【 使用环境 】生产环境
【 OB or 其他组件 】
【 使用版本 】
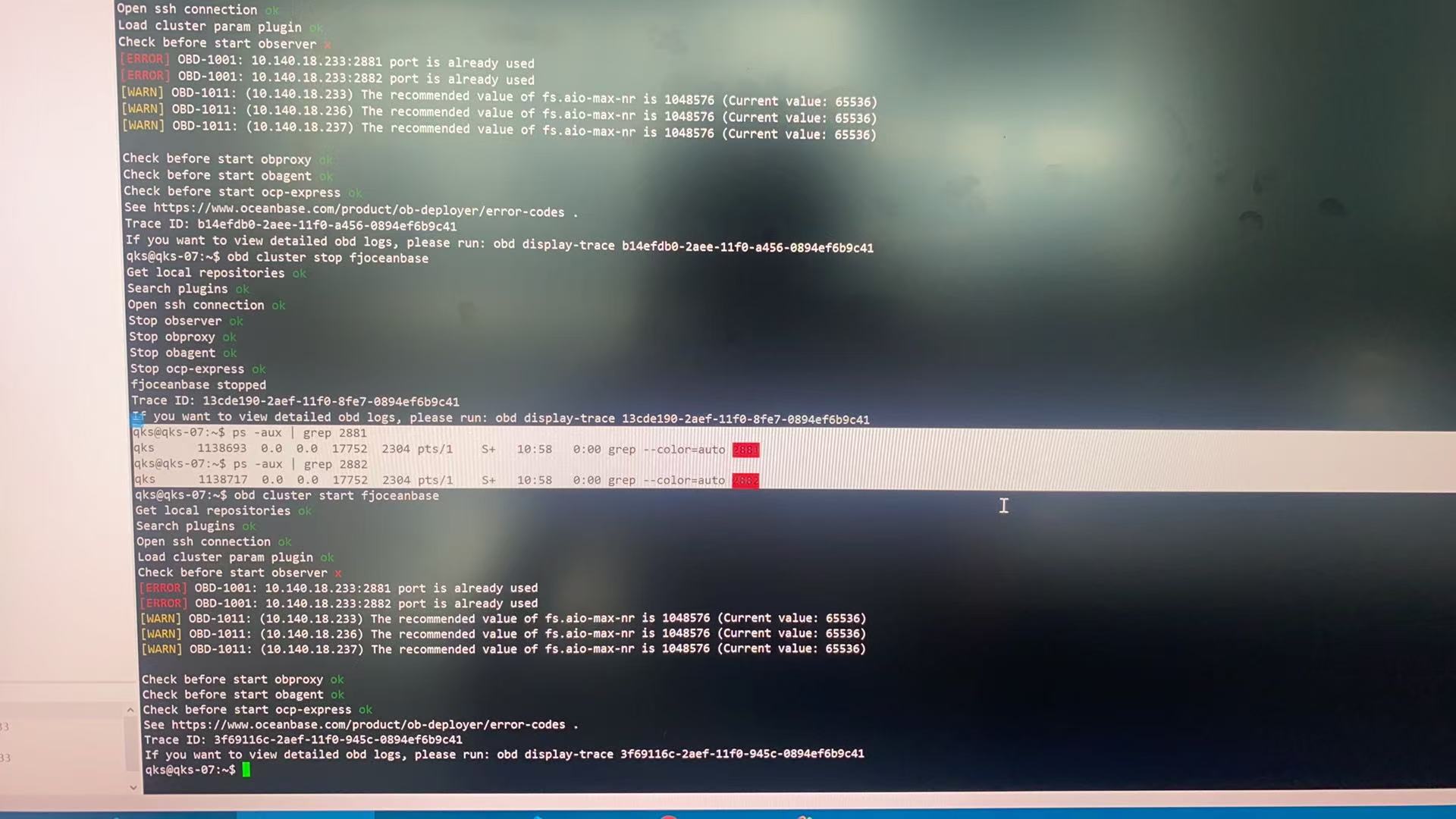
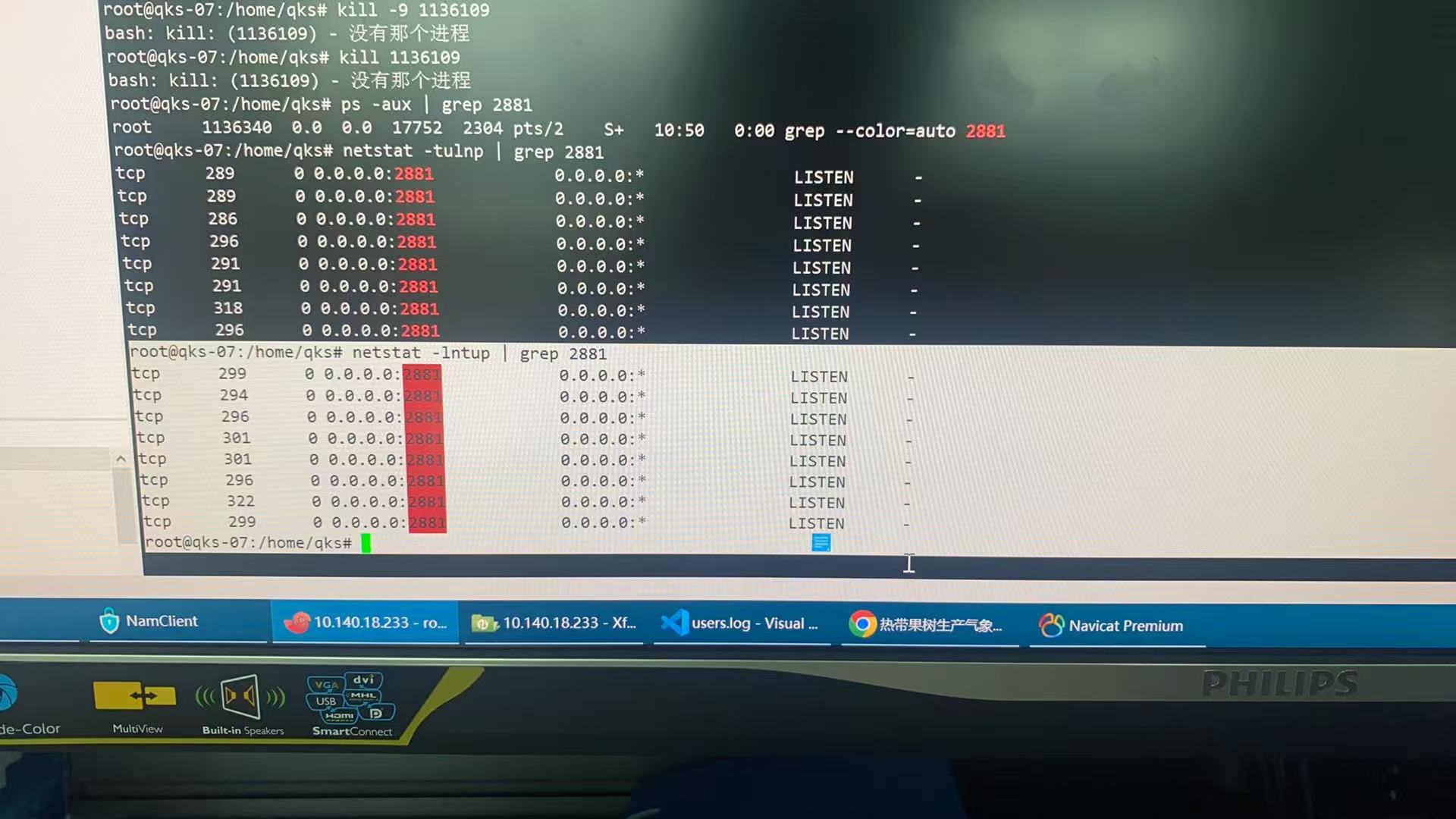
【问题描述】使用obd cluster restar耗时太久我关闭后,使用stop停止正常,然后再star启动就提示端口被占用,查询ps -aux | grep 2881 和2882没有被占用的进程。使用netstat -anp | grep 2881,查看到有很多CLOSE_WAIT状态的连接,是我停止的有问题吗?要怎么解决。
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【SOP系列 22 】——故障诊断第一步(自助诊断和诊断信息收集)
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
3 个赞
论坛小助手
#3
根因分析场景: 针对断链接场景的根因分析
根因分析命令: obdiag rca run --scene=disconnection
日志采集场景: 集群无法连接
日志采集命令: obdiag gather scene run --scene=observer.cluster_down
推荐使用 obdiag 工具进行根因分析和日志采集,以便确认问题所在。上述命令将帮助您收集集群启动失败的相关日志,并分析断链接可能的原因。请您运行以上命令并将生成的日志压缩包提供给我们。
另外,为了更好地了解问题并提供解决方案,在此需要您提供一些额外信息:
- 是否有其他程序或服务可能与 OceanBase 集群使用了相同的端口?
