【 使用环境 】测试环境
【 OB or 其他组件 】OBDUMPER
【 使用版本 】4.3.2.1
【问题描述】使用obdumper导出库里某个表的数据时如何只导出数据,不导出表的结构,只找到了–table这个参数
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
【 使用环境 】测试环境
【 OB or 其他组件 】OBDUMPER
【 使用版本 】4.3.2.1
【问题描述】使用obdumper导出库里某个表的数据时如何只导出数据,不导出表的结构,只找到了–table这个参数
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
你好,
可以使用 --ddl --all 导出所有的数据库对象ddl
–ddl --table 导出某个table的表定义
–table导出了这个表的所有东西啊,包括分区,结构啥的,我现在是新增了一个表,这个表的字段和分区跟之前的表不一致,但是我需要用之前那个表里的数据来进行测试。使用INSERT INTO进行插入太慢了,数据太多了
抱歉,看错了
导出表数据可以使用 --table --csv
更多功能可以参考如下
| 格式(命令行选项) | 相关命令行选项 | 适用场景 |
|---|---|---|
| –csv | ||
| 用于标识导出 CSV 格式的数据文件。 | * --skip-header |
用于标识忽略导出表中的字段作为 CSV 文件头。
-D histroy --csv --table sc_order 我是这么定义的,但是也会导出表的结构啊
导出的文件目录以及导出命令发一下,obdumper版本是?
目前我在尝试使用dbloader导入到目标表里,因为导出的表的列和目标表的列数量并不是一致的,我使用–auto-column-mapping参数,说是可以根据源文件的列名和目标表列名进行对应导入,但是并没有生效,我看报错的日志里还是提示Cause: The number of columns parsed does not match the number of columns in the table
不要加–ddl就只导出数据不导出结构了
目前是导入的时候加了–auto-column-mapping参数还是提示Cause: The number of columns parsed does not match the number of columns in the table
你好。发一下完整命令行参数,源文件内容示例和目标表结构?我们复现一下
大哥,注意下隐藏掉密码…
忘了忘了
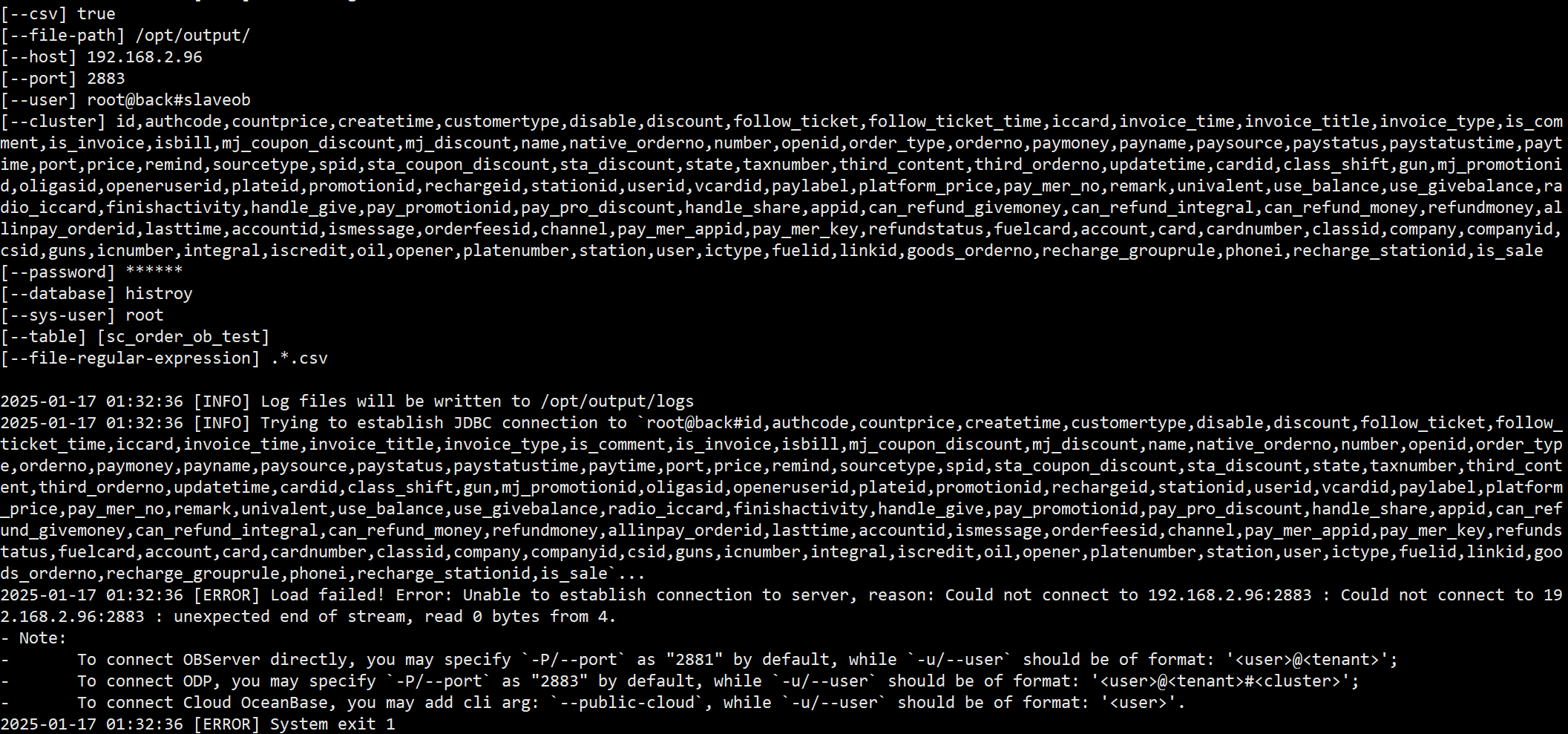
~/ob-loader-dumper-4.3.2.1-RELEASE/bin/obloader -h 192.168.2.96 -P 2883 -u root@back#slaveob -p -D histroy --csv --table sc_order_ob_test_copy1 --auto-column-mapping -f “/opt/output/” --file-regular-expression ‘.*.csv’
导入的命令是这样的
这个是导出的csv文件的列名
‘id’,‘time’,‘authcode’,‘countprice’,‘createtime’,‘customertype’,‘disable’,‘discount’,‘follow_ticket’,‘follow_ticket_time’,‘iccard’,‘invoice_time’,‘invoice_title’,‘invoice_type’,‘is_comment’,‘is_invoice’,‘isbill’,‘mj_coupon_discount’,‘mj_discount’,‘name’,‘native_orderno’,‘number’,‘openid’,‘order_type’,‘orderno’,‘paymoney’,‘payname’,‘paysource’,‘paystatus’,‘paystatustime’,‘paytime’,‘port’,‘price’,‘remind’,‘sourcetype’,‘spid’,‘sta_coupon_discount’,‘sta_discount’,‘state’,‘taxnumber’,‘third_content’,‘third_orderno’,‘updatetime’,‘cardid’,‘class_shift’,‘gun’,‘mj_promotionid’,‘oligasid’,‘openeruserid’,‘plateid’,‘promotionid’,‘rechargeid’,‘stationid’,‘userid’,‘vcardid’,‘paylabel’,‘platform_price’,‘pay_mer_no’,‘remark’,‘univalent’,‘use_balance’,‘use_givebalance’,‘radio_iccard’,‘finishactivity’,‘handle_give’,‘pay_promotionid’,‘pay_pro_discount’,‘handle_share’,‘appid’,‘can_refund_givemoney’,‘can_refund_integral’,‘can_refund_money’,‘refundmoney’,‘allinpay_orderid’,‘lasttime’,‘accountid’,‘ismessage’,‘orderfeesid’,‘channel’,‘pay_mer_appid’,‘pay_mer_key’,‘refundstatus’,‘fuelcard’,‘account’,‘card’,‘cardnumber’,‘classid’,‘company’,‘companyid’,‘csid’,‘guns’,‘icnumber’,‘integral’,‘iscredit’,‘oil’,‘opener’,‘platenumber’,‘station’,‘user’,‘ictype’,‘fuelid’,‘linkid’,‘goods_orderno’,‘recharge_grouprule’,‘phonei’,‘recharge_stationid’,‘is_sale’
这个是目标表字段
id,authcode,countprice,createtime,customertype,disable,discount,follow_ticket,follow_ticket_time,iccard,invoice_time,invoice_title,invoice_type,is_comment,is_invoice,isbill,mj_coupon_discount,mj_discount,name,native_orderno,number,openid,order_type,orderno,paymoney,payname,paysource,paystatus,paystatustime,paytime,port,price,remind,sourcetype,spid,sta_coupon_discount,sta_discount,state,taxnumber,third_content,third_orderno,updatetime,cardid,class_shift,gun,mj_promotionid,oligasid,openeruserid,plateid,promotionid,rechargeid,stationid,userid,vcardid,paylabel,platform_price,pay_mer_no,remark,univalent,use_balance,use_givebalance,radio_iccard,finishactivity,handle_give,pay_promotionid,pay_pro_discount,handle_share,appid,can_refund_givemoney,can_refund_integral,can_refund_money,refundmoney,allinpay_orderid,lasttime,accountid,ismessage,orderfeesid,channel,pay_mer_appid,pay_mer_key,refundstatus,fuelcard,account,card,cardnumber,classid,company,companyid,csid,guns,icnumber,integral,iscredit,oil,opener,platenumber,station,user,ictype,fuelid,linkid,goods_orderno,recharge_grouprule,phonei,recharge_stationid,is_sale,begintime,start_pressure,end_pressure
