【 使用环境 】
测试环境
【 OB or 其他组件 】
OB
【 使用版本 】
4.3.5
【问题描述】
oceanbase mysql模式如何获取流式结果集
当前使用mysql驱动为5.1.48
结果集已配置
【复现路径】问题出现前后相关操作
【附件及日志】
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
【 使用环境 】
测试环境
【 OB or 其他组件 】
OB
【 使用版本 】
4.3.5
【问题描述】
oceanbase mysql模式如何获取流式结果集
当前使用mysql驱动为5.1.48
结果集已配置
【复现路径】问题出现前后相关操作
【附件及日志】
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
用户问题总结:在 OceanBase MySQL 模式下配置了流式结果集但未生效,当前使用 MySQL 驱动版本为 5.1.48,OceanBase 版本为 4.3.5。
推荐使用 obdiag 工具进行日志采集,并且将采集到的日志提供给我们以便确认问题所在。
日志采集场景: SQL性能问题
日志采集命令: obdiag gather scene run --scene=observer.perf_sql --env “{db_connect=’-h127.0.0.1 -P2881 -utest@test -p****** -Dtest’, trace_id=‘Yxx’}”
为了更好地帮助您定位和解决问题,请您按照上述命令采集日志并上传日志压缩包。同时,请您提供以下信息:
useServerPrepStmts=true 和 rewriteBatchedStatements=true 等参数?附上敏捷诊断工具 obdiag 使用帮助链接
是否确认 MySQL 驱动已正确配置为支持流式结果集?例如是否设置了 useServerPrepStmts=true 和 rewriteBatchedStatements=true 等参数?
没有设置这些参数
当前执行的 SQL 是否涉及大结果集(如查询返回大量数据)?如果是,请提供具体的 SQL 示例。
涉及大结果集
是否可以提供完整的 JDBC 连接字符串以及相关配置(请隐藏敏感信息)?
是否有其他异常日志或错误提示出现在应用端或数据库端?如果有,请一并提供。
无,当前查询返回大量数据,flink任务直接oom挂了
根据您提供的信息,以下是针对 OceanBase MySQL 模式下获取流式结果集问题的详细分析和解决方案:
MySQL 驱动配置问题
根据您的描述,当前 MySQL 驱动未设置支持流式结果集的关键参数(如 useServerPrepStmts=true 和 rewriteBatchedStatements=true)。这些参数对于启用流式结果集至关重要。如果未正确配置,驱动程序可能会尝试将整个结果集加载到内存中,从而导致内存溢出(OOM)。
大结果集处理问题
当前执行的 SQL 涉及大结果集,而未启用流式结果集会导致 Flink 任务在处理大量数据时直接 OOM。这是因为默认情况下,JDBC 驱动会将所有查询结果一次性加载到内存中,而不是逐行读取。
Flink 任务 OOM 原因
Flink 任务挂掉的原因是由于 JDBC 驱动未启用流式结果集,导致内存不足。为了解决此问题,需要正确配置 MySQL 驱动以支持流式结果集。
在 JDBC 连接字符串中添加以下参数:
useServerPrepStmts=true:启用服务器端预编译语句。useCursorFetch=true:启用游标分页机制。defaultFetchSize=100:设置每次从服务器获取的行数(可根据实际需求调整)。示例 JDBC 连接字符串:
jdbc:oceanbase://<host>:<port>/<database>?useServerPrepStmts=true&useCursorFetch=true&defaultFetchSize=100
在 Flink 中使用 JDBC Connector 时,可以通过 WITH 子句指定连接参数。确保在创建表时添加以下配置:
fetch-size:设置每次从数据库获取的行数。示例 Flink SQL 创建表语句:
CREATE TABLE ob_large_result_set (
col1 INT,
col2 STRING,
col3 STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:oceanbase://<host>:<port>/<database>?useServerPrepStmts=true&useCursorFetch=true&defaultFetchSize=100',
'username' = '<username>',
'password' = '<password>',
'table-name' = '<table_name>',
'fetch-size' = '100'
);
如果数据量特别大,建议适当增加 Flink 任务的内存配置,避免因内存不足导致任务失败。可以通过以下方式调整:
taskmanager.memory.process.size: 4g
taskmanager.network.memory.fraction: 0.7
对于涉及大结果集的查询,建议优化 SQL 逻辑,减少返回的数据量。例如:
LIMIT 或分页查询。示例分页查询:
SELECT * FROM large_table WHERE condition LIMIT 100 OFFSET 0;
MySQL 驱动版本兼容性
当前使用的 MySQL 驱动版本为 5.1.48,建议升级到最新版本(如 8.x),以获得更好的性能和兼容性支持。
OceanBase 版本限制
确保 OceanBase 数据库版本(4.3.5)支持上述配置参数。如果不支持,请参考官方文档或联系技术支持。
日志采集与问题排查
如果问题仍未解决,可以使用 obdiag 工具采集日志并上传,以便进一步分析。日志采集命令如下:
obdiag gather scene run --scene=observer.perf_sql --env "{db_connect='-h<host> -P<port> -u<user>@<tenant> -p<password> -D<database>', trace_id='Yxx'}"
希望以上解决方案能够帮助您解决问题!如果仍有疑问,请随时联系我们。
检索到的文档如下:
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
1. 配置 MySQL 驱动支持流式结果集
在 JDBC 连接字符串中添加以下参数:
useServerPrepStmts=true:启用服务器端预编译语句。useCursorFetch=true:启用游标分页机制。defaultFetchSize=100:设置每次从服务器获取的行数(可根据实际需求调整)。这种配置是游标结果集?
