【 使用环境 】生产环境 or 测试环境
【 OB or 其他组件 】
【 使用版本 】
【问题描述】清晰明确描述问题
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
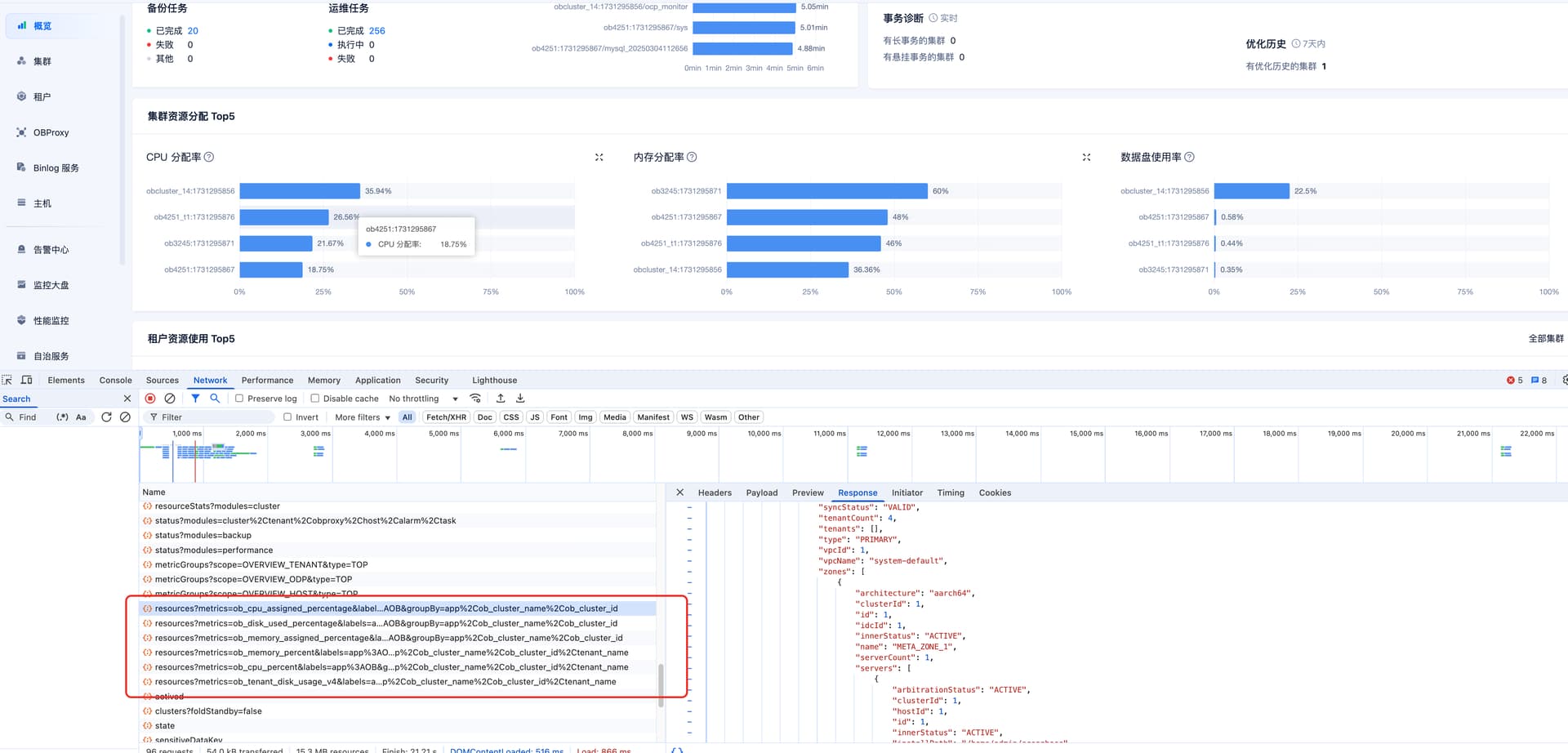
问题:如何用一条SQL 得到 ocp 页面管理各个集群的cpu,内存,数据盘 资源分配率?