sc_order_ob_test_copy1 的表结构提供下,谢谢![]()
目前可以导大部分数据进去,但还是有部分数据会报这个The number of columns parsed does not match the number of columns in the table,为什么只有一小部分的数据有问题
根据文档库中的信息,对于您提到的问题,可以分点进行解答:
关于obdumper只导出数据不导出结构:
obdumper时,如果只想导出数据而不导出表结构,可以通过指定参数来实现。从您的命令中可以看到,您已经指定了--csv和--table参数,这确实会导出表的数据以及一些元数据(如表结构)。为了确保只导出数据,您可以尝试使用--data-only选项(如果版本支持),或者在后续处理CSV文件时忽略掉不需要的结构信息行。obdumper支持多种格式导出,但具体到只导出数据的操作,建议查看最新版本的手册确认是否有更直接的方式。关于obloader导入时列数不匹配的问题:
--auto-column-mapping参数仍然遇到“列数解析与表定义不符”的错误。这个问题可能是因为源文件中的某些记录存在额外字段或缺失字段导致的。尽管--auto-column-mapping应该能够根据列名自动映射,但如果源文件中有不符合预期的情况(例如空值、特殊字符等),可能会引起解析失败。obloader命令时明确指出哪些源文件列对应于目标表中的哪些列,这样可以避免因自动匹配失误而引发的问题。关于部分数据成功导入而另一部分失败的现象:
综上所述,针对您当前遇到的问题,建议采取以下措施:
obdumper是否支持--data-only等类似参数用于仅导出数据;希望以上建议能帮助您解决问题。如果还有其他疑问,欢迎继续交流。
详情请参考:
记得在obca coud课程里面说的,obdumper是oceanbase的一个导出工具有详细介绍。
如何手动指定哪些源文件列对应于目标表中的哪些列,在文档里没有找到呢
根据文档库中的信息,虽然直接的手动列映射参数在某些文档中可能没有明确提及,但可以通过以下几种方式实现手动指定源文件列与目标表列的对应关系。以下是详细的步骤和建议:
obloader 的 -c 或 --columns 参数obloader 支持通过 -c 或 --columns 参数来手动指定列映射。您可以列出源文件中的列名,并将其与目标表中的列名一一对应。
~/ob-loader-dumper-4.3.2.1-RELEASE/bin/obloader \
-h 192.168.2.96 \
-P 2883 \
-u root@back#slaveob \
-p \
-D history \
--csv \
--table sc_order_ob_test_copy1 \
-c "id,authcode,countprice,createtime,customertype,disable,discount,follow_ticket,follow_ticket_time,iccard,invoice_time,invoice_title,invoice_type,is_comment,is_invoice,isbill,mj_coupon_discount,mj_discount,name,native_orderno,number,openid,order_type,orderno,paymoney,payname,paysource,paystatus,paystatustime,paytime,port,price,remind,sourcetype,spid,sta_coupon_discount,sta_discount,state,taxnumber,third_content,third_orderno,updatetime,cardid,class_shift,gun,mj_promotionid,oligasid,openeruserid,plateid,promotionid,rechargeid,stationid,userid,vcardid,paylabel,platform_price,pay_mer_no,remark,univalent,use_balance,use_givebalance,radio_iccard,finishactivity,handle_give,pay_promotionid,pay_pro_discount,handle_share,appid,can_refund_givemoney,can_refund_integral,can_refund_money,refundmoney,allinpay_orderid,lasttime,accountid,ismessage,orderfeesid,channel,pay_mer_appid,pay_mer_key,refundstatus,fuelcard,account,card,cardnumber,classid,company,companyid,csid,guns,icnumber,integral,iscredit,oil,opener,platenumber,station,user,ictype,fuelid,linkid,goods_orderno,recharge_grouprule,phonei,recharge_stationid,is_sale" \
-f "/opt/output/" \
--file-regular-expression '.*.csv'
在这个命令中,-c 参数后面跟的是一个逗号分隔的列名列表,这些列名必须与目标表中的列名严格匹配。确保源文件中的列顺序与目标表中的列顺序一致,或者按照实际需要进行调整。
如果您的 CSV 文件包含列头信息(即第一行是列名),obloader 可以自动识别并映射这些列名到目标表中的相应列。确保源文件的第一行是列名,并且这些列名与目标表中的列名完全一致。
id,authcode,countprice,createtime,customertype,disable,discount,...
如果源文件和目标表之间的列名或顺序不一致,可以在导入前使用脚本(如 Python、Perl 等)对 CSV 文件进行预处理,重新排列列顺序或重命名列,使其与目标表完全匹配。
import csv
source_file = '/path/to/source.csv'
target_file = '/path/to/target.csv'
with open(source_file, 'r') as infile, open(target_file, 'w', newline='') as outfile:
reader = csv.DictReader(infile)
fieldnames = ['id', 'authcode', 'countprice', 'createtime', ...] # 按照目标表的列顺序
writer = csv.DictWriter(outfile, fieldnames=fieldnames)
writer.writeheader()
for row in reader:
writer.writerow({k: row.get(k, '') for k in fieldnames})
INSERT INTO ... SELECT 语句如果您有权限直接操作数据库,可以考虑将数据从导出的 CSV 文件加载到一个临时表中,然后使用 INSERT INTO ... SELECT 语句将数据插入到目标表中,并在此过程中进行列映射。
INSERT INTO target_table (id, authcode, countprice, createtime, ...)
SELECT id, authcode, countprice, createtime, ...
FROM temp_table;
为了手动指定源文件列与目标表列的对应关系,您可以:
obloader 的 -c 或 --columns 参数。希望这些建议能帮助您解决问题。如果还有其他疑问或需要进一步的帮助,请随时联系 OceanBase 的人工答疑团队获取更多支持。
更多信息请查看:
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
听起来是部分行的数据有缺失吧?能看下异常行的数据有什么区别吗