【 使用环境 】测试环境
【 OB or 其他组件 】OCP
【 使用版本 】4.3.2-20241012145836
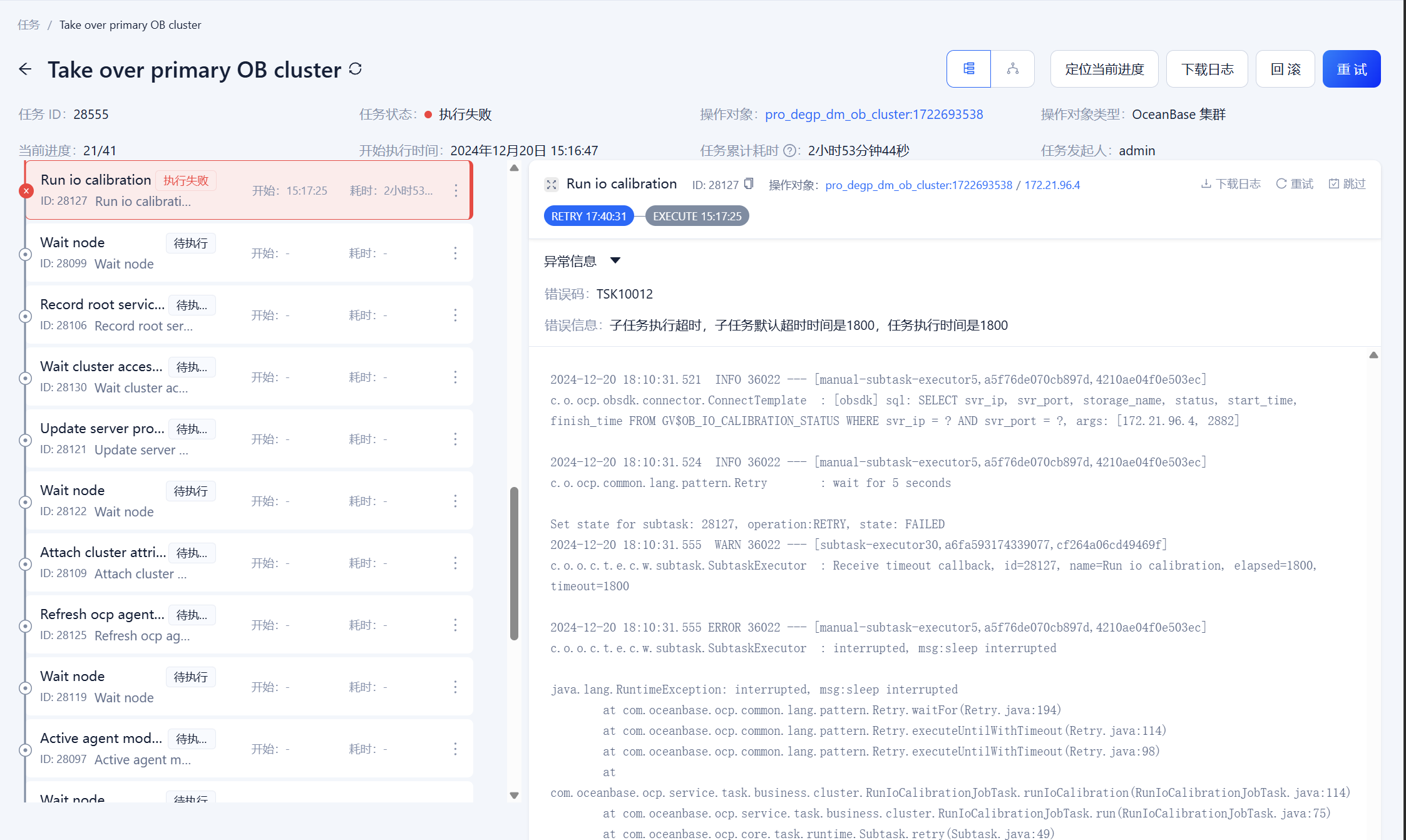
【问题描述】OCP接管Oceanbase,在Run io calibration环节卡住
相关日志如下:
subtask_28127 (1).log (79.0 KB)
但是我看日志似乎没报错。
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【SOP系列 22 】——故障诊断第一步(自助诊断和诊断信息收集)
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
1 个赞
论坛小助手
#3
根据您提供的信息,OCP 在接管 OceanBase 集群的过程中,在“Run io calibration”环节卡住,并最终超时失败。错误码为 TSK10012,错误信息指出子任务执行超时,默认超时时间为 1800 秒(30 分钟)。从日志中可以看到,任务在等待 IO 校准结果时被中断。
可能的原因和解决方法:
-
超时时间设置过短:
-
原因:默认的超时时间可能不足以完成 IO 校准任务,特别是在测试环境中,硬件性能或网络状况不佳的情况下。
-
解决方法:可以尝试增加超时时间。具体操作步骤如下:
- 登录 OCP 管控平台。
- 进入任务管理页面,找到对应的接管任务。
- 修改任务配置中的超时时间参数(如
timeout),将其设置为更大的值,例如 3600 秒(1 小时)或更长。
- 重新启动接管任务。
-
IO 校准任务本身的问题:
-
原因:IO 校准任务可能由于某些原因无法正常完成,例如磁盘性能问题、网络延迟等。
-
解决方法:
- 检查目标 OceanBase 集群的磁盘性能,确保磁盘读写速度正常。
- 检查网络连接,确保 OCP 和 OceanBase 集群之间的网络通信稳定。
- 查看 OCP 和 OceanBase 集群的日志,寻找是否有其他异常信息或错误提示。
-
资源不足:
-
原因:如果目标 OceanBase 集群的资源(如 CPU、内存、磁盘 IOPS)不足,可能会导致 IO 校准任务无法在规定时间内完成。
