【 使用环境 】POC 验证环境
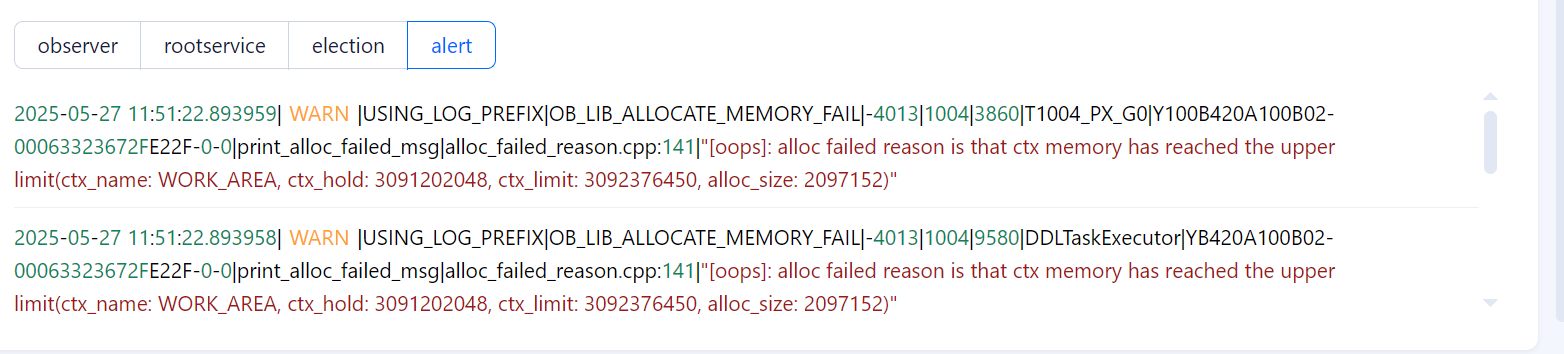
alert日志如下图
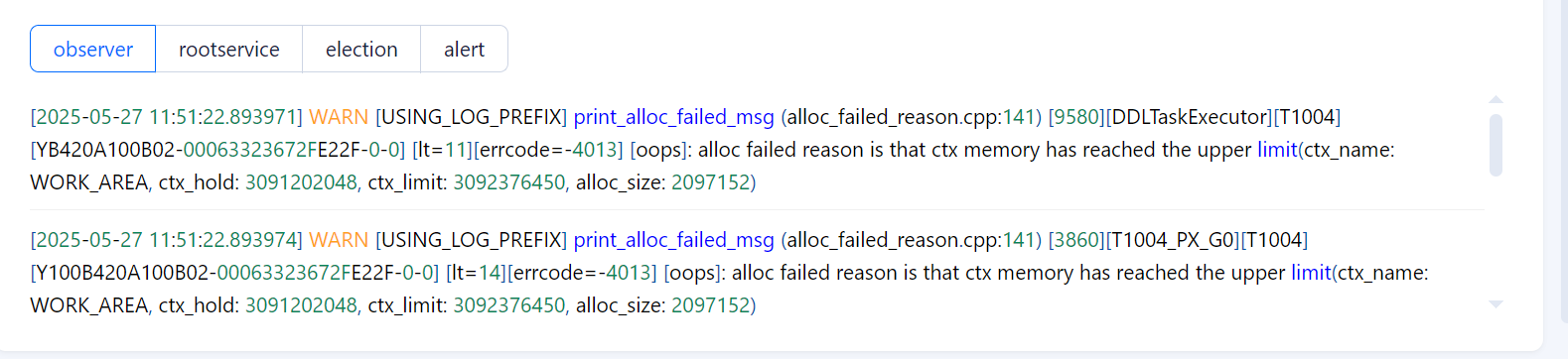
observer.log
【复现路径】问题出现前后相关操作
【SOP系列 22 】——故障诊断第一步(自助诊断和诊断信息收集)
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手 ] 即可召唤小助手,欢迎试用!
论坛小助手
2025 年5 月 27 日 14:18
#3
根因分析场景: DDL过程中报磁盘空间不足的问题
为了更好地帮助您解决此问题,建议您使用上述命令进行根因分析和日志采集,并将采集到的日志提供给我们以便确认问题所在。以下是进一步需要了解的信息:
您的租户内存限制(tenant memory limit)是多少?是否可以适当调整以满足当前操作的需求?
在执行 ALTER TABLE 操作之前,是否有其他高内存消耗的操作正在运行?例如大规模数据导入或复杂查询?
您能否提供具体的 SQL 语句以及涉及的表结构信息?这有助于我们更准确地评估内存需求。
当前系统中是否存在其他同时运行的 DDL 或者长时间运行的任务,可能会占用较多资源?
您的 OceanBase 数据库版本是什么?不同版本可能对内存管理有不同的优化策略。
附上敏捷诊断工具 obdiag 使用帮助链接
辞霜
2025 年5 月 27 日 14:23
#4
查询下 变量 ob_sql_work_area_percentage 大小如果是5的话调到10在执行alter看看。
obclient(root@dsp_tt)[oceanbase]> select * from GV$OB_MEMSTORE limit 1\G
obclient(root@dsp_tt)[oceanbase]> show variables like ‘ob_sql_work_area_percentage’;
obclient(root@dsp_tt)[oceanbase]>
老师您好调整 ob_sql_work_area_percentage=10% 还是有报错,是否可session 级别在调大一些??
