【 使用环境 】 测试环境
【 OB or 其他组件 】
【 使用版本 】
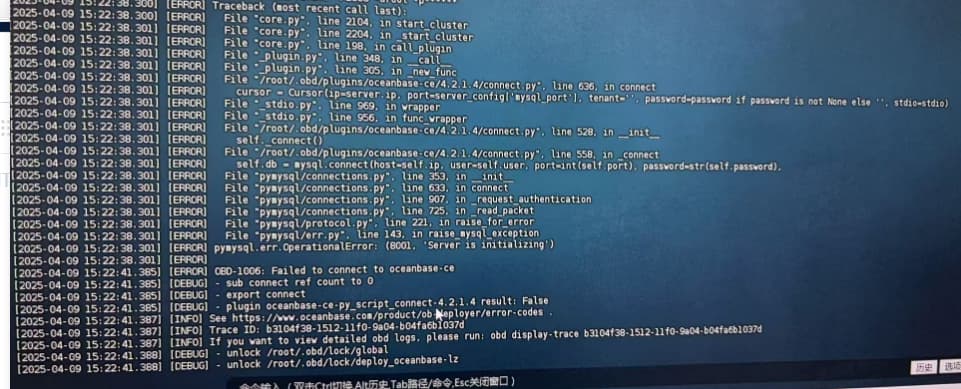
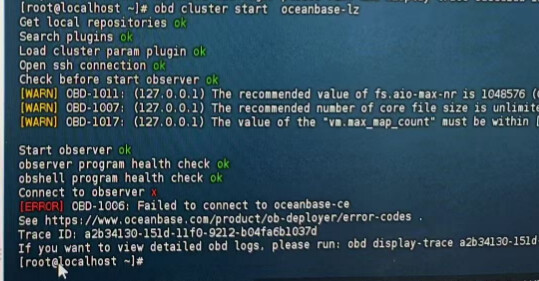
【问题描述】重启oceanbase前先stop了节点,然后再start节点,start一直在尝试连接数据库,最后启动失败
【复现路径】问题出现前后相关操作
【附件及日志】
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
【 使用环境 】 测试环境
【 OB or 其他组件 】
【 使用版本 】
【问题描述】重启oceanbase前先stop了节点,然后再start节点,start一直在尝试连接数据库,最后启动失败
【复现路径】问题出现前后相关操作
【附件及日志】
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
麻烦提供一份observer日志
日志采集场景: 集群无法连接
日志采集命令: obdiag gather scene run --scene=observer.cluster_down
推荐使用 obdiag 工具进行日志采集,并且将采集到的日志提供给我们以便确认问题所在。通过该命令,可以收集到与集群启动失败相关的日志信息,帮助我们定位问题原因。
另外,为了确定具体的问题,在此需要您提供一些信息:
附上敏捷诊断工具 obdiag 使用帮助链接
根据您提供的日志信息,以下是问题的分析和可能的解决方案:
从日志中可以看到以下关键信息:
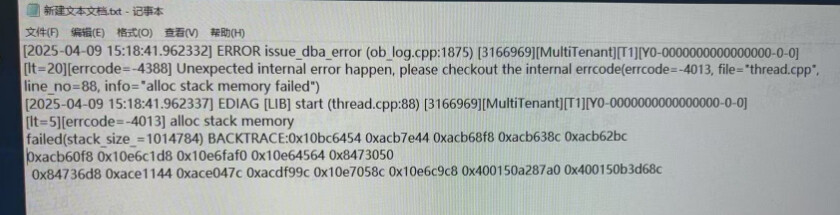
