淸鹤
2025 年1 月 6 日 23:32
#1
【 使用环境 】生产环境
【SOP系列 22 】——故障诊断第一步(自助诊断和诊断信息收集)
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手 ] 即可召唤小助手,欢迎试用!
1 个赞
论坛小助手
2025 年1 月 6 日 23:33
#4
根据文档库中的信息,针对您提到的 OMS 迁移 Store 组件拉取时间异常(1970-01-01 08:00:00)以及 STORE_START_FAILED 无法进行全量迁移的问题,可以尝试以下解决方案:
首先,请检查当前 Store 组件的状态。如果 Store 组件处于已停止、异常或非预期退出状态,您可以尝试重启它。
步骤:
登录 OMS 社区版控制台。
在左侧导航栏,单击 运维监控 > 组件 ,默认进入 Store 页面。
找到目标 Store 组件,确保其状态为 异常 或 已停止 。
单击目标 Store 后的 启动 按钮,然后在弹出的对话框中单击 确定 。
如果重启 Store 组件无效,或者无法恢复原有的 Store 组件,建议新建一个 Store 组件,并设置合适的时间起点。
步骤:
登录 OMS 社区版控制台。
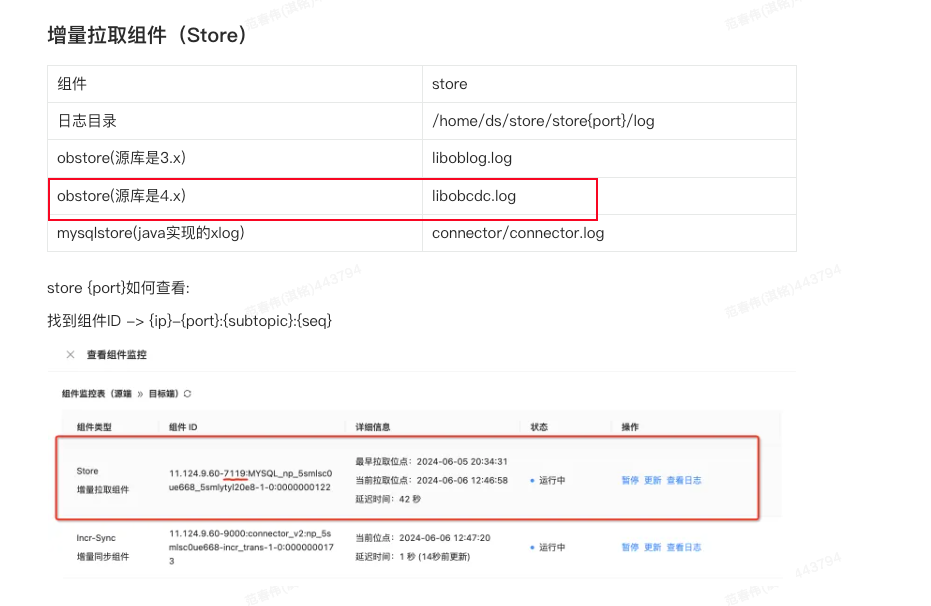
在左侧导航栏,单击 数据迁移 ,找到目标任务并进入详情页面。
单击页面右上角的 查看组件监控 ,找到对应的 Store 组件,复制其 Topic。
在左侧导航栏,单击 运维监控 > 组件 ,默认进入 Store 页面。
单击页面右上角的 新增 按钮。
在 新增 对话框中,配置各项参数:
Subtopic : 输入复制的 Topic。
Node : 选择启动 Store 的机器。
Timestamp : 选择回拉的时间起点。该起点需要覆盖到下游请求的位点。例如,如果 Writer 位点时间在 “2022-08-01 10:05:00”,您需要将 Store 位点提前 5~10 分钟(例如 “2022-08-01 10:00:00”),再进行新建 Store 操作。
单击 新增 按钮完成创建。
如果 Store 组件已经正常运行但仍然存在延迟问题,可以尝试修改增量数据保留时间参数 store.clearer.outdated,以确保数据保留时间能覆盖到下游请求的位点。
步骤:
登录 OMS 社区版控制台。
在左侧导航栏,单击 数据迁移 ,找到目标任务并进入详情页面。
单击页面右上角的 查看组件监控 ,找到对应的 Store 组件,单击 更新 。
在 更新配置 对话框中,鼠标悬停至增量数据保留时间参数 store.clearer.outdated,单击编辑图标进行修改。
输入新的参数值后,单击确认图标保存修改。
单击 更新 按钮完成配置更新。
如果上述操作仍无法解决问题,建议进一步检查 Store 组件的日志,排查是否有其他错误或异常信息。具体步骤如下:
进入迁移任务的详情页面,单击右上角的 查看组件监控 。
查看 Store 组件的日志,观察是否有明显的报错信息。
如果无法识别具体的错误信息,请反馈异常现象和组件日志至 OMS 社区版的技术服务人员,由技术服务人员为您处理问题。
希望以上步骤能够帮助您解决 OMS 迁移 Store 组件拉取时间异常的问题。如果问题依然存在,建议联系 OceanBase 的人工答疑以获取更多帮助。
检索到的文档如下:
OMS 社区版错误码 Store 没有下游请求位点的数据 启动和暂停 Store 组件 更新 Full-Import 组件 如何处理 Failed to fetch 报错 oms_migration_delay 迁移任务延迟 oms_sync_delay 同步任务延迟 如何清理 Store 文件 数据库库表重命名
1 个赞
淸鹤
2025 年1 月 7 日 13:53
#6
新建,重启都试过了,最后的拉取点位都是1970年,
1 个赞
淇铭
2025 年1 月 7 日 13:56
#7
把整个日志压缩发过来 对应楼上的截图 看看源库是3.x还是4.x的 日志别发错了
1 个赞
论坛小助手
2025 年1 月 7 日 14:05
#8
根据您提供的信息和日志片段,Store 组件拉取时间异常(1970-01-01 08:00:00)的问题可能与时间戳初始化或位点同步有关。以下是一些更深入的排查步骤和解决方案:
确保所有涉及的服务器(包括 OMS、OB 集群等)的时间和时区设置正确且一致。
步骤:
登录到相关服务器,检查系统时间:date
确认时区设置:timedatectl status
如果发现时间或时区不一致,请进行调整并同步时间。
确保 OB 集群中的时间配置正确,特别是 gmt_offset 参数。
步骤:
确认 OMS 中 Store 组件的位点同步配置是否正确,特别是增量数据保留时间和初始位点设置。
步骤:
登录 OMS 社区版控制台。
在左侧导航栏,单击 数据迁移 ,找到目标任务并进入详情页面。
单击页面右上角的 查看组件监控 ,找到对应的 Store 组件,单击 更新 。
检查并调整以下参数:
