【 使用环境 】生产环境
【 OB or 其他组件 】ob
【 使用版本 】4.3.5.0
【问题描述】sql where 条件包含in值过长,导致解析时间过长
【复现路径】问题出现前后相关操作
【附件及日志】
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
【 使用环境 】生产环境
【 OB or 其他组件 】ob
【 使用版本 】4.3.5.0
【问题描述】sql where 条件包含in值过长,导致解析时间过长
【复现路径】问题出现前后相关操作
【附件及日志】
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
根因分析场景: SQL性能问题
根因分析命令: obdiag rca run --scene=sql_performance_issue
日志采集场景: SQL性能问题
日志采集命令: obdiag gather scene run --scene=observer.perf_sql --env “{db_connect=’-h127.0.0.1 -P2881 -utest@test -p****** -Dtest’, trace_id=‘Yxx’}”
为了更好地帮助您解决 SQL 性能问题,请您按照上述命令进行日志采集,并将生成的日志压缩包提供给我们。同时,为了更精准地定位问题,请您回答以下问题:
附上敏捷诊断工具 obdiag 使用帮助链接
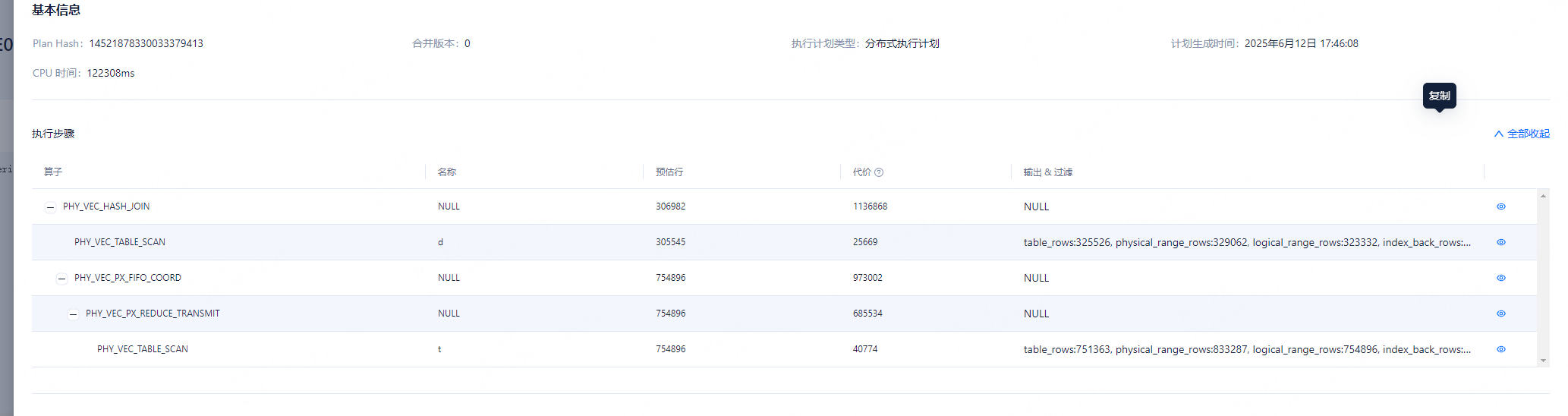
根据您提供的信息和图片内容,SQL 的执行计划显示了性能瓶颈可能与 IN 条件中的值过多有关。以下是一些分析和建议:
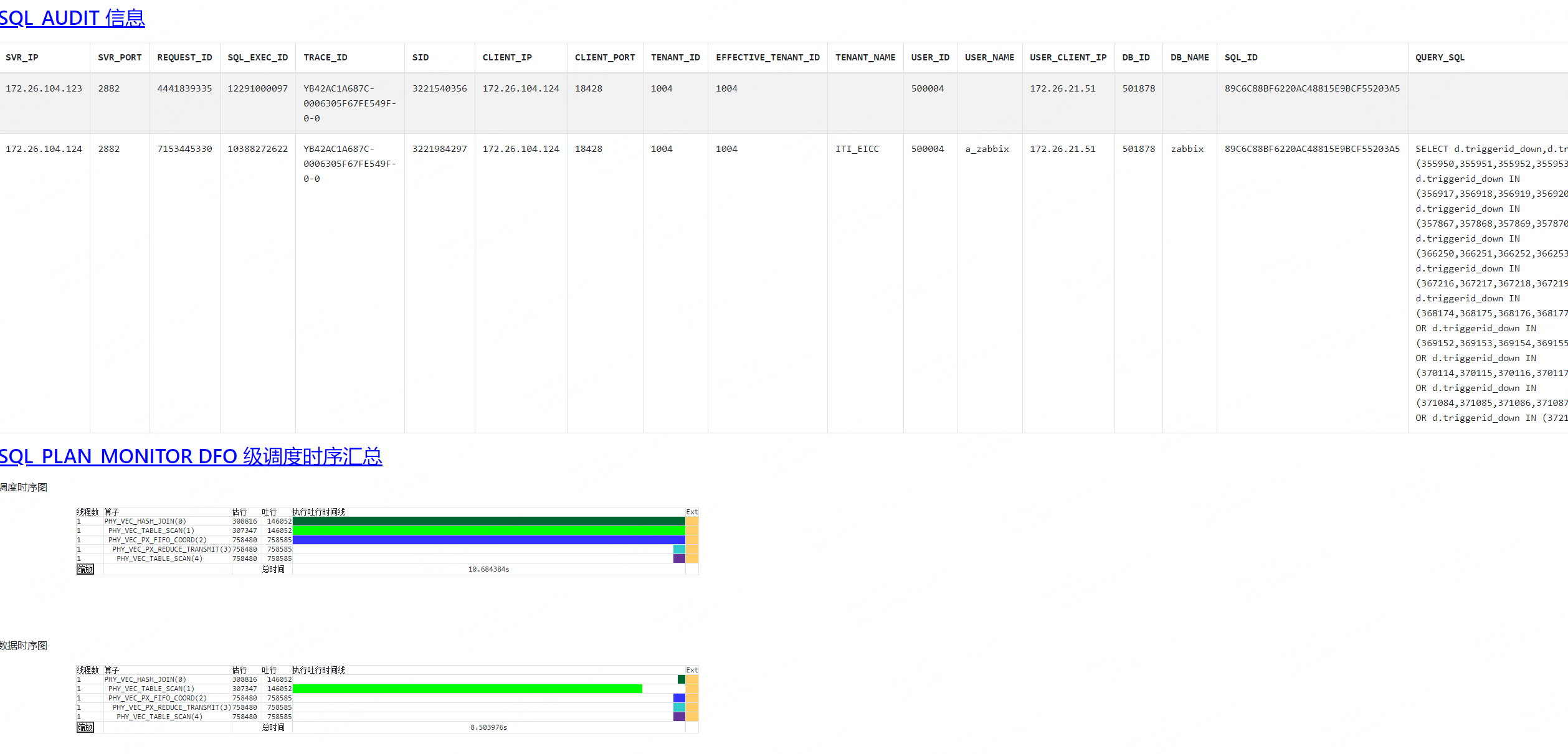