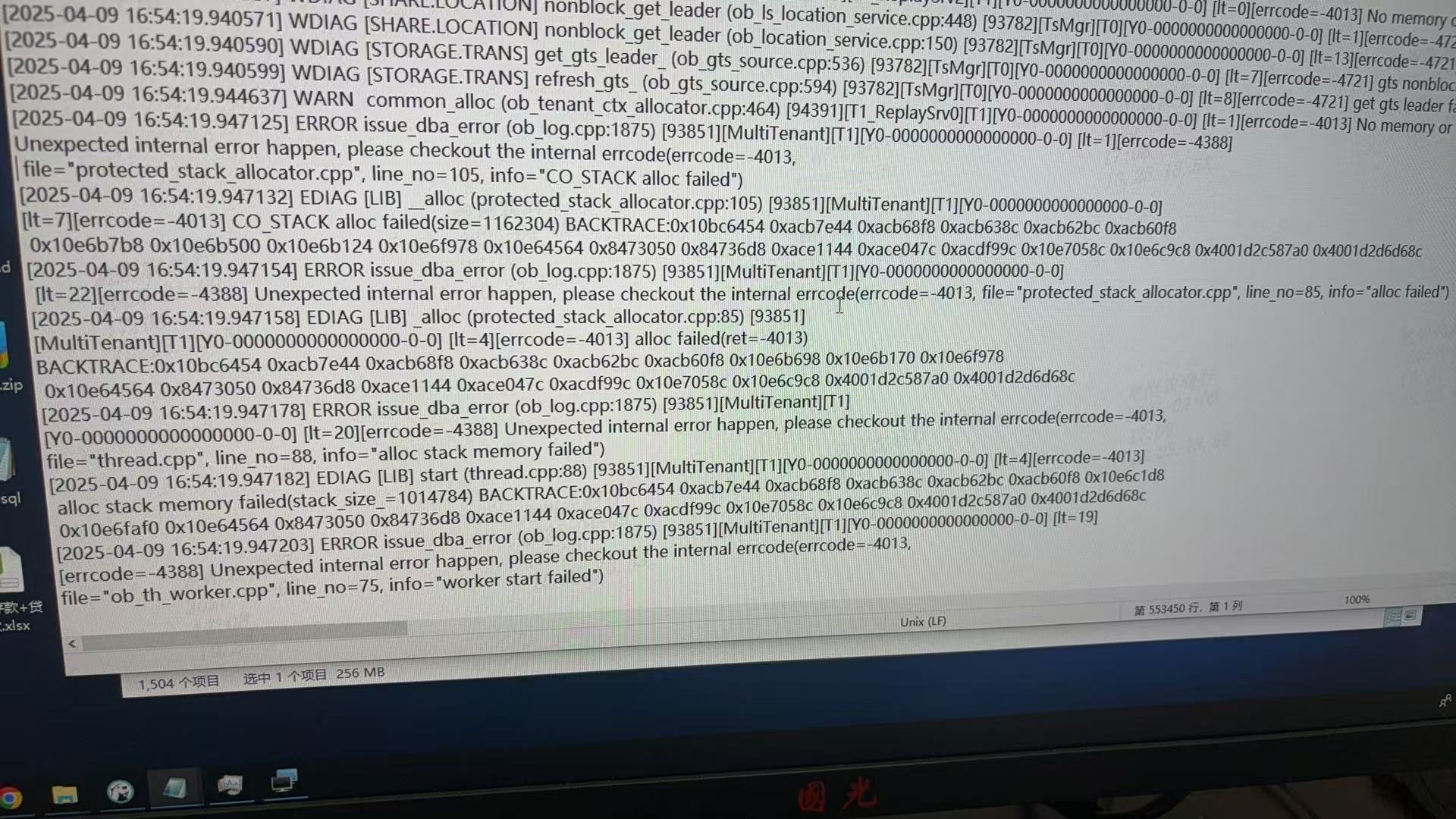
错误代码 -4013:
[errcode=-4013] alloc stack memory failed(stack size -1014784)
这表明在启动 OceanBase 节点时,分配栈内存失败。具体原因是尝试分配的栈大小为 -1014784(负值),这显然是不合理的。
内部错误提示:
Unexpected internal error happen, please checkout the internal errcode(errcode=-4013, file="thread.cpp", line_no=88, info="alloc stack memory failed")
这进一步确认了问题与内存分配有关。
时间戳:
日志的时间戳为 [2025-04-09 15:18:41.962337],虽然年份可能是 OCR 提取错误(应该是 2023 或其他合理年份),但可以确定问题发生在节点启动过程中。
根据上述日志信息,以下是可能导致该问题的原因:
系统资源不足:
节点所在的服务器可能存在内存不足的情况,导致无法成功分配栈内存。
配置文件错误:
OceanBase 的配置文件中可能设置了不合理的线程栈大小参数(如 __ob_thread_stack_size),导致分配失败。
环境变量冲突:
系统环境变量中可能设置了与 OceanBase 不兼容的参数(如 ULIMIT 或 THREAD_STACK_SIZE),影响了内存分配。
硬件或操作系统问题:
如果服务器存在硬件故障(如内存损坏)或操作系统层面的问题(如内核限制),也可能导致此类错误。
free -m
top