【 使用环境 】生产环境 or 测试环境
【 OB or 其他组件 】
【 使用版本 】
【问题描述】清晰明确描述问题
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
问题:如何用一条SQL 得到 ocp 页面管理各个集群的cpu,内存,数据盘 资源分配率?
根据文档库中的信息,OCP(OceanBase Control Platform)提供了图形化的界面来管理和监控OceanBase集群的资源使用情况,包括CPU、内存和磁盘使用率。但是直接通过一条SQL查询来获取这些信息并不是标准的做法,因为这些数据通常是由OCP内部的监控系统收集并展示的。
然而,如果您确实需要通过SQL来获取类似的信息,您可以查询OceanBase数据库中的一些系统表或视图,例如gv$unit、gv$resource_pool等,这些表包含了关于资源池和单元的配置及使用情况的数据。但请注意,这可能不会完全等同于OCP界面上展示的内容,因为OCP可能会进行额外的计算和汇总。
对于具体的SQL语句,这里提供一个基于社区版的示例,它可以帮助您了解各个集群的资源使用情况:
SELECT
tenant_name AS "租户名称",
zone AS "Zone",
svr_ip AS "服务器IP",
ROUND(SUM(cpu_limit) / COUNT(*) , 2) AS "CPU分配量",
ROUND(SUM(mem_limit)/(1024*1024*1024), 2) AS "内存分配量(GB)",
ROUND(SUM(disk_size_used)/(1024*1024*1024), 2) AS "已用磁盘空间(GB)",
ROUND(SUM(disk_size_total)/(1024*1024*1024), 2) AS "总磁盘空间(GB)",
ROUND(SUM(disk_size_used)/SUM(disk_size_total)*100, 2) AS "磁盘使用率(%)"
FROM
gv$unit
GROUP BY
tenant_name, zone, svr_ip;
这段SQL将返回每个租户在不同Zone下的每台服务器上的CPU、内存以及磁盘的分配与使用情况。请注意,实际环境中可能还需要根据您的具体需求调整字段选择和聚合方式。
为了确保准确性,并且考虑到生产环境的安全性和稳定性,请先在测试环境中验证此SQL的效果。如果需要更精确地匹配OCP页面上的数据显示,建议参考官方提供的API接口或者联系OceanBase技术支持团队以获得进一步的帮助。
以上信息来源于对多个文档片段的理解综合,特别是有关性能监控的部分。如果您有特定版本或其他组件的要求,请提供更多详细信息以便给出更加准确的答案。
检索到的文档如下:
推荐一个诊断工具obdiag 的一键洞察功能,一条命令就能看到集群的各种信息,加-v还能看到执行SQL
obdiag display scene run --scene=observer.cluster_info
...
+-----------------------+--------------------------+
| stat_name | value |
+-----------------------+--------------------------+
| cluster_name | obcluster |
| cluster_id | 1 |
| version | 4.2.2.0 |
| observers | 1 |
| zones | 1 |
| tenants | 3 |
| rs_list | xx.xx.xx.xx:2882:2881 |
| config_url | |
| memory_limit | 24.00G |
| data_disk_allocated | 56.00G |
| cpu_total | 16 |
| cpu_assigned | 12 |
| cpu_assinged_per | 75% |
| memory_total | 20.00G |
| memory_assigned | 19.00G |
| memory_assigned_per | 95.00% |
| log_disk_total | 84.00G |
| log_disk_assigned | 8.00G |
| log_disk_assigned_per | 10.00% |
| log_disk_in_use | 6.50G |
| log_disk_in_use_per | 81.00% |
| data_disk_total | 56.00G |
| data_disk_in_use | 23.69G |
| data_disk_in_use_per | 42.00% |
+-----------------------+--------------------------+
Trace ID: f1b0206e-8878-11ef-a52e-00163e01c7ce
文档:https://www.oceanbase.com/docs/common-obdiag-cn-1000000002200489
相关的sql可以从~/…obdiag/display/tasks/observer下查看到
工具不好用,SQL直观点,报错不断
[root@zhobtest10 tmp]# obdiag display scene run --scene=observer.cluster_info \
--config db_host=1.1.28.195 \ --config db_port=2883 \ --config tenant_sys.user=root@sys \ --config tenant_sys.password='1'
display_scenes_run start …
execute tasks: observer.cluster_info
[WARN] node is not exist
Trace ID: 154ab782-f999-11ef-b563-e8611f45ae64
If you want to view detailed obdiag logs, please run: obdiag display-trace 154ab782-f999-11ef-b563-e8611f45ae64
[root@zhobtest10 tmp]#
[root@zhobtest10 tmp]#
[root@zhobtest10 tmp]# obdiag display-trace 154ab782-f999-11ef-b563-e8611f45ae64
[2025-03-05 16:08:55.434] [DEBUG] - cmd: obdiag display scene run
[2025-03-05 16:08:55.434] [DEBUG] - opts: {‘inner_config’: None, ‘scene’: ‘observer.cluster_info’, ‘from’: None, ‘to’: None, ‘since’: ‘30m’, ‘env’: None, ‘c’: ‘/root/.obdiag/config.yml’, ‘config’: [‘db_host=1.1.28.195’, ‘db_port=2883’, ‘tenant_sys.user=root@sys’, ‘tenant_sys.password=1’]}
[2025-03-05 16:08:55.435] [DEBUG] - mkdir /usr/local/oceanbase-diagnostic-tool/conf/inner_config.yml
[2025-03-05 16:08:55.444] [INFO] display_scenes_run start …
[2025-03-05 16:08:58.528] [DEBUG] - start get_observer_version_by_sql . input: 1.1.28.195:2883
[2025-03-05 16:08:58.534] [DEBUG] - connect databse …
[2025-03-05 16:08:58.539] [DEBUG] - get_observer_version_by_sql ob_version_info is (‘5.7.25-OceanBase-v4.2.1.8’,)
[2025-03-05 16:08:58.545] [DEBUG] - connect databse …
[2025-03-05 16:08:58.552] [DEBUG] - get host info: [{‘ip’: ‘1.1.28.194’}, {‘ip’: ‘1.1.28.195’}, {‘ip’: ‘1.1.28.196’}]
[2025-03-05 16:08:58.552] [DEBUG] - update nodes config: [{‘ip’: ‘1.1.28.194’}, {‘ip’: ‘1.1.28.195’}, {‘ip’: ‘1.1.28.196’}]
[2025-03-05 16:08:58.558] [DEBUG] - connect databse …
[2025-03-05 16:08:58.559] [DEBUG] - display scene variables: {‘observer_data_dir’: ‘’, ‘obproxy_data_dir’: ‘’, ‘from_time’: ‘2025-03-05 15:38:58’, ‘to_time’: ‘2025-03-05 16:09:58’}
[2025-03-05 16:08:58.598] [DEBUG] - execute_tasks. the number of tasks is 1 ,tasks is dict_keys([‘observer.cluster_info’])
[2025-03-05 16:08:58.599] [INFO] execute tasks: observer.cluster_info
[2025-03-05 16:08:58.599] [DEBUG] - get observer version, by sql
[2025-03-05 16:08:58.599] [DEBUG] - start get_observer_version_by_sql . input: 1.1.28.195:2883
[2025-03-05 16:08:58.604] [DEBUG] - connect databse …
[2025-03-05 16:08:58.608] [DEBUG] - get_observer_version_by_sql ob_version_info is (‘5.7.25-OceanBase-v4.2.1.8’,)
[2025-03-05 16:08:58.608] [DEBUG] - observer.cluster_info execute!
