【 使用环境 】生产环境
【 OB or 其他组件 】mon_agent
【 使用版本 】4.3.1-snapshot
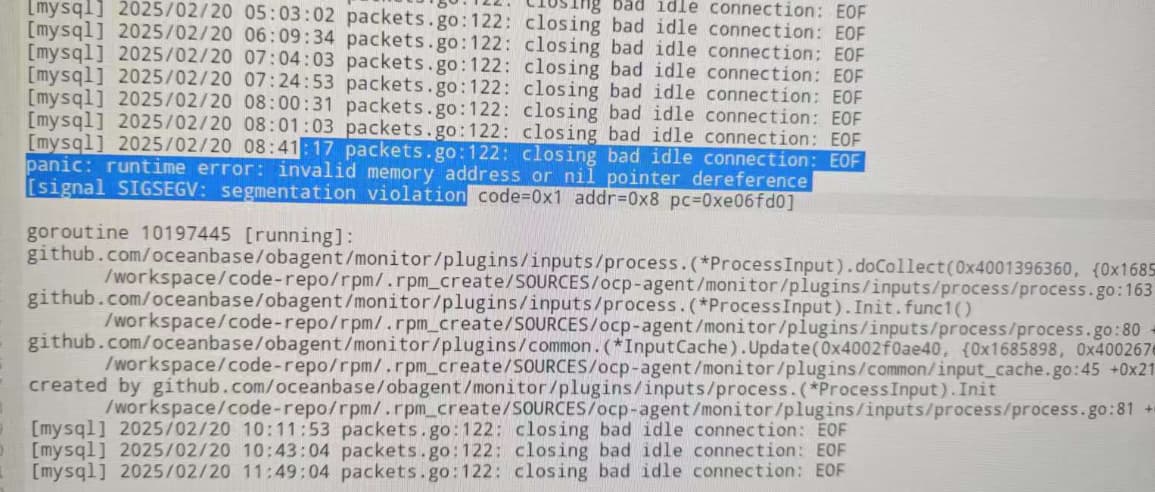
【问题描述】异常关闭
【复现路径】自动恢复
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
【 使用环境 】生产环境
【 OB or 其他组件 】mon_agent
【 使用版本 】4.3.1-snapshot
【问题描述】异常关闭
【复现路径】自动恢复
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
根据您提供的信息,monagent 出现了异常关闭的情况,并且日志中频繁出现 closing bad idle connection: EOF 的记录。这表明 monagent 在尝试与 MySQL 或 OceanBase 数据库建立连接时遇到了问题,可能是由于连接池中的空闲连接失效或数据库端主动断开了连接。
针对此问题,建议采取以下措施:
检查网络连接稳定性
确认生产环境中 monagent 和数据库之间的网络连接是否稳定,避免因网络波动导致的连接中断。
调整连接池配置
根据文档片段 4 中关于连接池设置的建议,可以适当调整连接池的相关参数以减少脏连接的发生。具体操作如下:
-- 示例:通过 obclient 修改 OBProxy 连接池参数
SET GLOBAL obproxy_idle_timeout = '1800'; -- 单位秒,即30分钟
排查数据库端配置
检查数据库端是否存在主动断开长时间未使用的连接的配置,如 MySQL 默认8小时后断开连接。如果确实存在此类配置,考虑适当延长该时间或者优化应用程序逻辑,避免长时间不活跃的连接。
更新至最新版本
您当前使用的版本为 4.3.1-snapshot,这是一个快照版本,可能存在一些已知但尚未修复的问题。建议关注官方发布的正式版本,及时升级到最新的稳定版本,以便获得更好的兼容性和性能表现。
使用 obdiag 收集更多信息
如果上述方法无法解决问题,可以使用 OceanBase 提供的敏捷诊断工具 obdiag 来收集更详细的日志信息,帮助进一步定位问题根源。参考提供的链接进行操作,并将收集到的日志提交给社区支持团队寻求专业帮助。
希望以上建议能对您有所帮助!如有其他疑问,请随时告知。
详情请参考:
详细的日志提供一份看看,有尝试重启agent么
不用重启,自动恢复
根据您提供的信息和需求,monagent 出现异常关闭的情况,并且您希望在不重启的情况下实现自动恢复。针对这一情况,可以考虑以下措施:
确保 monagent 的配置文件中启用了自动重试机制,以便在网络连接暂时中断或数据库端主动断开连接时能够自动重新建立连接。
检查配置文件:查看 monagent 的配置文件(通常是 YAML 或 JSON 格式),确认是否已经设置了合理的重试策略。
# 示例配置片段
retry:
max_attempts: 5
delay: "5s"
max_delay: "30s"
backoff: exponential
如果 monagent 支持健康检查和自我修复功能,确保这些功能已启用。这将允许 monagent 在检测到自身异常时尝试自动恢复,而无需手动干预。
启用健康检查:通过配置文件或命令行参数启用健康检查功能。
# 示例命令行参数
--health-check-interval=30s --self-healing=true
为了更好地监控 monagent 的运行状态,可以适当调整日志级别,使其输出更详细的调试信息。这有助于及时发现潜在问题并采取相应措施。
修改日志级别:编辑配置文件或将日志级别设置为 DEBUG 或 INFO。
# 示例配置片段
logging:
level: DEBUG
结合外部监控工具(如 Prometheus、Grafana 等)对 monagent 进行实时监控。当检测到异常时,可以通过告警系统触发自动恢复操作,例如重启服务或执行特定的修复脚本。
monagent 已正确集成到现有的监控体系中,并配置相应的告警规则。根据文档片段 4 中提到的内容,可以通过关闭定时刷新任务来减少不必要的连接活动,从而降低因连接池中的脏连接导致的问题。
-- 关闭定时刷新任务
CALL DBMS_EXTERNAL_TABLE.auto_refresh_external_table(-1);
编写一个定时任务或脚本来定期清理无效连接,确保连接池中的连接始终处于健康状态。
示例脚本:
#!/bin/bash
while true; do
# 执行清理命令
obclient -h <host> -P <port> -u <user> -p<password> -e "SHOW PROCESSLIST;" | grep 'idle' | awk '{print $1}' | xargs -I {} obclient -h <host> -P <port> -u <user> -p<password> -e "KILL {};"
sleep 300 # 每隔5分钟执行一次
done
如果以上方法仍无法解决问题,建议参考官方文档或联系 OceanBase 社区支持团队获取更多帮助。您可以使用 obdiag 工具收集详细的日志信息,并将其提交给支持团队进行进一步分析。
综上所述,在不重启 monagent 的前提下,通过配置自动重试机制、启用健康检查和自我修复功能、调整日志级别、优化连接管理以及定期清理无效连接等手段,可以在一定程度上实现自动恢复。希望这些建议能对您有所帮助!如有其他疑问,请随时告知。
检索到的文档如下:
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
这个回复挺专业
如果频繁重启,可能是被OOMkiller了,可以把agent的内存调大点
是否升级过agent,可能存在重试任务堵塞情况。
这边查看了下相关故障,是否你的集群有过应急操作手动推送了 monitor_transaction.yaml