【 使用环境 】生产环境 or 测试环境
【 OB or 其他组件 】ocp平台
【 使用版本 】4.2.1.5
【问题描述】1.使用ocp备份租户,不到5个g备份了40分钟,
拿到测试环境恢复的时候恢复了1个小时也没恢复完
2.备份集上写的4点开始备份,4点42分备份完,我选的恢复时间是4点43分
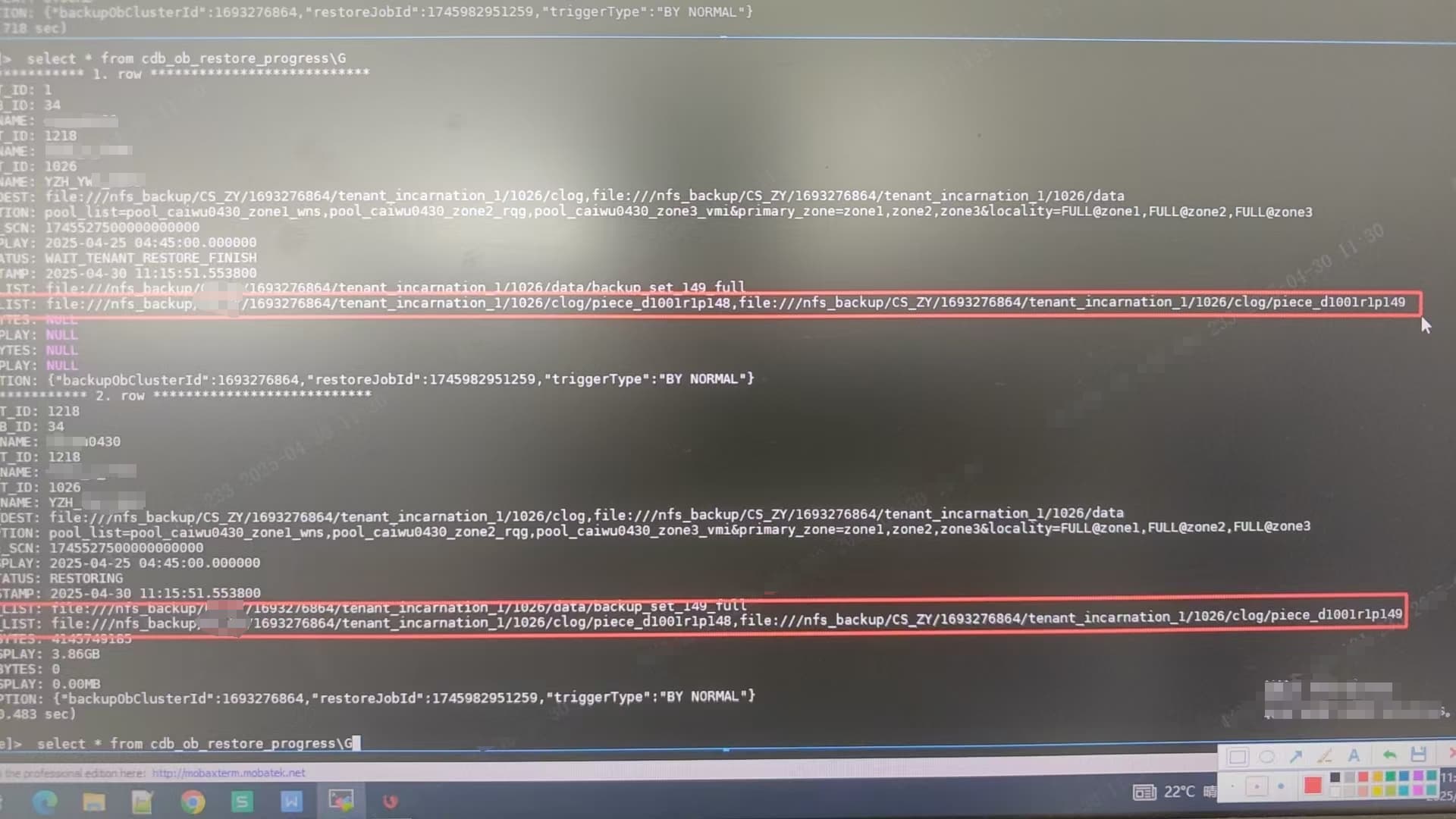
3.CDB_OB_RESTORE_PROGRESS
表BACKUP_PIECE_LIST字段显示有俩clog文件,但是我只有一个clog文件,不知道他咋读出来俩…
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【SOP系列 22 】——故障诊断第一步(自助诊断和诊断信息收集)
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
论坛小助手
#3
根因分析场景: 数据恢复问题
根因分析命令: obdiag rca run --scene=recovery
日志采集场景: 数据恢复问题
日志采集命令: obdiag gather scene run --scene=observer.recovery
推荐使用 obdiag 工具进行根因分析和日志采集,以便确认问题所在。通过执行上述命令,您可以收集到与备份恢复相关的日志信息,这将有助于我们进一步分析问题的原因。请将采集到的日志压缩包提供给我们。
另外,为了更好地帮助您解决问题,请您提供以下信息:
- 备份耗时过长的具体表现是什么?例如,预期耗时与实际耗时的对比情况如何?
- 恢复失败是否有具体的错误信息或错误码?如果有,请提供详细内容。
- CDB_OB_RESTORE_PROGRESS 表中显示的 clog 文件数量与实际不符的具体差异是什么?例如,预期值和实际值分别是多少?
- 当前使用的 OceanBase 版本号是多少?
