【 使用环境 】生产环境 or 测试环境
测试环境
【 OB or 其他组件 】
observer
【 使用版本 】
4.2.1
【问题描述】清晰明确描述问题
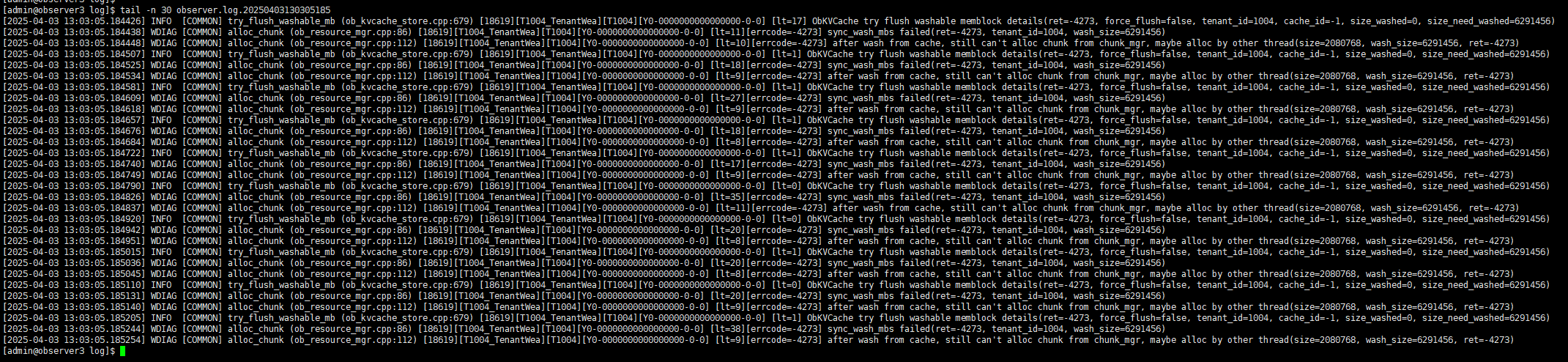
测试环境使用五台机器搭建了一个集群,一台 obd,一台 obproxy,三台 observer。
其中 observer3 一直因为 cache wash 申请不到内存而停止服务。重启进程后,大概两三个小时就又重复出现该问题。
observer 进程启动命令:
/data/oceanbase_servers/observer/bin/observer -p 2881 -P 2882 -z zone3 -n obcluster -c 1 -d /data/oceanbase_data -i eth0 -o memory_limit=10G,system_memory=2G,datafile_size=50G,log_disk_size=50G,cpu_count=6
服务器为 8核,16G 虚拟机。
【复现路径】问题出现前后相关操作
集群搭建好后,创建了一个租户,然后什么都没做,observer3 就出现该问题,其他两台机器正常。
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【SOP系列 22 】——故障诊断第一步(自助诊断和诊断信息收集)
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召
唤小助手,欢迎试用!
2 个赞
论坛小助手
#3
根因分析场景: 内存问题
根因分析命令: 无(当前 obdiag 工具未提供针对内存问题的特定根因分析场景)
日志采集场景: 内存问题
日志采集命令: obdiag gather scene run --scene=observer.memory
为了更好地帮助您定位和解决问题,建议您使用上述 obdiag 命令采集相关日志并提供给我们。此命令将收集与内存相关的诊断信息,以便我们进一步分析 observer3 节点频繁因 cache wash 无法申请到内存而拒绝服务的问题。
另外,为了更全面地了解问题,请您提供以下信息:
- observer3 节点的具体配置(如内存大小、CPU 核心数等),以及该节点在集群中的角色是什么?
- 是否有其他节点也出现类似问题?如果有,请描述这些节点的表现情况。
- 当前集群的负载情况如何?是否有大查询或高并发操作导致内存压力增大?
- 错误代码 -4273 出现的频率是怎样的?是持续发生还是间歇性出现?