-
解决方法:
- 检查目标 OceanBase 集群的资源使用情况,确保有足够的资源可用。
- 如果资源不足,考虑增加集群的资源配置,或者选择在资源负载较低的时间段进行接管操作。
-
OCP 版本问题:
-
原因:您使用的 OCP 版本为 4.3.2-20241012145836,可能存在已知的 bug 或兼容性问题。
-
解决方法:
- 检查 OCP 官方文档或社区论坛,确认是否有类似问题的报告及解决方案。
- 如果有可用的补丁或新版本,建议升级 OCP 到最新版本。
建议的操作步骤:
-
增加超时时间:首先尝试增加超时时间,观察是否能够解决问题。
-
检查系统资源和网络:确保目标 OceanBase 集群的资源充足且网络稳定。
-
查看详细日志:仔细检查 OCP 和 OceanBase 集群的日志,寻找更多线索。
-
联系技术支持:如果问题仍然存在,建议联系 OceanBase 的官方技术支持团队,获取进一步的帮助。
希望以上建议能帮助您解决问题。如果有更多问题或需要进一步的帮助,请随时告知。
更多信息请查看:
- 4000 ~ 4499
- 10000 ~ 12000
- 4500 ~ 4999
- 5000 ~ 5999
- 7000 ~ 7999
- 9000 ~ 9499
2 个赞
旭辉
#5
可以手动检验磁盘io,如果检验不出或者有问题,一般是磁盘io性能不满足。
如果手动建议正常的,重试任务即可。
https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000001431739
参考
Run io calibration - #9,来自 胖乎乎1hm9y07_gaMTIwMjU5NTAzNC4xNzE0OTc1MTY1_ga_T35KTM57DZ*MTczNDkxNzc2My40MjUuMS4xNzM0OTE5MTE4LjM5LjAuMA…
2 个赞
老师,是不是我操作不对。这个服务器的磁盘性能应该不错。
1 个赞
旭辉
#7
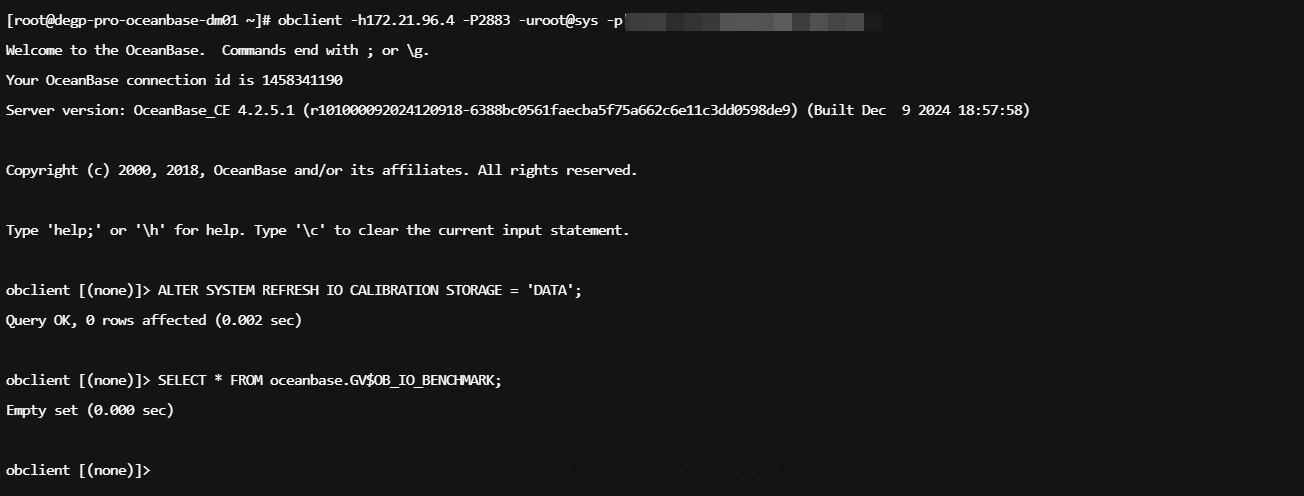
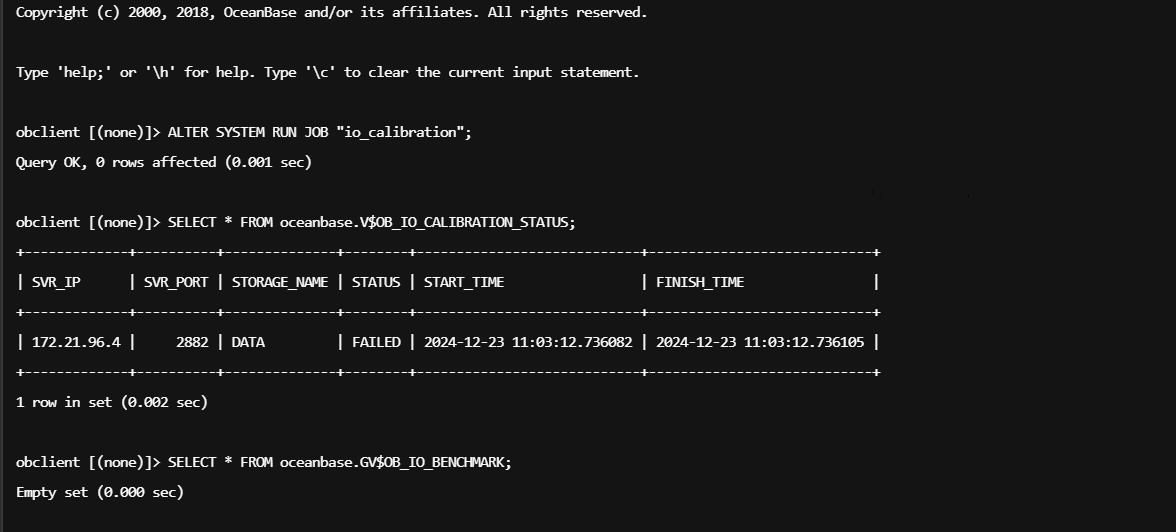
执行下如下sql看下