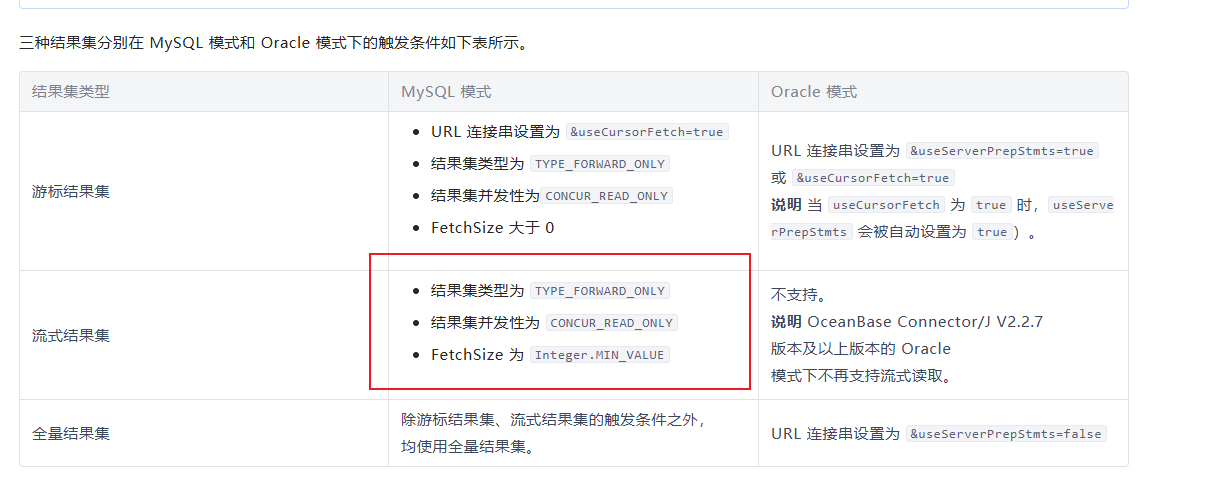
感觉这个截图文档有些问题,流式读取开启的的条件:
试试上面的
更换下oceanbase-client的驱动
oceanbase-client驱动是可以的获取流式结果集,mysql驱动不兼容么
游标结果集和流式结果集需要走ps协议
mysql-jdbc Statement语句在ps 参数开启时会走文本协议,需要用prepareStatement 语句
直接换了个驱动,没改代码吗?
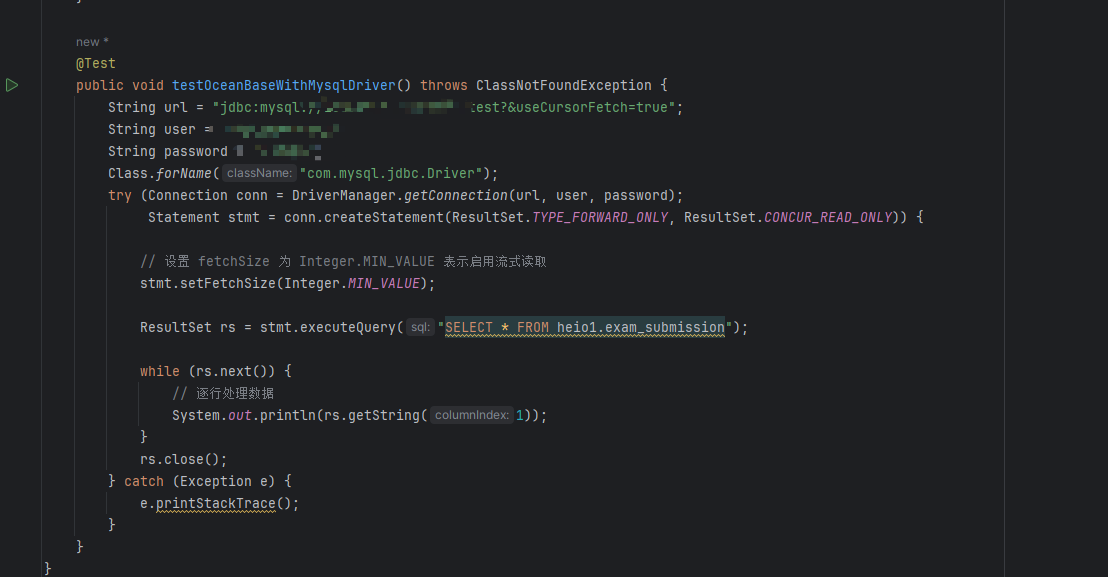
Statement stmt = conn.createStatement(
ResultSet.TYPE_FORWARD_ONLY,
ResultSet.CONCUR_READ_ONLY);
stmt.setFetchSize(Integer.MIN_VALUE);
这是 MySQL JDBC 驱动的一个特殊设定,用来启用 流式读取,避免一次性把整个结果集加载到内存中。
3. 示例代码
Connection conn = DriverManager.getConnection(url, user, password);
Statement stmt = conn.createStatement(
ResultSet.TYPE_FORWARD_ONLY,
ResultSet.CONCUR_READ_ONLY);
stmt.setFetchSize(Integer.MIN_VALUE);
ResultSet rs = stmt.executeQuery(“SELECT * FROM your_table”);
while (rs.next()) {
// 处理每一行数据
}
rs.close();
stmt.close();
conn.close();
注意事项
fetchSize = Integer.MIN_VALUE 是 MySQL Connector/J 5.x 的特殊写法。
如果你将来切换到 Connector/J 8.x,则应该用 stmt.setFetchSize(N)(如 100)启用 server-side cursor。
确保你的 SQL 查询语句没有包含 ORDER BY 或 GROUP BY 之类可能导致全量加载的操作。
可以试试
用prepareStatement 是否没问题?