- 测试环境中是否最近进行了任何配置变更或升级操作?如果有,请详细说明变更内容。
附上敏捷诊断工具 obdiag 使用帮助链接
1 个赞
observer3 节点为 8核,16G 配置,该节点在集群中为 follower
运行 obdiag 命令:obd obdiag gather scene run obcluster --scene=observer.memory
shell_result.txt
shell_result.txt (1.4 MB)
sql_result.txt
sql_result.txt (28.4 KB)
1 个赞
论坛小助手
#6
根据您提供的日志和诊断信息,以下是针对 observer3 节点频繁因 cache wash 无法申请到内存而拒绝服务问题的分析与建议:
问题分析
-
错误代码 -4273 的含义
错误代码 -4273 表示 sync_wash_mbs failed,即在尝试清理缓存时失败。具体表现为:observer3 节点无法为缓存清洗分配足够的内存资源。
-
节点角色与配置
- observer3 节点在集群中为 follower 角色。
- 配置为 8 核、16GB 内存,启动参数中设置了
memory_limit=10G 和 system_memory=2G。
- 根据日志中的
dump tenant info 输出,系统租户(tenant_id=1)的内存配置为 memory_size="2GB"。
-
内存压力来源
- observer3 节点作为 follower,可能承担了较多的写入或读取任务,导致内存使用率较高。
- 日志显示
size need_washed=6291456,即需要清洗的缓存大小为 6MB,但未能成功分配内存。
-
集群状态
- 从
DBA_OB_ZONES 和 DBA_OB_SERVERS 查询结果来看,所有 zone 和 server 均处于 ACTIVE 状态。
- observer3 节点(zone3)与其他节点无明显差异。
可能原因
-
内存分配不足
- 当前 observer3 节点的内存限制为 10GB,其中系统内存(
system_memory)占用了 2GB,剩余可用内存为 8GB。
- 如果集群负载较高或存在大查询,可能导致内存资源紧张,进而引发 cache wash 失败。
-
缓存策略问题
- OceanBase 的缓存机制会定期清理不常用的内存块(memblock)。如果缓存清洗频率过高或内存回收效率低下,可能会导致内存分配失败。
-
follower 节点的特殊性
- follower 节点需要同步 leader 的数据变更,并维护本地副本。如果 follower 节点的性能或资源不足,可能会加剧内存压力。
解决方案
短期措施
-
调整内存配置
- 增加 observer3 节点的
memory_limit 和 system_memory 参数,例如:/data/oceanbase_servers/observer/bin/observer -p 2881 -P 2882 -z zone3 -n obcluster -c 1 -d /data/oceanbase_data -i eth0 -o memory_limit=12G,system_memory=3G,datafile_size=50G,log_disk_size=50G,cpu_count=6
