【 使用环境 】测试环境
【 OB or 其他组件 】OMS 4.2.6
【 使用版本 】OMS 4.2.6
【问题描述】请问OMS能否修改投递到kafka的数据格式
【复现路径】
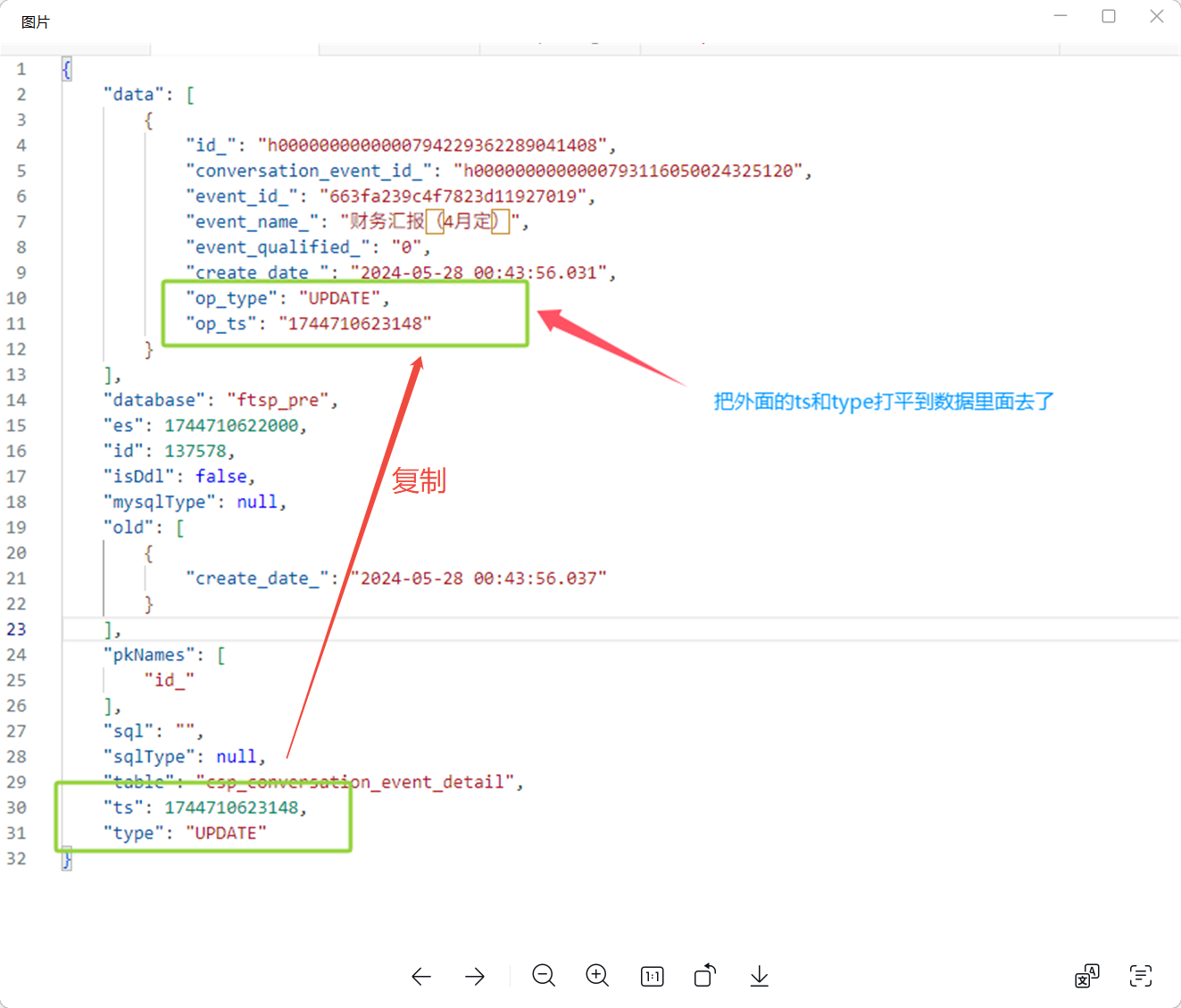
数据序列化方式:Canal
但是,我们这边的研发可能希望将 ts 和 type 这两个字段,复制到 data中。
例子:
请问有方式进行修改吗?
