皇甫侯
2025 年4 月 17 日 10:58
#1
【 使用环境 】生产环境 or 测试环境
【复现路径】问题出现前后相关操作
【SOP系列 22 】——故障诊断第一步(自助诊断和诊断信息收集)
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手 ] 即可召唤小助手,欢迎试用!
论坛小助手
2025 年4 月 17 日 10:59
#3
根因分析场景: SQL 执行出错
日志采集场景: SQL性能问题
为了更好地帮助您解决问题,请您按照上述命令进行日志采集,并将生成的日志压缩包提供给我们。此外,还需要您提供以下信息:
能否提供具体的 trace_id 以及对应的 SQL 语句?这有助于我们更准确地定位问题。
observer.log 文件的路径是什么?是否确认该文件为最新的日志文件?
调整 syslog_io_bandwidth_limit 参数后,是否重启了相关服务以使配置生效?
当前集群的版本号是多少?不同版本可能存在不同的行为表现。
是否有其他参数调整或系统变更操作与问题发生时间点重合?如果有,请详细描述。
附上敏捷诊断工具 obdiag 使用帮助链接
淇铭
2025 年4 月 17 日 11:07
#4
是不是给设置的日志级别有关系 有的日志信息未打印 或者在其他节点 或者日志被覆盖了
1 个赞
sql_audit这条SQL对应的svr_ip机器上查的日志吗
皇甫侯
2025 年4 月 17 日 14:06
#6
我都是默认的WDIAG级别,SQL执行的节点都搜不到。。我搜的不光是当前的observer,包括前几分钟都搜了
论坛小助手
2025 年4 月 17 日 14:09
#8
根据您的描述,问题可能与日志级别、日志采集范围或 trace_id 的生成机制有关。以下是可能的原因及解决方法:
确认日志级别
默认的日志级别为 WDIAG,但某些 SQL 执行信息可能未被记录到此级别中。
您可以尝试将日志级别临时调整为更详细的级别(如 DIAG 或 DEVELOP),以捕获更多细节。
操作步骤:
-- 设置全局日志级别为 DIAG
ALTER SYSTEM SET log_level='DIAG';
注意事项:
确认 trace_id 的生成与传播
检查点:
如果 trace_id 为空或不一致,可能是 SQL 执行过程中存在问题,例如网络异常或分布式事务未正确传播 trace_id。
确认日志采集范围
确保您搜索的日志文件是正确的 observer 节点的日志,并且覆盖了 SQL 执行的时间段。
使用 obdiag 工具采集相关节点的日志,确保采集范围包括所有可能执行该 SQL 的 observer 节点。
示例命令:
obdiag gather log --start-time="2024-03-01 10:00:00" --end-time="2024-03-01 11:00:00" --scope=observer --target-dir=/path/to/save/logs
排查其他可能原因
SQL 并行执行 :如果 SQL 使用了并行执行计划,trace_id 可能分布在多个 observer 节点上。请参考文档片段《并行执行问题诊断 → SQL 诊断 → 确认 SQL 还在执行并行查询》中的视图 GV$OB_PX_WORKER_STAT 查看并行线程的分布情况。
日志滚动或清理 :如果日志文件已被滚动或清理,可能导致无法找到相关信息。请确认日志保留策略是否合理。
进一步诊断建议
您的问题可能存在以下几种情况:
日志级别不足,导致关键信息未被记录。
trace_id 生成或传播异常,导致无法匹配到相关日志。
日志采集范围不完整,遗漏了部分 observer 节点的日志。
请按照上述步骤逐一排查,并提供更多信息以便进一步分析。如果仍有疑问,建议联系 OceanBase 技术支持团队获取专业帮助。
更多信息请查看:
并行执行问题诊断 监控索引 enable_sql_plan_monitor SQL 基础操作(MySQL 模式) 分布式执行和并行查询 查看节点 主键操作 监控告警 查询排名 TOP N 的 SQL oceanbase.DBA_OBJECTS
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
淇铭
2025 年4 月 17 日 14:44
#9
obclient [test]> select count() from test2; ) |
obclient [test]> select last_trace_id();
obclient [test]> select * from oceanbase.gv$ob_sql_audit where trace_id=‘YB420BA1CC68-000615A0A8EA6511-0-0’;
[root@x.x.x.x ~]$ grep “YB420BA1CC68-000615A0A8EA6511-0-0” rootservice.log
皇甫侯
2025 年4 月 17 日 17:06
#10
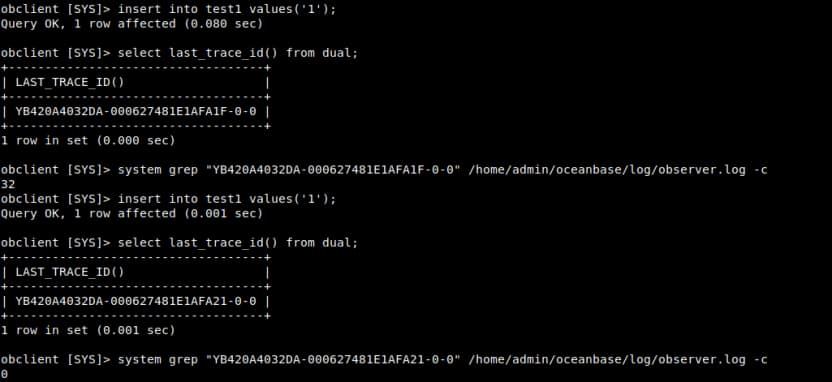
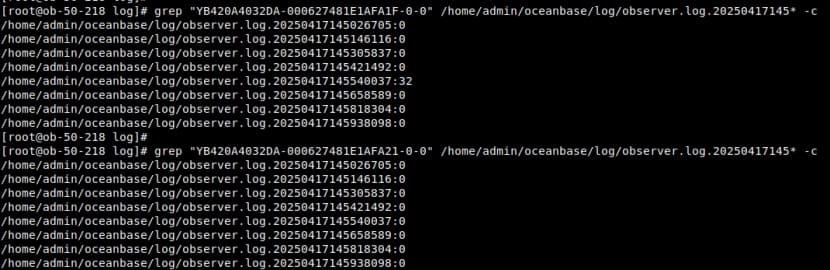
下面我这个就比较具体了,第一条insert找到的trace_id在日志中能搜到,第二条insert的trace_id在日志中就搜不到