- 是否有其他异常现象伴随发生,例如 CPU 使用率过高、磁盘空间不足等?如果有,请描述具体情况。
附上敏捷诊断工具 obdiag 使用帮助链接
1.没有任何报错
2.挂的nas,所有ob机器都能读到这个恢复文件
3.选的时间基本不会怎么去读日志去恢复
4.平常备份恢复速度就10分钟左右,这次备份40分钟,恢复超1小时没恢复完感觉问题很大
1 个赞
2块960GB日态硬盘,10块3.2TBNVME固态硬盘,都是NVME的
论坛小助手
#8
根据您提供的信息和上传的图片内容,以下是针对问题的详细分析和可能的解决方案:
问题总结
-
备份耗时过长:正常情况下备份耗时约 10 分钟,但此次备份耗时达 40 分钟。
-
恢复耗时过长:正常情况下恢复耗时约 10 分钟,但此次恢复超 1 小时仍未完成。
-
CDB_OB_RESTORE_PROGRESS 表中显示的 clog 文件数量与实际不符:表中显示有两份 clog 文件,但实际上只有一份。
已知信息
-
环境信息:
- 使用 OCP 平台进行备份和恢复。
- OceanBase 版本为 4.2.1.5。
- 硬件配置:2 块 960GB NVME 日志盘,10 块 3.2TB NVME 固态硬盘。
- 恢复文件存储在 NAS 上,所有 OB 机器均可访问。
-
现象描述:
- 备份和恢复速度显著变慢。
- CDB_OB_RESTORE_PROGRESS 表中显示的 clog 文件数量与实际不符。
- 恢复过程中无明显报错信息。
-
上传图片内容:
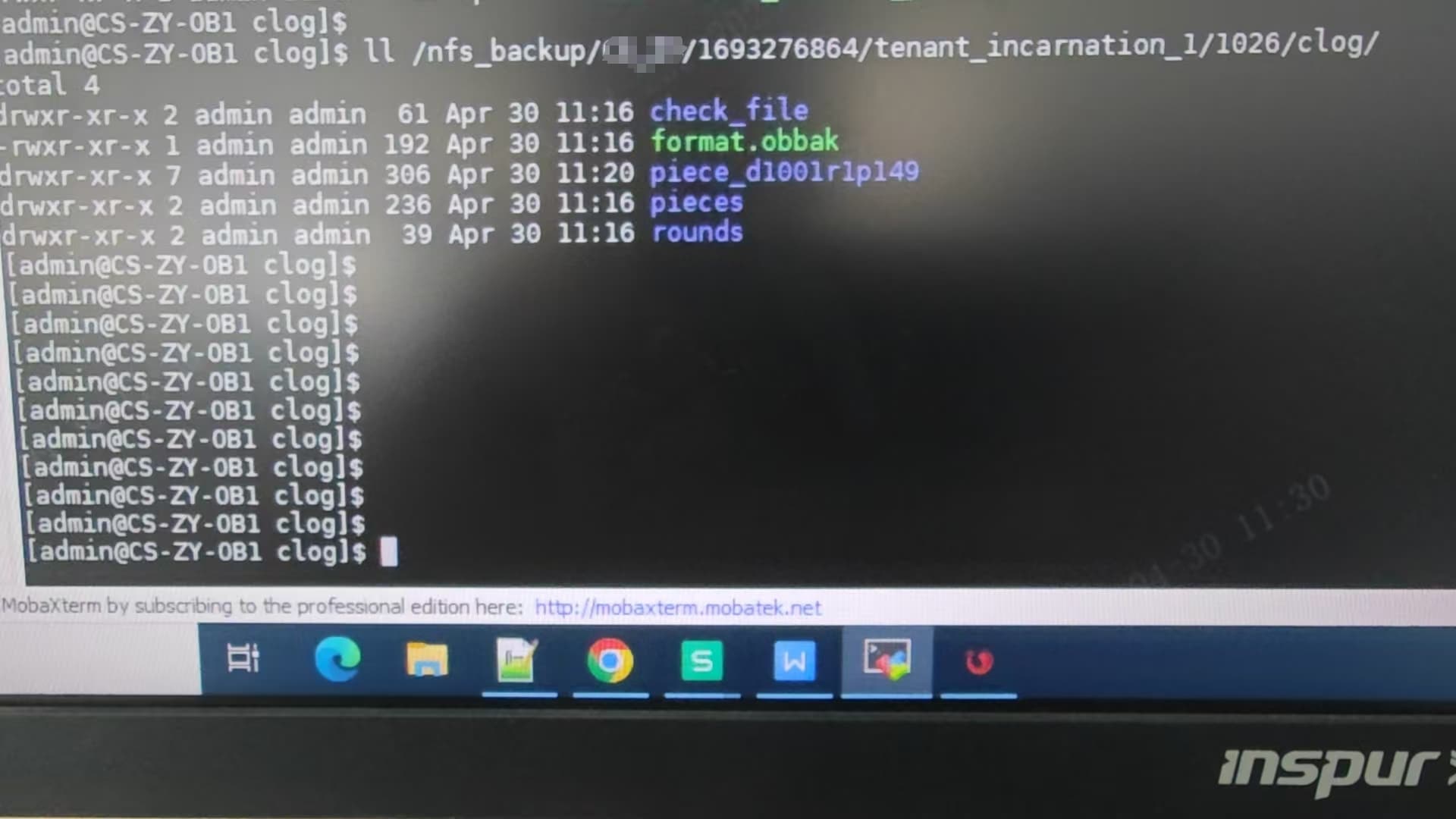
- 图片显示了备份路径、clog 文件路径以及部分日志信息。
- 备份路径为
nfs_backup/CS_ZY/1693276864/tenant_incarnation_1/1026/clog。
- clog 文件路径为
piece_d1001r1p148 和 piece_d1001r1p149。
问题分析
1. 备份耗时过长
-
可能原因:
-