- CLOSE_WAIT 状态连接的数量级是多少?例如,是几百个还是上万个?
- 集群在重启之前是否有异常情况发生,例如高负载、网络中断或其他操作?
- 当前系统中是否有防火墙或安全软件可能干扰了端口的正常使用?
- 是否可以尝试手动停止所有 observer 进程后再次启动集群?如果可以,请告知结果。
附上敏捷诊断工具 obdiag 使用帮助链接
5 个赞
辞霜
#4
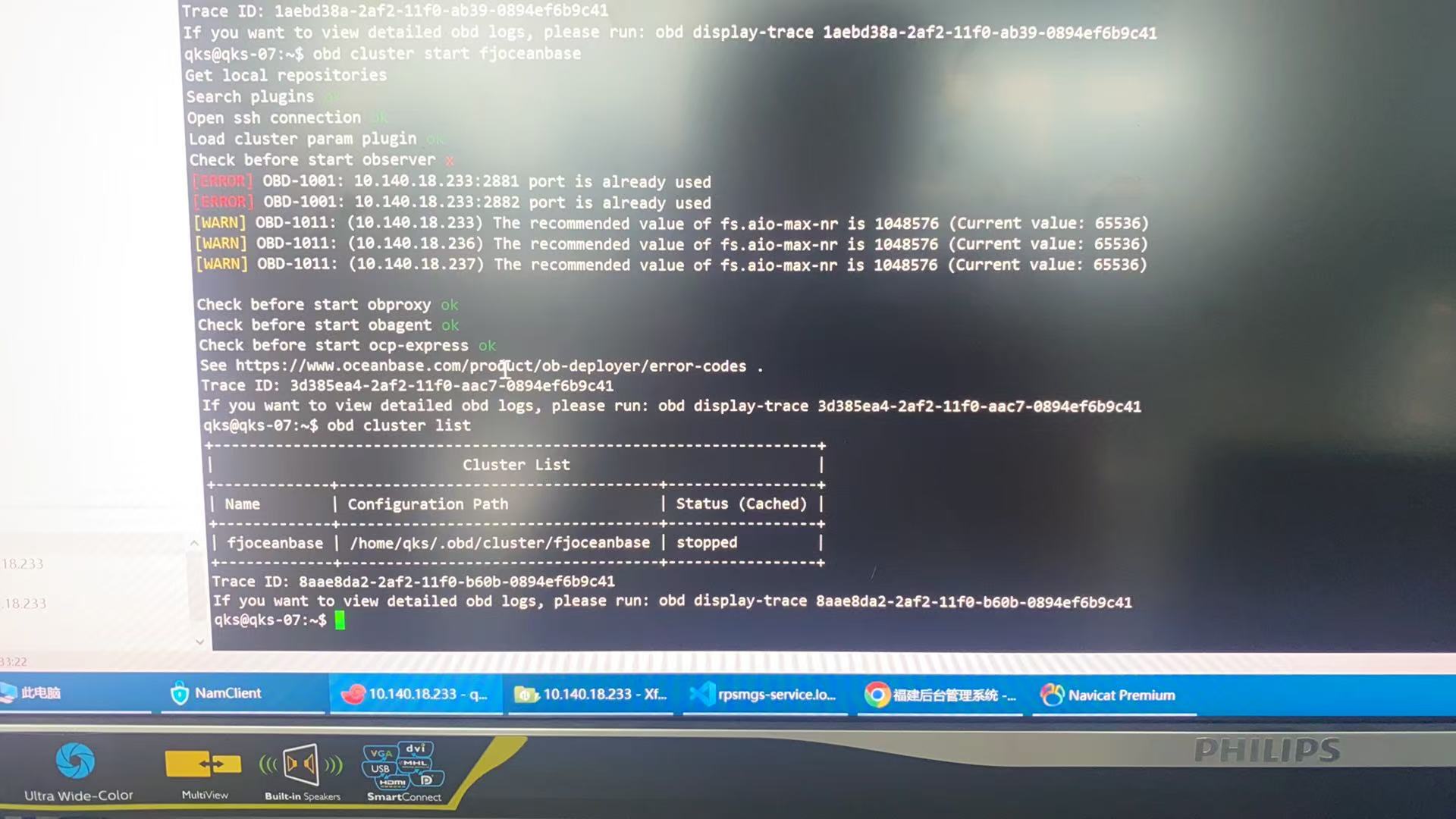
obd cluster list 看一下集群状态。
再使用obd stop一次集群重新启动试试
6 个赞
Giant
#7
233机器
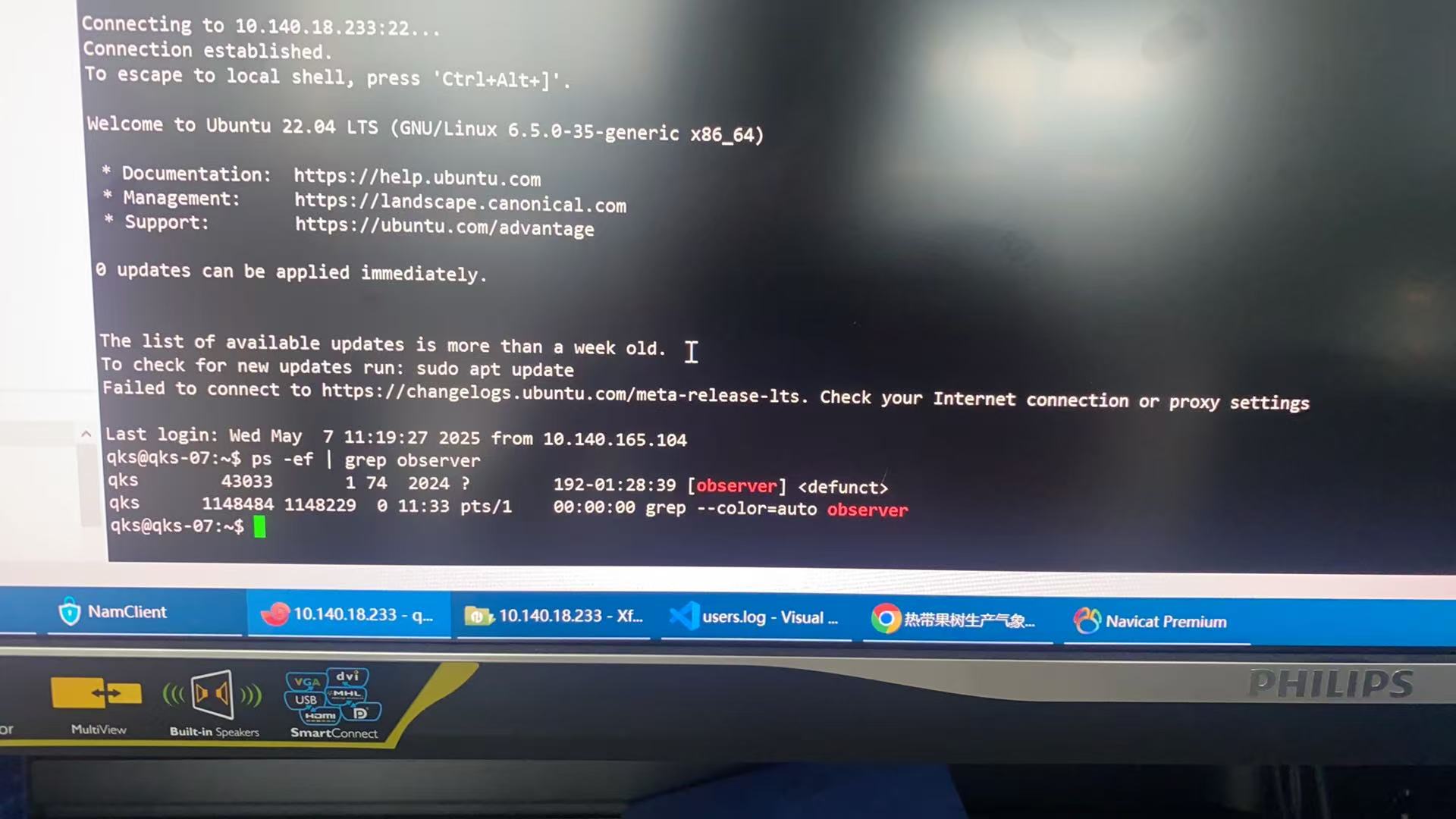
ps -ef| grep observer 看下 是否还在
5 个赞
论坛小助手
#8
根据您提供的信息和图片内容,集群启动失败的问题可能与以下几点有关:
问题分析
-
端口占用问题
尽管您通过 ps -aux | grep 没有发现端口被占用的进程,但 netstat -anp | grep 2881 显示存在大量 CLOSE_WAIT 状态的连接。这表明可能存在未正确关闭的连接或资源泄漏。
-
系统参数配置不足
根据日志提示:
[WARN] OBD-1011: (10.140.18.233) The recommended value of fs.aio-max-nr is 1048576 (Current value: 65536)
当前系统的 fs.aio-max-nr 参数值为 65536,低于推荐值 1048576。这可能导致 I/O 资源不足,进而影响集群启动。
-
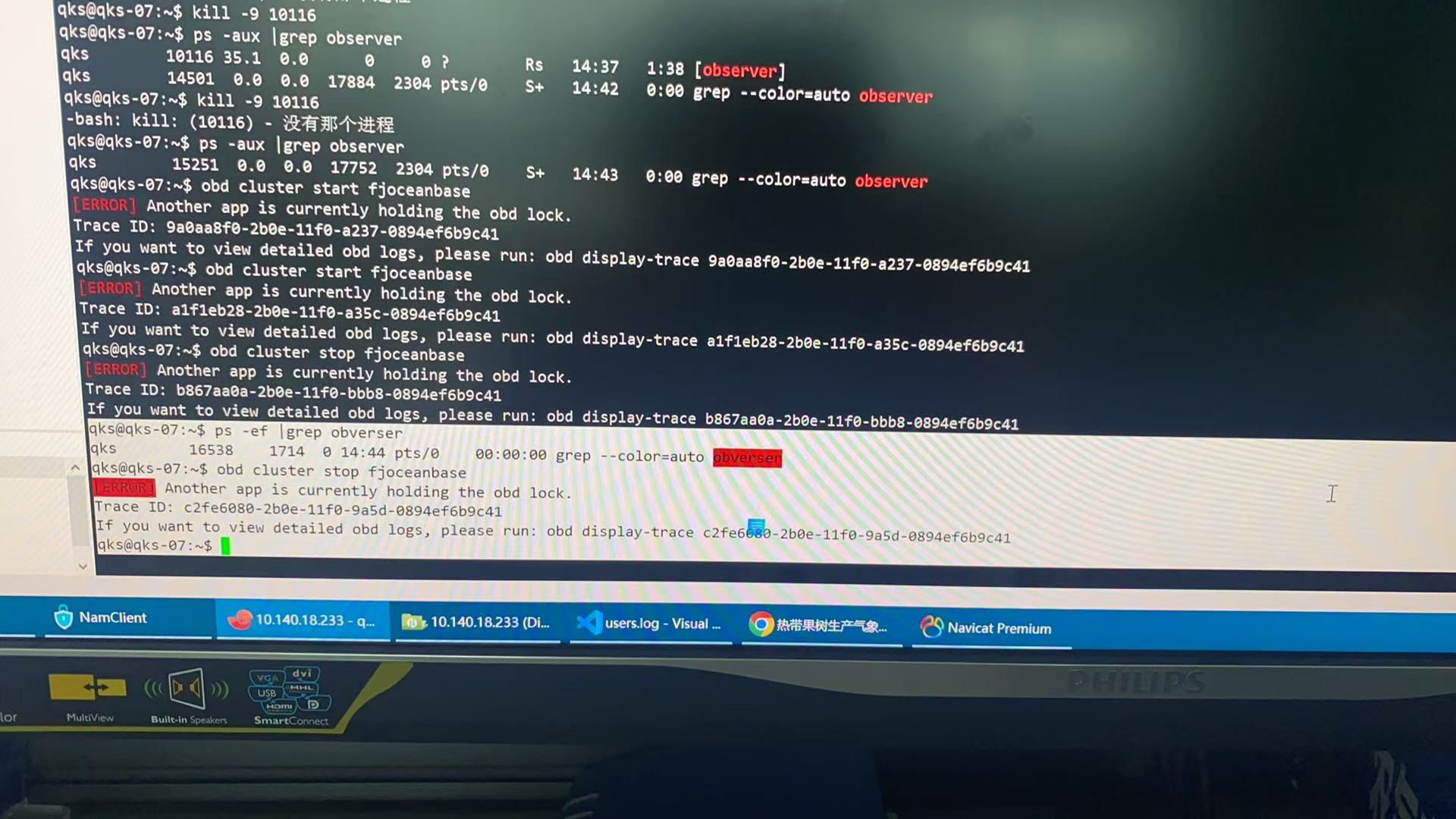
残留的 Observer 进程
如果在停止集群时没有完全清理 Observer 进程,可能会导致端口无法释放,从而影响后续启动。
解决方案
1. 检查并调整系统参数
请检查并调整以下系统参数以满足 OceanBase 的要求:
# 查看当前 fs.aio-max-nr 值
cat /proc/sys/fs/aio-max-nr
# 修改临时值(需重启后失效)
sudo sysctl -w fs.aio-max-nr=1048576
# 永久修改(添加到 /etc/sysctl.conf 中)
echo "fs.aio-max-nr=1048576" | sudo tee -a /etc/sysctl.conf
sudo sysctl -p
2. 清理 CLOSE_WAIT 状态的连接