ALTER SYSTEM RUN JOB "io_calibration";
SELECT * FROM oceanbase.V$OB_IO_CALIBRATION_STATUS;
SELECT * FROM oceanbase.GV$OB_IO_BENCHMARK;
1 个赞
论坛小助手
#8
根据您提供的信息和上传的图片,您已经尝试手动刷新了 IO 校准,并且服务器的磁盘性能应该不错。然而,OCP 在接管 OceanBase 集群时仍然在“Run io calibration”环节卡住并最终超时失败。
分析与建议
-
手动刷新 IO 校准:
- 您已经执行了
ALTER SYSTEM REFRESH IO_CALIBRATION STORAGE = 'DATA'; 命令来手动刷新 IO 校准。这一步骤是正确的,但需要注意的是,手动刷新可能不会立即生效或解决 OCP 接管过程中遇到的问题。
-
检查 IO 校准状态:
-
确认 OCP 和 OB 之间的网络延迟:
- 尽管磁盘性能良好,网络延迟也可能影响 IO 校准任务的完成时间。请确保 OCP 和 OceanBase 集群之间的网络连接稳定且延迟较低。
- 可以通过
ping 或 traceroute 等工具测试网络延迟。
-
检查 OCP 日志中的详细错误信息:
- 您提到日志中没有明显的错误信息,但可以更仔细地检查 OCP 的日志文件,特别是与 IO 校准相关的部分。重点关注是否有任何警告或异常信息。
- 日志路径通常位于 OCP 安装目录下的
logs 文件夹中,例如 /opt/ocp/logs/。
-
增加超时时间:
- 尽管磁盘性能良好,IO 校准任务仍可能需要较长时间完成,特别是在测试环境中。建议您再次尝试增加 OCP 任务的超时时间,确保有足够的时间完成校准。
- 登录 OCP 管控平台,进入任务管理页面,找到对应的接管任务,修改任务配置中的超时时间参数(如
timeout),将其设置为更大的值,例如 7200 秒(2 小时)或更长。
-
检查 OCP 和 OB 版本兼容性:
- 您使用的 OCP 版本为 4.3.2-20241012145836,OceanBase 版本为 4.2.5.1。请确保这两个版本之间是兼容的。如果有可用的补丁或新版本,建议升级到最新版本以获得更好的兼容性和稳定性。