网络带宽限制:如果备份数据通过网络传输到 NAS,可能存在网络带宽不足的情况。
-
磁盘 I/O 性能瓶颈:虽然使用的是 NVME 硬盘,但如果磁盘负载过高或存在其他高 I/O 操作,可能导致性能下降。
-
备份任务并发量过大:如果同时运行多个备份任务,可能会导致资源竞争,从而影响备份速度。
-
建议排查步骤:
- 检查备份期间的网络带宽使用情况,确保网络通畅。
- 使用
iostat 或 dstat 工具监控磁盘 I/O 性能,确认是否存在瓶颈。
- 在 OCP 平台上查看备份任务的并发情况,避免过多任务同时运行。
2. 恢复耗时过长
-
可能原因:
-
恢复路径的读取性能:NAS 的读取性能可能低于本地磁盘,尤其是在多台 OB 机器同时访问时。
-
恢复任务的并行度不足:恢复任务的并行度设置可能较低,导致恢复速度较慢。
-
Clog 文件不一致:CDB_OB_RESTORE_PROGRESS 表中显示的 clog 文件数量与实际不符,可能导致恢复过程反复尝试读取不存在的文件。
-
建议排查步骤:
- 检查 NAS 的读取性能,确保其能够满足恢复任务的需求。
- 在 OCP 平台上调整恢复任务的并行度设置,提高恢复效率。
- 确认 Clog 文件的实际数量是否与表中记录一致。如果不一致,可能是备份过程中出现了异常,建议重新生成备份集。
3. Clog 文件数量不一致
-
可能原因:
-
备份过程中中断:如果备份过程中出现中断,可能导致部分 clog 文件未正确写入。
-
表记录错误:CDB_OB_RESTORE_PROGRESS 表中的记录可能存在错误,未能正确反映实际的 clog 文件数量。
-
建议排查步骤:
- 检查备份日志,确认备份过程中是否存在中断或其他异常。
- 使用以下 SQL 查询 CDB_OB_RESTORE_PROGRESS 表,确认 clog 文件的实际数量:
SELECT BACKUP_PIECE_LIST FROM CDB_OB_RESTORE_PROGRESS WHERE JOB_ID = <恢复任务ID>;