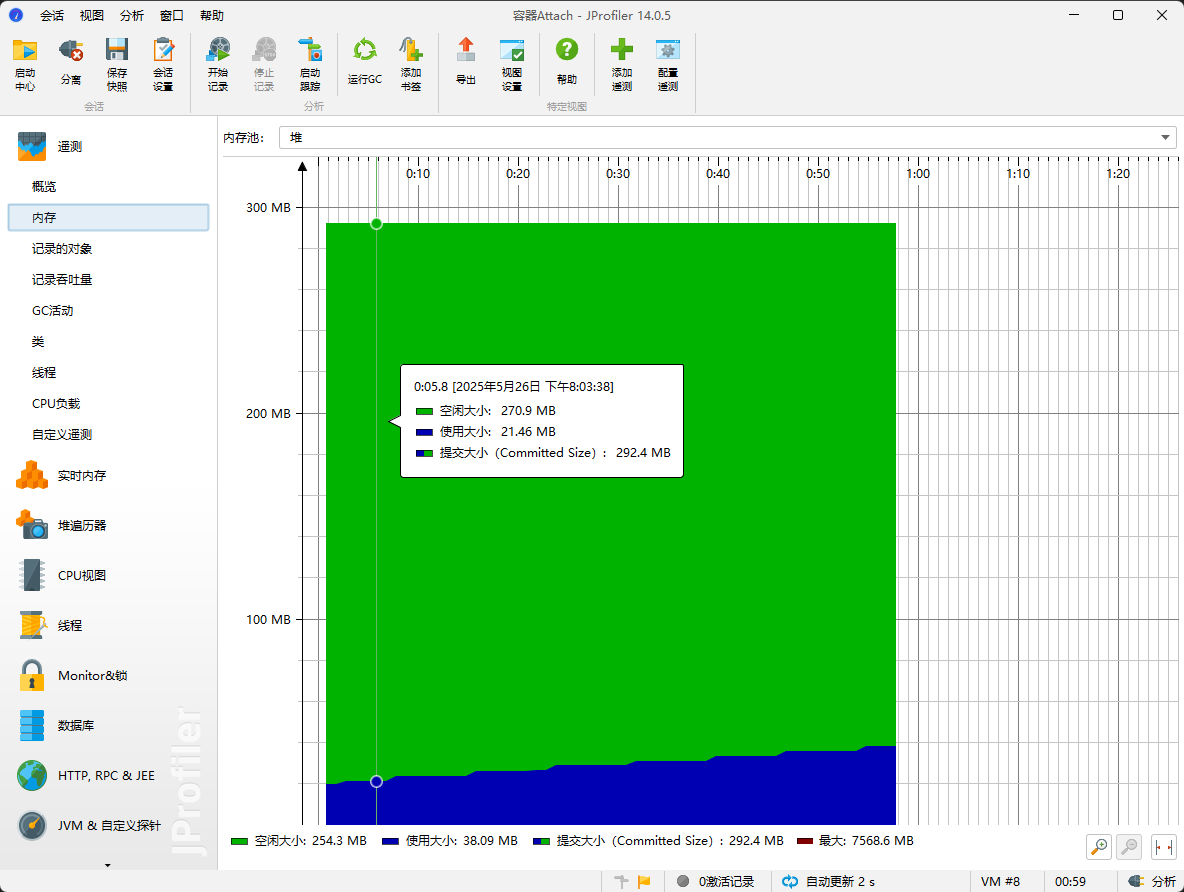
代码看着没什么问题,不太确认为什么原生jdbc走流式会上涨。建议你使用objdbc,或者使用prepareStatement 语句。怀疑是原生jdbc的bug吧
可以升级jdbc版本看看
驱动用mysql 8.1.x,并使用prepareStatement 内存还是会上涨,