- 重启 observer3 节点以使配置生效。
-
监控内存使用情况
-
优化缓存策略
长期措施
-
均衡资源分配
-
升级硬件资源
- 如果 observer3 节点的内存压力持续较高,建议升级其硬件配置(如增加内存至 32GB)。
-
优化查询与应用
- 检查是否存在大查询或高并发操作,优化 SQL 语句以减少内存占用。
- 使用 OCP 或 ODC 工具监控集群性能,及时发现并解决潜在问题。
后续建议
-
定期收集诊断信息
- 使用
obdiag 工具定期采集内存相关的诊断信息,以便及时发现异常。
-
联系技术支持
- 如果问题仍未解决,建议联系 OceanBase 官方技术支持团队,提供完整的日志和诊断信息以获取进一步帮助。
希望以上建议能有效解决您的问题!如果有其他疑问,请随时告知。
检索到的文档如下:
- 替换节点
- 查看按表恢复进度
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
1 个赞
observer3 的节点日志:
observer3.log (9.0 MB)
1 个赞
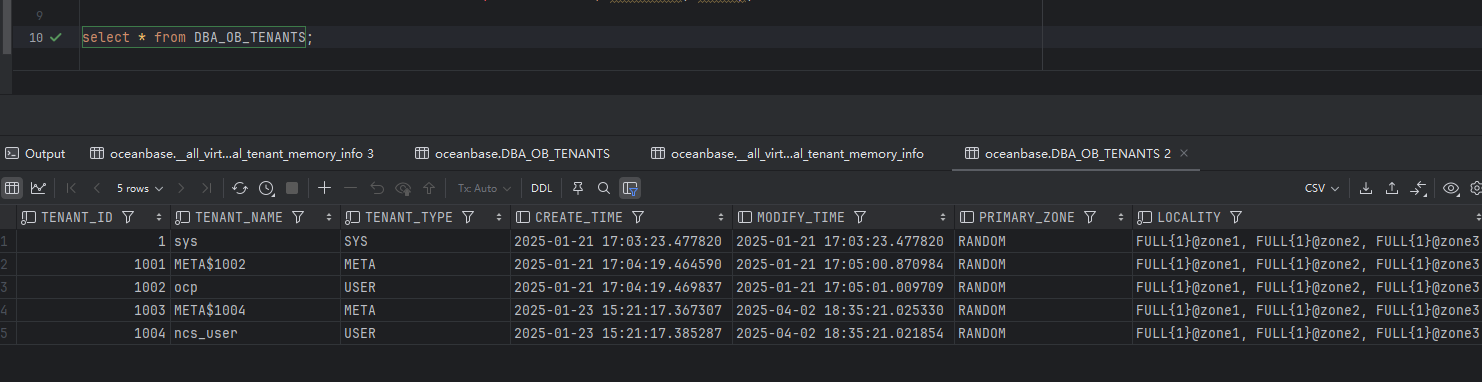
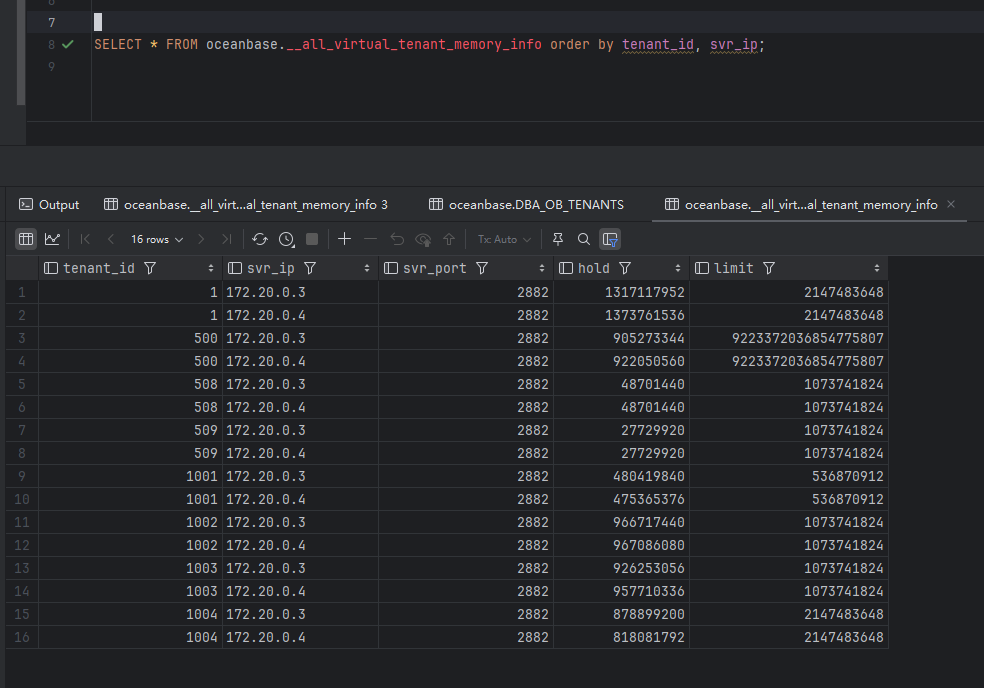
根据小助手提供的思路,查了一下内存,发现有一个 500 租户,没有做内存限制。
请问 500 是什么租户呀,租户列表中也查不到。
1 个赞
辞霜
#9
ob除sys和业务租户外所使用的内存统一划分到500虚拟租户下
1 个赞
辞霜
#11
这个无法限制。你的500租户内存使用不多 麻烦提供一份yaml文件
1 个赞
辞霜
#12
显示你的三节点在集群中处于异常状态。三节点没有拉起来。
你拉起ob集群的命令是啥
ob集群是运维拉起来的,应该是 obd cluster start 拉起来的。
集群起来后是正常的,运行一段时间后,第三节点在 gv$ob_servers 视图中就没有了,但是进程还在,日志里一直报 cache wash 申请不到内存的错误。
kill -9 进程后,用上面的命令把进程重新拉起来,gv$ob_servers 视图就可以看到所有节点了。
1 个赞
辞霜
#15
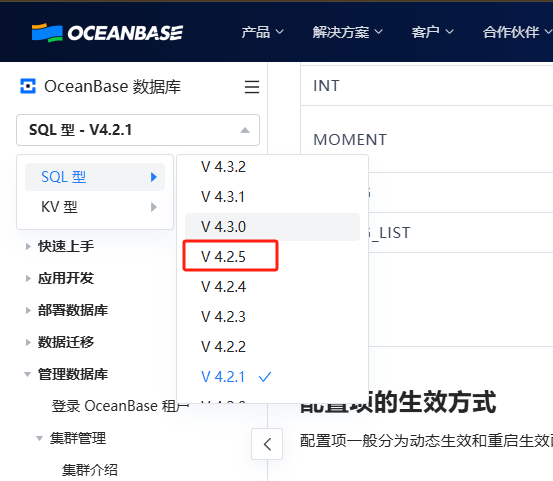
当前仅是部署测试吧? 更换新版本吧 建议使用425bp2
当前ocp-express不维护了,根据你的规模,建议你部署单机ocp+3zone ob+obporxy
1 个赞
425bp2 对应哪个版本?
是 v4.2.5 吗?
1 个赞
这个 tenantSchemMgr 是什么服务呀,这么占内存
发现是 SCHEMA_SERVICE 的 TenantSchemMgr 一直不停的在申请内存,最后导致申请不到内存而拒绝服务。
但是整个集群是空闲的,不明白为什么这个服务这么占内存。
最后尝试把 ocp 租户删掉,解决了这个问题。
请问有大佬知道 ocp 租户为什么这么占内存吗?