SQL 执行计划:
PHY_VEC_TABLE SCAN 是主要的执行步骤,且涉及大量数据扫描。table_rows 和 physical_range_rows 的值较大,表明查询需要扫描大量数据。CPU 消耗高:
CPU BYE 时间为 122308ms,说明 CPU 在处理该 SQL 时消耗了较多时间。IN 条件中的值过多,导致解析和匹配过程复杂度增加。IN 条件的影响:
IN 条件中的值列表过长时,数据库需要逐一匹配这些值,可能导致解析时间和执行时间显著增加。IN 列表中的值没有索引支持,可能会导致全表扫描,进一步降低性能。拆分 IN 值列表:
将长的 IN 条件拆分为多个小批次,分别执行查询。例如:
-- 原始 SQL
SELECT * FROM table_name WHERE column_name IN (value1, value2, ..., valueN);
-- 拆分后
SELECT * FROM table_name WHERE column_name IN (value1, value2, ..., valueM);
UNION ALL
SELECT * FROM table_name WHERE column_name IN (valueM+1, ..., valueN);
这种方式可以减少单次查询的解析和执行时间。
使用临时表替代 IN 条件:
将 IN 条件中的值存储到一个临时表中,并通过 JOIN 查询替代 IN 条件。例如:
-- 创建临时表
CREATE TEMPORARY TABLE temp_values (
value_column VARCHAR(255)
);
-- 插入 IN 条件中的值