[2025-03-05 16:08:58.609] [DEBUG] - version_int is 4.2.1.8 steps_versions is [4.2.0.0, *]
[2025-03-05 16:08:58.609] [DEBUG] - minVersion is 4.2.0.0, maxVersion is 999
[2025-03-05 16:08:58.609] [DEBUG] - filter_by_version is return 0
[2025-03-05 16:08:58.609] [WARNING] node is not exist
[2025-03-05 16:08:58.609] [DEBUG] - execute tasks end : observer.cluster_info
[2025-03-05 16:08:58.609] [INFO] Trace ID: 154ab782-f999-11ef-b563-e8611f45ae64
[2025-03-05 16:08:58.609] [INFO] If you want to view detailed obdiag logs, please run: obdiag display-trace 154ab782-f999-11ef-b563-e8611f45ae64
API 后台应该是OCP 管理库吧
根据您提供的信息和日志,obdiag display scene run --scene=observer.cluster_info 命令在执行时遇到了问题,具体表现为“node is not exist”的警告。这通常意味着 obdiag 工具无法找到指定的节点信息,可能是由于配置错误或网络连接问题导致。
检查配置参数:
db_host 和 db_port 是否正确指向了您的 OceanBase 数据库实例。tenant_sys.user 和 tenant_sys.password 是否为正确的系统租户用户名和密码。验证数据库连接:
mysql -h 1.1.28.195 -P 2883 -u root@sys -p
确认集群状态:
检查 obdiag 日志:
obdiag display-trace 154ab782-f999-11ef-b563-e8611f45ae64
确认场景配置:
observer.cluster_info 场景是否适用于您的 OceanBase 版本(v4.2.1.8)。虽然从日志来看版本匹配是成功的,但仍然建议查阅官方文档或支持渠道确认该场景的具体要求。API 后台与 OCP:
gv$unit, gv$resource_pool 等)。为了更准确地诊断问题,请先按照上述步骤逐一排查可能的原因。如果问题依然存在,建议收集更多的诊断信息并联系 OceanBase 技术支持团队获取帮助。同时,确保您使用的 obdiag 版本是最新的,因为更新版本可能修复了已知的问题。
如果您有更多具体的配置细节或其他相关日志信息,欢迎提供,以便我们能够更好地帮助您解决问题。
具体信息可参考以下文档:
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
谢谢,这个目录下的SQL 已经看到,虽然没有我想要的,但是仍然很重要
抱歉给你带来了不好的使用体验,已确认是obdiag 在无配置文件场景obdiag display scene run --scene=observer.cluster_info 存在bug。下周发布的3.2.0 版本会修复这个问题。
感谢反馈
学习学习
SELECT tenant_name AS “租户名称”, zone AS “Zone”, svr_ip AS “服务器IP”, ROUND(SUM(cpu_limit) / COUNT() , 2) AS “CPU分配量”, ROUND(SUM(mem_limit)/(102410241024), 2) AS “内存分配量(GB)”, ROUND(SUM(disk_size_used)/(102410241024), 2) AS “已用磁盘空间(GB)”, ROUND(SUM(disk_size_total)/(10241024*1024), 2) AS “总磁盘空间(GB)”, ROUND(SUM(disk_size_used)/SUM(disk_size_total)*100, 2) AS “磁盘使用率(%)” FROM gv$unit GROUP BY tenant_name, zone, svr_ip
失败原因:
ErrorCode = 1146, SQLState = 42S02, Details = Table ‘oceanbase.gv$unit’ doesn’t exist
OceanBase 开源eqwl83_gaMTYxMTIzNjc4MC4xNzQxMzE1MjMw_ga_T35KTM57DZ*MTc0MTMzNjM4OC4zLjEuMTc0MTMzNjk4MS42MC4wLjA.
这个文档有磁盘的统计,但是没有CPU和内存的使用?