-
联系技术支持:
- 如果问题仍然存在,建议联系 OceanBase 的官方技术支持团队,获取进一步的帮助。他们可以提供更详细的诊断和解决方案。
综合建议
-
重新检查 IO 校准状态:确保 IO 校准数据是最新的。
-
优化网络环境:确保 OCP 和 OceanBase 集群之间的网络连接稳定且延迟较低。
-
增加超时时间:适当增加 OCP 任务的超时时间,确保有足够的时间完成校准。
-
版本兼容性:确认 OCP 和 OceanBase 版本之间的兼容性,必要时进行升级。
希望以上建议能帮助您解决问题。如果有更多问题或需要进一步的帮助,请随时告知。
更多信息请参考 OceanBase 官方文档 中的相关章节。
检索到的文档如下:
- 负载均衡
- V$OB_SYS_TIME_MODEL
- GV$OB_SYS_TIME_MODEL
- DBA_MVREF_STATS_SYS_DEFAULTS
- oceanbase.CDB_OB_TEMP_FILES
- CDB_MVREF_STATS_SYS_DEFAULTS
- 使用 ChunJun 从 MySQL 数据库迁移数据到 OceanBase 数据库
- oceanbase.DBA_OB_TEMP_FILES
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
1 个赞
另外,请问,老师,如何删除一个接管失败的集群。
我们有个任务一直卡在接管中,任务回滚,但是回滚失败了。我们想清理了重新接管。
2 个赞
旭辉
#13
登陆ocp_meta租户,查下库meta_database的ob_cluster表是否有这个集群?
obclient -hxx.xx.xx.xx -P2881 -uroot@ocp_meta -p’xxx’ -Dmeta_database -A
select * from ob_cluster\G;
2 个赞
旭辉
#14
可以多尝试几次,如果一直failed,大概率就是磁盘性能问题
2 个赞
老师,好像是一直FAILED的话,只能更换节点吗?
服务器是腾讯云
2 个赞
小蚂蚁
#21
TSK10012 子任务执行超时,在哪里可以设置这个超时时间?