- 如果发现表记录与实际文件数量不一致,建议重新生成备份集。
解决方案
短期解决方案
-
重新生成备份集:
-
优化恢复任务配置:
- 提高恢复任务的并行度,减少恢复时间。
- 在 OCP 平台上调整恢复任务的配置参数。
-
检查 NAS 性能:
- 确保 NAS 的读取性能能够满足恢复任务的需求。
- 如果 NAS 性能不足,考虑将恢复文件存储在本地磁盘上。
长期解决方案
-
定期监控系统性能:
- 使用
obdiag 工具定期收集系统日志和性能数据,及时发现潜在问题。
- 监控网络带宽、磁盘 I/O 和 CPU 使用率等关键指标。
-
优化备份和恢复策略:
- 根据业务需求合理设置备份频率和保留周期,避免过多备份任务同时运行。
- 定期测试备份和恢复流程,确保其稳定性和可靠性。
-
升级硬件配置:
- 如果现有硬件配置无法满足需求,考虑升级网络设备或增加磁盘数量以提升性能。
后续建议
如果您按照上述步骤仍无法解决问题,请提供以下信息以便进一步分析:
- 备份和恢复任务的日志文件(可通过
obdiag 工具收集)。
- CDB_OB_RESTORE_PROGRESS 表的完整查询结果。
- 系统性能监控数据(如网络带宽、磁盘 I/O 和 CPU 使用率等)。
希望以上建议对您有所帮助!
更多信息请查看:
- Alert 日志
- oceanbase.CDB_OB_BACKUP_JOB_HISTORY
- oceanbase.CDB_OB_IMPORT_TABLE_TASKS
- oceanbase.DBA_OB_ARCHIVELOG_SUMMARY
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
Giant
#10
select * from dba_ob_tenants;
或者OCP上的租户信息。 这些发下看看
Giant
#11
您把 您的 恢复过程 也发下吧。 如果使用的是 命令行进行恢复的话