报错日志如下
2025-05-27 14:37:49.659897|WARN|USING_LOG_PREFIX|OB_LIB_ALLOCATE_MEMORY_FAIL|-4013|1004|26541|T1004_PX_G0|Y100B420A100B02-00063323734FF84A-0-0|print_alloc_failed_msg|alloc_failed_reason.cpp:141|"[oops]: alloc failed reason is that ctx memory has reached the upper limit(ctx_name: WORK_AREA, ctx_hold: 6184501248, ctx_limit: 6184752900, alloc_size: 2097152)"
论坛小助手
2025 年5 月 27 日 14:49
#6
根据您提供的信息,问题的核心是 内存不足 ,导致 ALTER TABLE 操作失败。以下是详细的分析和解决方案建议:
从您提供的 GV$OB_MEMSTORE 查询结果可以看出:
MEMSTORE_USED: 当前内存存储已使用量为 536,870,912 字节 (约 512 MB) 。
MEMSTORE_LIMIT: 内存存储限制为 30,923,764,500 字节 (约 28.8 GB) 。
这表明租户的内存限制较大,但当前内存分配可能已经接近某些特定上下文(如 WORK_AREA)的限制。
此外,ob_sql_work_area_percentage 的值为 10% ,这意味着 SQL 执行时的工作区内存限制为租户总内存的 10%。结合日志中的信息:
ctx_hold: 当前持有的内存为 6,184,501,248 字节 (约 5.76 GB) 。
ctx_limit: 上下文内存限制为 6,184,752,900 字节 (约 5.76 GB) 。
这说明 WORK_AREA 的内存已经接近上限,无法再分配更多内存。
ob_sql_work_area_percentage
您可以尝试在会话级别临时调整 ob_sql_work_area_percentage 的值,以增加工作区内存的限制。例如,将其设置为 20% 或更高:
SET SESSION ob_sql_work_area_percentage = 20;
然后重新执行 ALTER TABLE 操作。如果问题仍然存在,可以逐步增加该值,直到操作成功。
注意 : 调整此参数可能会对其他正在运行的任务产生影响,请确保租户有足够的剩余内存。
如果调整内存参数后仍然报错,可以考虑将大表拆分为多个小批次进行修改。具体步骤如下:
创建一个新表,包含目标字段类型:
CREATE TABLE new_table AS SELECT * FROM xxx WHERE 1=0;
ALTER TABLE new_table MODIFY xxxxtime DATETIME(6);
使用 INSERT INTO ... SELECT 分批次插入数据:
INSERT INTO new_table SELECT * FROM xxx WHERE id BETWEEN start_id AND end_id;
根据表的大小和系统负载,合理划分批次范围。
删除旧表并重命名新表:
DROP TABLE xxx;
RENAME TABLE new_table TO xxx;
这种方法可以有效减少单次操作的内存消耗。
如果上述方法仍无法解决问题,可能是租户的整体内存限制不足。可以通过以下命令增加租户的内存限制:
ALTER RESOURCE UNIT unit_name SET memory_size = '更大值';
ALTER TENANT tenant_name UNIT_CONFIG = unit_name;
请根据实际需求调整 memory_size 的值,并确保服务器有足够的物理内存支持。
监控内存使用情况 : 在执行 DDL 操作时,实时监控租户的内存使用情况,避免因其他高内存消耗任务导致资源竞争。
优化表结构 : 如果表中存在大量冗余数据或不必要的索引,可以先进行清理以减少内存压力。
升级版本 : 如果条件允许,建议升级到最新版本的 OceanBase 社区版,以获得更好的性能优化和内存管理能力。
当前问题是由于 WORK_AREA 内存不足导致的。您可以优先尝试 调整 ob_sql_work_area_percentage 参数 或 分批次修改表结构 。如果问题仍未解决,可以考虑 增加租户内存限制 。同时,建议使用 OceanBase 敏捷诊断工具 obdiag 收集更多日志信息,以便进一步分析问题根源。
如有其他疑问,请随时联系!
更多信息请查看:
使用命令行进行运维
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
辞霜
2025 年5 月 27 日 15:14
#9
再扩点试试顺便获取一下相关日志
2)执行sql。
3)获取上个命令的trace
4)获取trace对应的节点
5)取对应的svr_ip节点 过滤日志
6)提供日志信息即可。
1 个赞
小助手老师您好:
老师您户
辞霜
2025 年5 月 27 日 15:48
#13
调回去吧。SQL WORK AREA 工作区内存,是指 SQL 排序等阻塞性算子使用的内存,通过租户系统变量 ob_sql_work_area_percentage 控制,默认值为 5%,即 工作区内存 = 租户内存 * ob_sql_work_area_percentage(默认 5%) 。
如果请求并发量较大,且每个请求占用的工作区内存比较多,可能出现工作区内存不足的报错,经常出现的场景有 union 、sort 、group by 等。上述问题如果出现,可以通过适当调大系统变量ob_sql_work_area_percentage来进行规避。
1 个赞