INSERT INTO temp_values (value_column) VALUES ('value1'), ('value2'), ..., ('valueN');
-- 使用 JOIN 替代 IN
SELECT t.*
FROM table_name t
JOIN temp_values v ON t.column_name = v.value_column;
IN 条件中涉及的字段有适当的索引。如果没有索引,数据库可能会进行全表扫描,导致性能下降。CREATE INDEX idx_column_name ON table_name (column_name);
IN 条件中的值可以通过子查询生成,可以尝试将 IN 替换为 EXISTS 或 JOIN。例如:-- 原始 SQL
SELECT * FROM table_name WHERE column_name IN (subquery);
-- 替换为 EXISTS
SELECT * FROM table_name t
WHERE EXISTS (SELECT 1 FROM subquery_table s WHERE t.column_name = s.value_column);
-- 或者替换为 JOIN
SELECT DISTINCT t.*
FROM table_name t
JOIN subquery_table s ON t.column_name = s.value_column;
/*+ PARALLEL(table_name, 4) */
SELECT * FROM table_name WHERE column_name IN (value1, value2, ..., valueN);
ANALYZE TABLE table_name COMPUTE STATISTICS;
根据您的描述和提供的执行计划,SQL 性能问题的主要原因是 IN 条件中的值过多,导致解析和执行时间过长。建议您尝试以下方法优化:
IN 条件或使用临时表替代。EXISTS 或 JOIN。如果问题仍未解决,请提供以下信息以便进一步分析:
希望以上建议对您有所帮助!
具体信息可参考以下文档:
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
链接:https://foreignfile.catl.com/outpublish.html?code=Ab7208ec27c234c4698d7b4c8f654c6aa&lang=zh-cn#view
密码:63B83A11
文本信息如下
ob小助手讲的比较全面了
不错,学习了
语句为框架中的语句,无法修改.
表不是很大,分别为75w,和32w
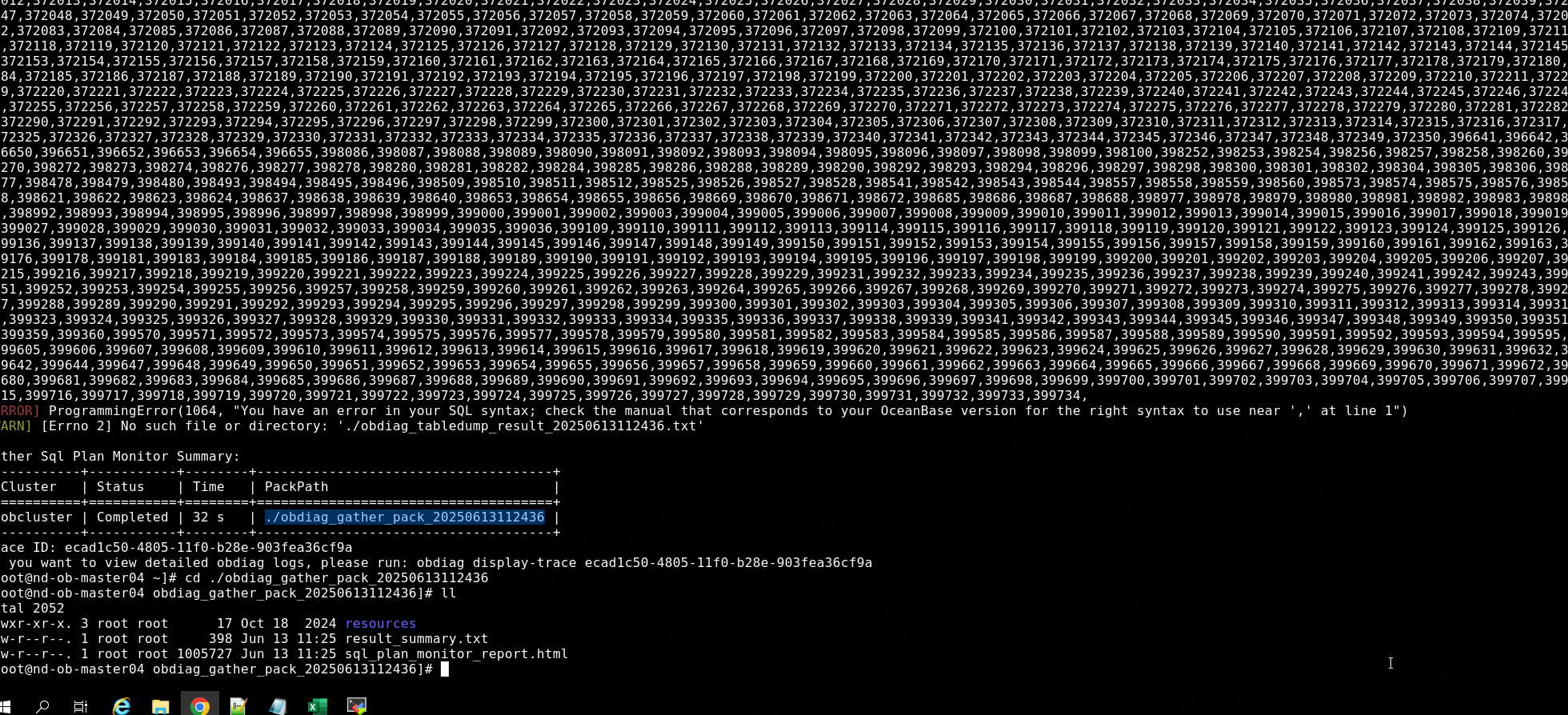
1.SQL 详情收集
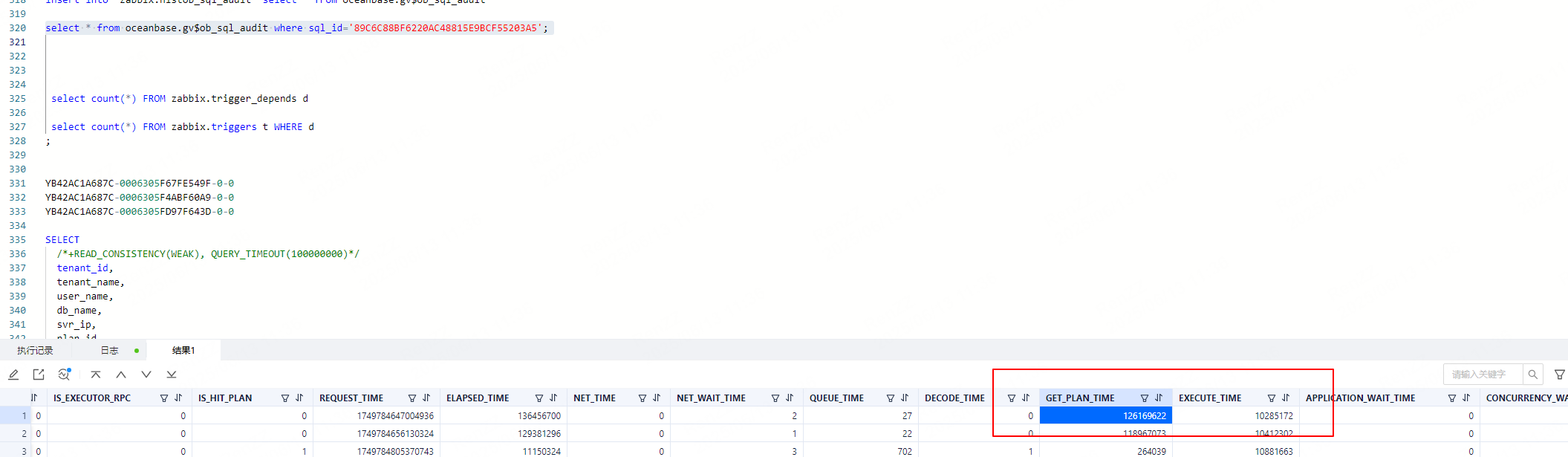
gv$ob_sql_audit 通过这个视图 查询一下sql执行的trace_id
obdiag gather plan_monitor --trace_id YB420BA2D99B-0005EBBFC45D5A00-0-0 --env"{db_connect=’-hxx -Pxx -uxx -pxx -Dxx’}"
收集以后 提供一下
稍等下,我收集下
可以直接把收集的信息 发到帖子上么?无法下载 打开以后 下载无响应
这个网址没法上传文件,之前 旭辉他们是可以的,把安全网关关了之后试试
那你发给旭辉吧 让他转给我一下
那个网盘连接旭辉可以直接打开的
ob是4350么?SHOW VARIABLES like ‘version_comment’;查一下