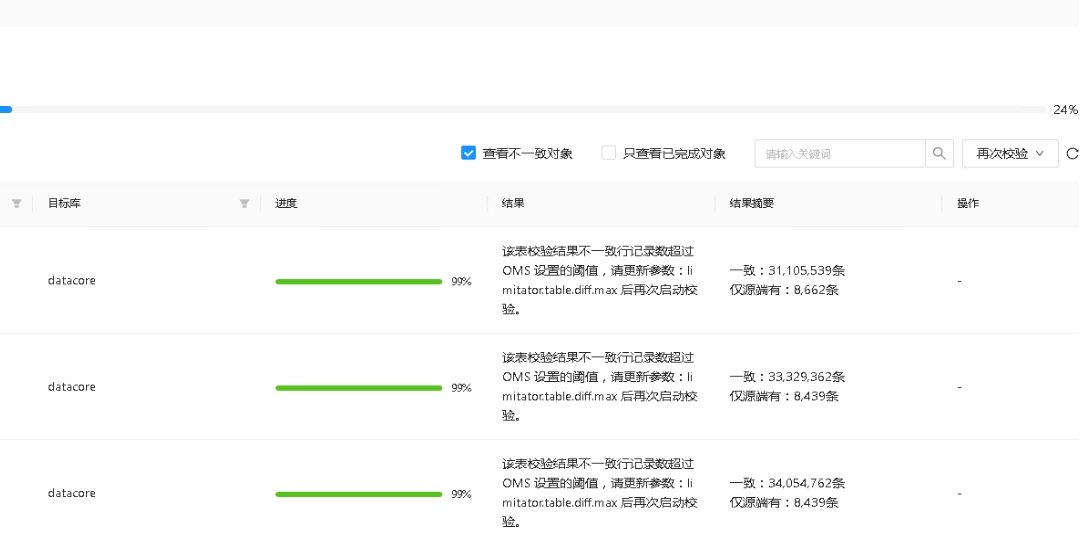
全量校验,校验不通过。如图。
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
【 使用环境 】生产环境
【 OB or 其他组件 】OMS
【 使用版本 】4.2.8_CE
【问题描述】
全量校验,校验不通过。如图。
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
根据您提供的信息和文档库中的内容,以下是对 OMS 全量校验报错问题的分析与解决建议:
从您上传的图片和 OCR 提取的内容来看,OMS 在执行全量校验时出现了不通过的情况。具体表现为某些表的数据差异较大(如 mitatortable.diffmax),并且可能存在数据行数或值的不一致。
结合文档片段 3 和文档片段 7 的内容,OMS 社区版在发生报错时,需要按照以下步骤进行排查:
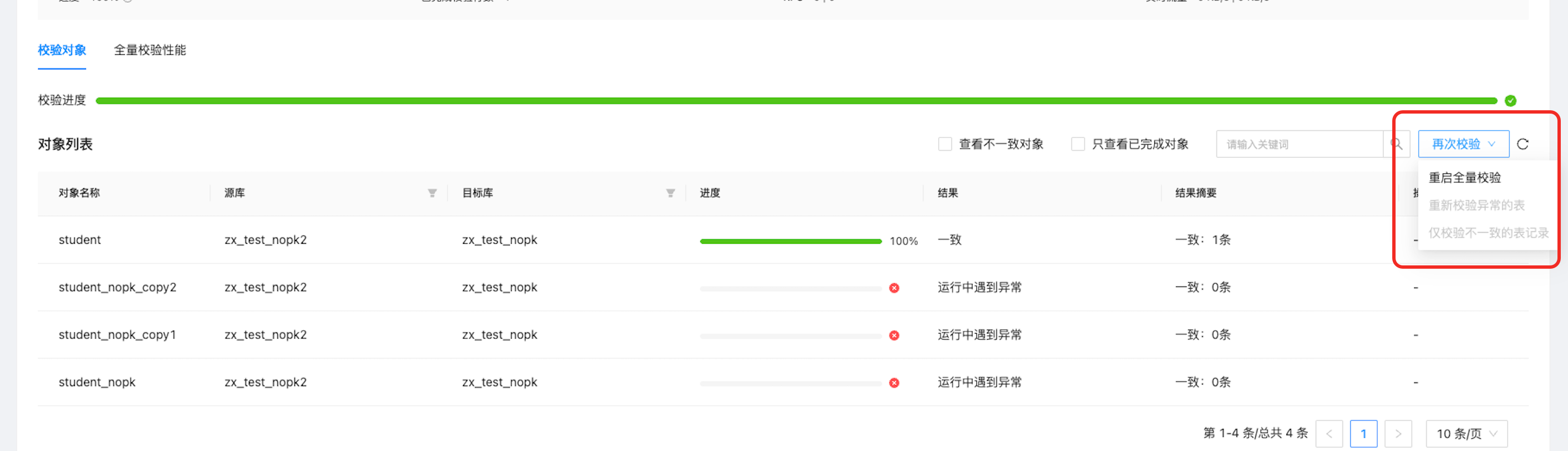
此外,文档片段 2 提到,对于处于已进入全量校验阶段但未执行成功的任务,可以尝试 批量跳过全量校验 操作。但这仅适用于部分场景,且需要谨慎操作。
obdiag 收集诊断信息,具体命令如下:obdiag collect log --start-time "YYYY-MM-DD HH:MM:SS" --end-time "YYYY-MM-DD HH:MM:SS" -o /path/to/output
YYYY-MM-DD HH:MM:SS 为任务运行的时间范围,并将输出路径替换为实际路径。datacoremitatortable.diffmaxdiff max根据 OCR 提取的内容,mitatortable 表存在较大的数据差异。可以通过以下 SQL 查询进一步确认:
-- 比较源端和目标端的数据行数
SELECT COUNT(*) FROM source_database.mitatortable;
SELECT COUNT(*) FROM target_database.mitatortable;
-- 比较关键字段的值
SELECT column_name, COUNT(*)
FROM source_database.mitatortable
GROUP BY column_name
ORDER BY COUNT(*) DESC;
SELECT column_name, COUNT(*)
FROM target_database.mitatortable
GROUP BY column_name
ORDER BY COUNT(*) DESC;
如果发现数据确实不一致,可能的原因包括:
如果确认数据差异不影响业务逻辑,可以尝试跳过全量校验:
注意:跳过全量校验可能会导致数据一致性问题,请务必确认差异对业务无影响后再执行此操作。