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【SOP系列 22 】——故障诊断第一步(自助诊断和诊断信息收集)
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
1 个赞
论坛小助手
#3
根据文档库中的信息,OMS 社区版支持多种序列化方式来控制数据同步至目标端(如 Kafka)的消息格式。这些序列化方式包括 Default、Canal、Dataworks、SharePlex、DefaultExtendColumnType、Debezium、DebeziumFlatten、DebeziumSmt 和 Maxwell(仅目标端为 Kafka 时支持)。具体参考文档《OceanBase 迁移服务》的 数据同步/功能介绍/数据格式说明。
然而,针对您提出的需求——将 ts 和 type 字段复制到 data 中,目前 OMS 社区版并未提供直接的配置选项来实现这种自定义的数据结构调整。以下是对该问题的详细分析和可能的解决方案:
1. 当前 OMS 的数据格式调整能力
- OMS 提供了多种序列化方式(如 Canal),但每种序列化方式都有固定的输出结构。例如:
-
Canal 格式会将
ts、type 等字段放在顶层,而 data 中只包含变更后的数据。
- 如果需要调整字段的位置或结构,必须通过自定义逻辑实现。
- 文档中未提到任何内置功能可以直接将顶层字段(如
ts 和 type)嵌入到 data 中。
2. 可能的解决方案
如果需要实现将 ts 和 type 字段复制到 data 中,可以考虑以下方法:
方法一:使用 Debezium 或 Maxwell 序列化方式
-
Debezium 和 Maxwell 是两种支持更灵活消息格式的序列化方式。
- 尝试切换到 Debezium 或 Maxwell 序列化方式,并检查其输出格式是否更接近您的需求。
- 如果仍然无法满足需求,可以结合下游消费端进行二次处理。
方法二:在 Kafka 消费端进行数据结构调整
- 在 Kafka 消费端编写逻辑,将
ts 和 type 字段从顶层提取并嵌入到 data 中。
- 示例代码(Python 实现):
import json
def transform_message(message):
# 解析原始消息
original_data = json.loads(message)
# 提取 ts 和 type 字段
ts = original_data.get("ts")
type_field = original_data.get("type")
# 获取 data 字段
data = original_data.get("data", [])
# 将 ts 和 type 嵌入到 data 中
for item in data:
item["ts"] = ts
item["type"] = type_field
# 返回调整后的消息
return json.dumps(original_data)
# 示例调用
original_message = '''
{
"database": "ftsp_pre",
"es": 1744710622000,
"id": 137578,
"isDd1": false,
"mysqlType": null,
"old": [
{"create_date_": "2024-05-28 0@:43:56.037"}
],
"pkNames": ["id"],
"sql": null,
"sqlType": null,
"ts": 1744710622000,
"type": "INSERT",
"data": [
{"id_": "h6888889888888794229362289841488"}
]
}
'''
transformed_message = transform_message(original_message)
print(transformed_message)
方法三:自定义 OMS 插件(高级)
- 如果上述方法无法满足需求,可以尝试开发自定义插件以扩展 OMS 的功能。
- 自定义插件需要对 OMS 的源码有一定了解,并且可能涉及较高的开发成本。
3. 总结
根据现有文档,OMS 社区版并未提供直接的配置选项来实现将 ts 和 type 字段复制到 data 中的功能。建议优先考虑在 Kafka 消费端进行数据结构调整,这是一种简单且高效的方式。如果需要更深层次的定制,可以探索自定义插件的开发。
如果您对以上方案有任何疑问,或者需要进一步的技术支持,请联系 OceanBase 的人工答疑团队以获取更多帮助。
更多信息请查看:
- 创建 OceanBase 社区版至 Kafka 的数据同步任务
- 通过 OMS 进行数据迁移和同步
- 新建 Kafka 数据源
- KafkaSource(TiDB)
- KafkaSink
- 增量数据同步到 Kafka 的顺序问题
- 数据格式说明
淇铭
#5
“将 ts 和 type 字段复制到 data 中”这个输出格式调整oms应该是不支持的
论坛小助手
#6
根据文档库中的信息,OMS 社区版并未详细描述如何开发自定义插件。然而,基于对 OMS 的架构理解以及常见的插件开发模式,以下是一个可能的实现路径和步骤。请注意,这需要一定的开发经验和对 OMS 源码的理解。
1. 了解 OMS 插件机制
- OMS 是一个模块化设计的系统,支持通过插件扩展功能。
- 插件通常用于实现特定的数据格式转换、数据过滤或其他定制化需求。
- 开发插件前,建议熟悉 OMS 的源码结构和插件加载机制。
2. 开发自定义插件的步骤
步骤一:获取 OMS 源码
- 下载 OMS 社区版的源码(如果可用)。
- 如果无法直接获取源码,可以参考官方文档或联系 OceanBase 技术支持团队以获取更多信息。
步骤二:定义插件功能
- 明确插件的目标功能。例如:
- 修改数据投递到 Kafka 的格式。
- 将
ts 和 type 字段嵌入到 data 中。
步骤三:编写插件代码
- 插件通常以 Java 或其他支持的语言实现。
- 示例代码框架(Java 实现):
public class CustomDataFormatterPlugin implements DataFormatterPlugin {
@Override
public String formatMessage(String originalMessage) {
// 解析原始消息
JSONObject message = new JSONObject(originalMessage);
// 提取 ts 和 type 字段
Long ts = message.optLong("ts");
String type = message.optString("type");
// 获取 data 字段
JSONArray data = message.optJSONArray("data");
// 将 ts 和 type 嵌入到 data 中
if (data != null) {
for (int i = 0; i < data.length(); i++) {
JSONObject item = data.getJSONObject(i);
item.put("ts", ts);
item.put("type", type);
}
}
// 返回调整后的消息
return message.toString();
}
}
步骤四:打包插件
- 将插件代码打包为 JAR 文件。
- 确保 JAR 文件中包含插件的主类和依赖项。
步骤五:部署插件
步骤六:测试插件
- 启动 OMS,并验证插件是否生效。
- 检查 Kafka 中的消息格式是否符合预期。
3. 注意事项
-
源码访问权限:如果无法获取 OMS 源码,可能需要联系 OceanBase 技术支持团队以获取更多帮助。
-
插件兼容性:确保插件与当前 OMS 版本兼容。
-
性能影响:自定义插件可能会对系统性能产生一定影响,建议在测试环境中充分验证。
4. 总结
目前 OMS 社区版并未提供详细的插件开发文档。如果您具备一定的开发经验,可以通过上述步骤尝试开发自定义插件。如果遇到困难,建议联系 OceanBase 的技术支持团队以获取进一步的帮助。
如果您对以上方案有任何疑问,请随时提出!
详情请参考:
- 关联 OCP
- 设置个人信息
- 修改高可用功能的配置
- 下载和导入迁移对象配置
- StoreSource
- 更新 Store 组件
- 管理控制台介绍
- 如何更新黑白名单
- 查看和修改同步对象
- 更新 Full-Import 组件
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
老师,我看论坛小助手好像可以通过插件的方式进行调整?