Timestamp : 确保该参数设置为一个合理的初始位点时间,覆盖到下游请求的位点。
store.clearer.outdated : 增量数据保留时间,确保能覆盖到下游请求的位点。
从日志中提取更多有用的信息,特别是与时间戳相关的报错信息。
步骤:
查看 Store 组件的日志文件,重点关注与时间戳和位点同步相关的日志条目。
根据日志中的提示,进一步排查问题。例如,日志中提到的 schema_version 和 received_version 是否存在不一致的情况。
如果上述步骤仍无法解决问题,可以尝试清理和重置 Store 组件的状态。
步骤:
登录 OMS 社区版控制台。
在左侧导航栏,单击 运维监控 > 组件 ,默认进入 Store 页面。
找到目标 Store 组件,单击 停止 。
确认停止后,删除该 Store 组件。
新建一个 Store 组件,并设置合适的时间起点(如前述步骤所述)。
如果问题依然存在,建议联系 OceanBase 的人工答疑以获取更多帮助。您可以提供详细的日志和配置信息,以便技术支持团队更好地帮助您解决问题。
根据您提供的日志片段,可以看到一些关于 schema_version 和 received_version 的信息。这些信息表明 Store 组件在处理 schema 版本时可能存在不一致或延迟。具体日志条目如下:
2025-01-07 13:51:56.903252] INFO ... [SCHEMA_STORE] schema st.
sion=1734977713235592)
2025-01-07 13:51:56.905562] INFO ... [SCHEMA_STORE] schema st.
sion=1716795978789040)
这些日志显示了不同的 schema 版本号,但并未直接指出时间戳问题。因此,重点应放在时间配置和位点同步上。
希望以上步骤能够帮助您解决 OMS 迁移 Store 组件拉取时间异常的问题。如果问题依然存在,请继续收集详细日志并与 OceanBase 技术支持团队联系。
具体信息可参考以下文档:
SQL 诊断
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
1 个赞
淸鹤
2025 年1 月 7 日 15:03
#11
OceanBase MySQL-CE Mode 3.1.4
淇铭
2025 年1 月 7 日 15:40
#12
ob机器的负载是不是很高呀 你把observer.log的日志也压缩发一下
淇铭
2025 年1 月 8 日 09:34
#14
你们迁移是 ob3.x->ob4.x么?还是mysql->ob 或者其他?如果源端是observer.log发一下 看看机器是不是负载很高
刘彻
2025 年1 月 8 日 10:03
#16
992 [2025-01-07 14:43:36.591292] ERROR [TLOG.SCHEMA] init (ob_log_schema_getter.cpp:477) [3813523][0][Y0-0000000000000000] [lt=3] auto_switch_mode_and_refresh_schema fail, retry later(ret=-4013, ret=“OB_ALLOCATE_MEMORY_FAILED”, old_err=-4013, old_err=“OB_ALLOCATE_MEMORY_FAILED”, timeout=7200000000, retry_time=4720435431) BACKTRACE:0x7f3e55d15cce 0x7f3e55ae036b 0x7f3e4dc06b7e 0x7f3e4df95912 0x7f3e4df8df2a 0x7f3e4dd59f7a 0x7f3e4dd579bc 0x7f3e4dd52a48 0x7f3e4dd5372d 0x7f3e4dd5359e 0x7f3e9c695dd3 0x7f3eaa1408b2 0x7f3ea9abaea5 0x7f3ea90d4b0d
ob sys租户内存不足,导致cdc 刷新schema失败
淸鹤
2025 年1 月 8 日 10:06
#17
您表达的意思是我源端集群的sys内存不足导致的是么
淇铭
2025 年1 月 8 日 10:29
#19
是的 查询一下 下面的信息 SELECT /* MONITOR_AGENT */
淸鹤
2025 年1 月 8 日 11:06
#20
| TENANT_ID | | svr_port | used_mb |
±----------±-±---------±--------+
| 1 | | 2882 | 2562 |
| 1 | | 2882 | 2559 |
| 1 | | 2882 | 1404 |
| 1 | | 2882 | 1337 |
| 1 | | 2882 | 1414 |
| 1 | | 2882 | 2458 |
查询内存占用:11.46 GB
淇铭
2025 年1 月 8 日 11:10
#21
SELECT