obdiag 收集的日志文件。根据文档库中的信息,OMS 全量校验报错通常由任务配置错误、数据差异或权限问题引起。建议按照上述步骤逐一排查,并根据实际情况决定是否跳过全量校验。如果仍有疑问,请提供更多详细信息以便进一步分析。
具体信息可参考以下文档:
你那是不一致的太多了,超过参数设置的不一致的值了
解决办法,更改OMS的参数,改大,太多不一样的话,还是处理数据吧
已经找到在Full-Verification里面对应参数修改成100000.
当前场景是tidb 4.0.15 同步到 ob 4.3.5.1。oms版本是4.2.8_CE。未使用cdc-kafka方式进行增量同步。
表大概600个左右。
数据总行数在200亿左右.
目前遇到问题如下。
1.全量迁移完成后存在大量不一致。
(疑问:全量迁移是有依据数据快照吗?全量迁移完成后如何接上增量同步)
2.大量不一致的情况下,需要大量表进行订正。是否有批量订正功能。
3.store组件,会偶尔出现延迟情况,需要重启才能再进行拉取同步
根据您提供的信息和文档库中的内容,以下是对问题的详细分析与解答:
全量迁移是否基于数据快照?
tidb_snapshot)来确保全量迁移过程中读取的数据是一致的。全量迁移完成后如何接上增量同步?
OMS 是否支持批量订正功能?
Full-Verification 的校验阈值调高(如您提到的修改为 100000),以减少校验失败的任务数量。具体操作步骤:
后续处理:
-- 比较源端和目标端的数据行数
SELECT COUNT(*) FROM source_database.table_name;
SELECT COUNT(*) FROM target_database.table_name;
-- 比较关键字段的值
SELECT column_name, COUNT(*)
FROM source_database.table_name
GROUP BY column_name
ORDER BY COUNT(*) DESC;
SELECT column_name, COUNT(*)
FROM target_database.table_name
GROUP BY column_name
ORDER BY COUNT(*) DESC;
可能原因:
解决方法:
检查时钟同步:
ntpstat
ntpdate 或 chrony 进行同步。优化 Store 组件性能:
source.workerNum 和 sink.workerNum,通常与机器 CPU 核数相关。coordinator.connectorJvmParam 参数,例如:coordinator.connectorJvmParam=-Xms8g -Xmx8g -Xmn4g
source.sliceBatchSize 参数,例如:source.sliceBatchSize=10000
监控资源使用情况:
避免频繁重启:
如果仍有疑问,请提供更多详细信息(如具体的错误日志或任务配置),以便进一步分析。
更多信息请查看:
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)