config.ini 或通过 OBD 配置),确认是否存在以下参数:__ob_thread_stack_size = <合理值>
2MB。如果配置了过小或负值的栈大小,可能会导致分配失败。echo $ULIMIT
echo $THREAD_STACK_SIZE
obdiag 工具收集详细的日志信息,以便进一步分析问题:obdiag gather scene run --scene=observer.cluster_down
如果按照上述步骤仍无法解决问题,请提供以下信息以便进一步排查:
希望以上信息对您有所帮助!如果还有其他问题,请随时联系 OceanBase 的技术支持团队。
具体信息可参考以下文档:
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
提供一份附件日志,目前仅看出内存分配有问题需要根据上下文分析下
free -g看一下当前内存使用情况
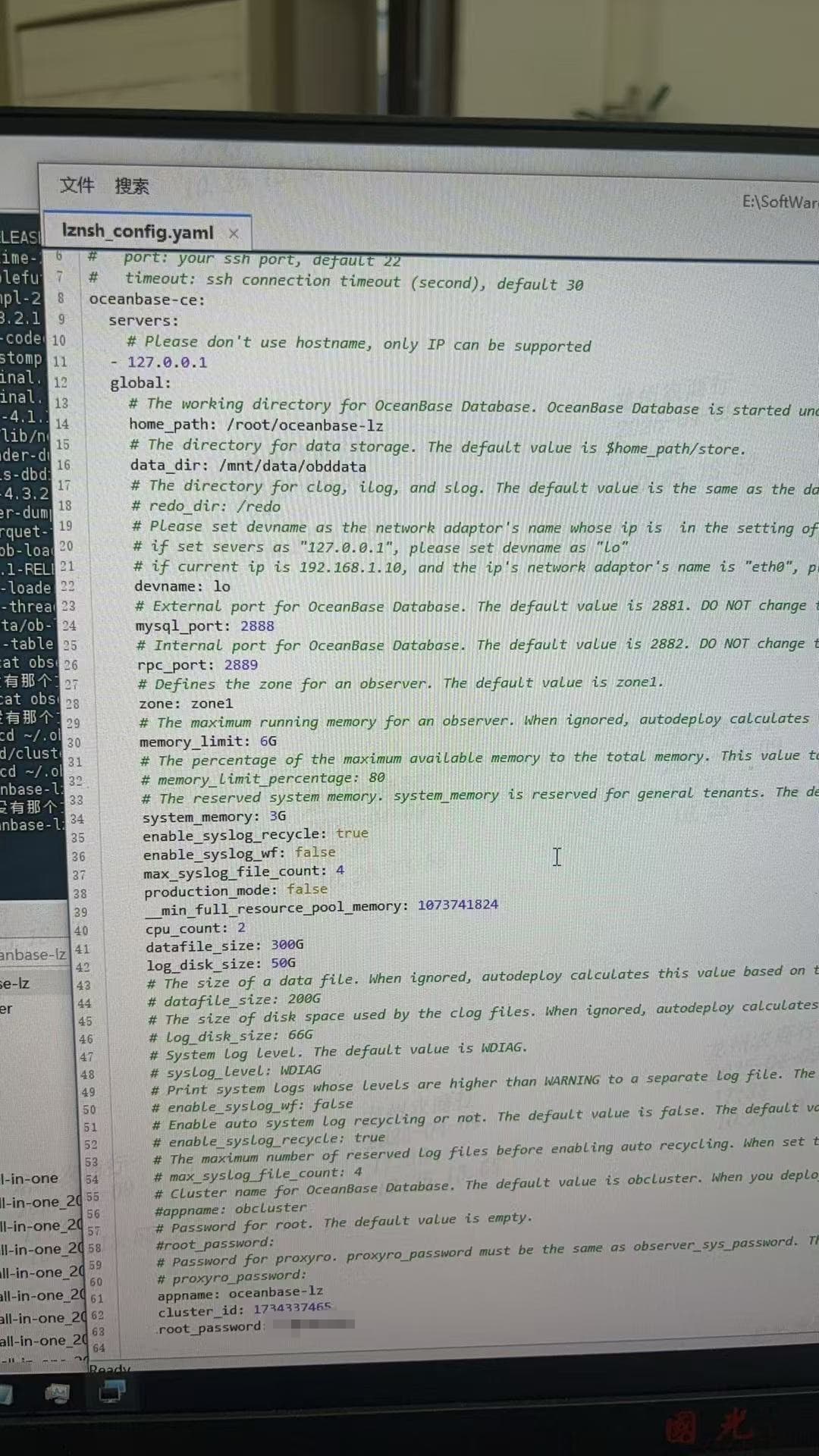
提供一份yaml文件 ~/.obd/cluster/xxxx/
日志不太方便拿出来么,麻烦cat observer.log |grep NOTICE 看一下
system_memory设置的太大了,如参考最小规格配置的集群mystem_memory建议设置为1G
试试使用带参启动方法
cd ~/oceanbase-lz/oceanbase
./bin/observer -o “system_memory=1G”
./bin/observer -o “system_memory=1G”
带参数启动如果成功了,使用obd cluster edit-config 修改该参数为1.然后执行reload来让参数生效