尝试使用以下命令强制关闭 CLOSE_WAIT 状态的连接:
# 查找并杀死相关进程
sudo lsof -i :2881
sudo kill -9 <PID>
# 或者直接重置连接
sudo ss -tanp | grep CLOSE_WAIT | awk '{print $5}' | cut -d':' -f1 | sort | uniq | xargs -I {} ssh root@{} "echo {}"
3. 手动清理 Observer 进程
确保所有 Observer 进程已被完全停止:
# 查找 Observer 进程
ps -ef | grep observer
# 杀死残留进程
sudo kill -9 <PID>
4. 使用 obdiag 工具进行诊断
运行以下命令收集日志并分析问题原因:
# 收集日志
obdiag gather scene run --scene=observer.cluster_down
# 分析断链接场景
obdiag rca run --scene=disconnection
将生成的日志压缩包上传至 OceanBase 社区支持团队以获取进一步帮助。
5. 重新启动集群
完成上述步骤后,尝试重新启动集群:
obd cluster start <cluster_name>
注意事项
- 如果问题仍未解决,请提供以下信息以便进一步排查:
-
obdiag 收集的日志文件。
- 系统环境信息(操作系统版本、内核版本等)。
- 集群配置文件(如
config.yaml)。
- 推荐参考官方文档:OceanBase 集群启动异常处理
希望以上方法能帮助您解决问题!如果仍有疑问,请随时联系 OceanBase 技术支持团队。
具体信息可参考以下文档:
- tenant_active_memstore_percent_over_threshold OB 租户活跃内存百分比超限
- ob_tenant_compaction_error OB 租户合并出错
- 集群诊断
- 查询 OBProxy 集群列表
- 启动 OBProxy
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
5 个赞
Giant
#10
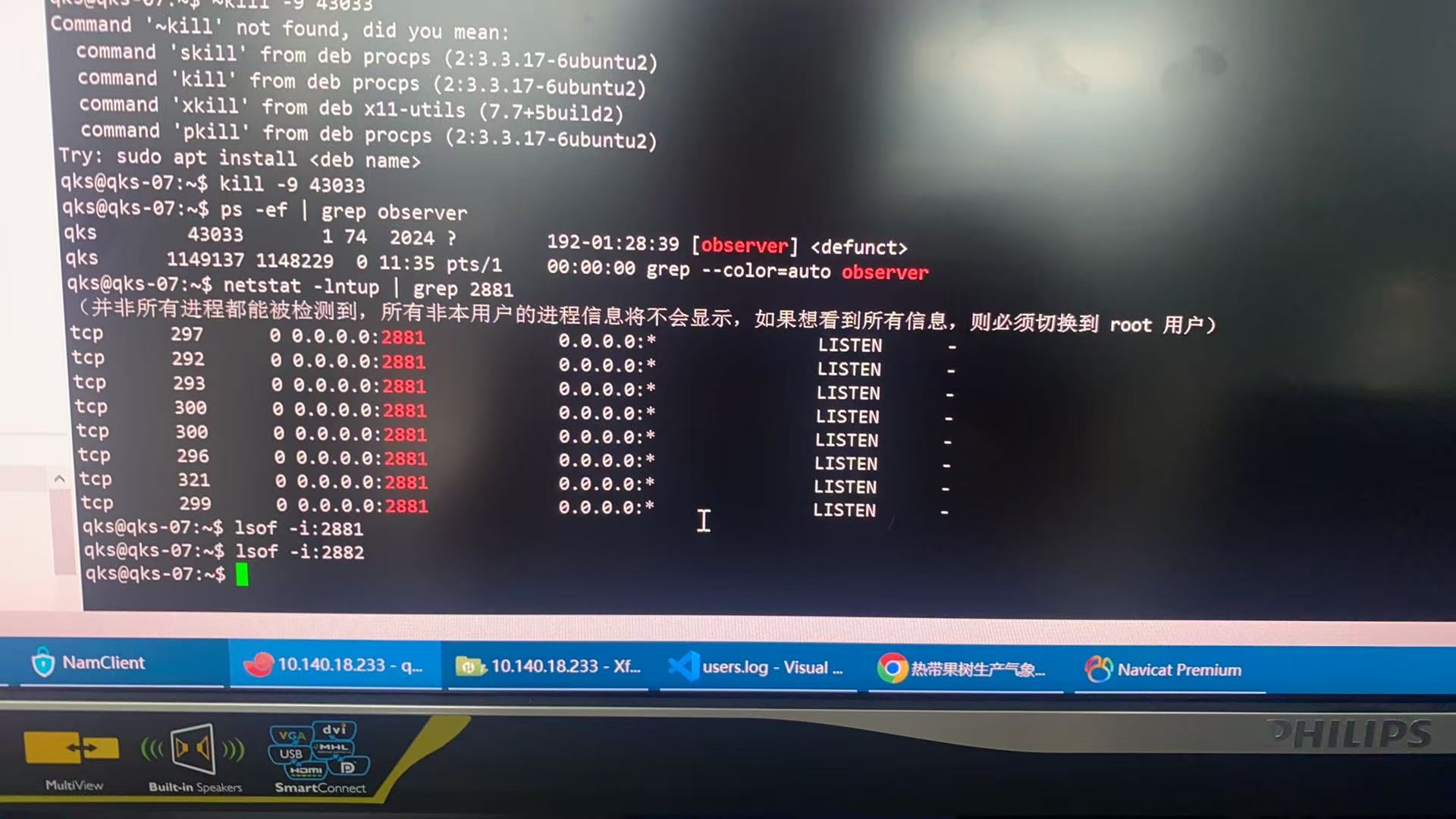
netstat -lntup| grep 2881
lsof -i:2882
lsof -i:2881
都执行下 , 那个不是有个 observer进程 , 你kill掉 看看
4 个赞
Giant
#14
看着清醒 , 你这 机器 有人已经在使用了吧。 您kill的时候小心点。
如果确认没问题,到root 用户干掉吧
2 个赞
渔舟唱晚
#15
defunct 显示为僵尸进程,一般情况下无法杀掉僵尸进程。
可以尝试以下操作:
1 清理共享内存
ipcs -q | grep admin | awk '{print $2}' | xargs -i ipcrm -q {}
ipcs -s | grep admin | awk '{print $2}' | xargs -i ipcrm -s {}
ipcs -m | grep admin | awk '{print $2}' | xargs -i ipcrm -m {}
2 重启操作系统
reboot -f
3 个赞
把root干掉是什么意思,我切换root用户查netstat -lntup 2881也是一样的几个
1 个赞
Giant
#18
使用root用户看看能不能干掉。 确定没其他业务的话。不能就重启大法吧
重启大法!
3 个赞
重启了,这是被锁了?已经没有obverser的进程了阿
辞霜
#21
是不是有obd web在运行中?
参考楼上的 重启节点或者杀掉僵尸进程试试
有一个这个进程,在其他台 ,我都给关了之后,可以start了,在执行中,看看能不能起来