

背景
很多社区版的用户,在遇到非预期报错后,会到 OceanBase 论坛中进行提问,这是一个很好的解决问题的方法。不仅会有很多热心用户帮您来解决问题,还会有专业的值班同学来为大家服务。
但也有部分刚来社区的新用户,提问时只提供一个错误码,这往往是不够的。一般还需要附带上 OBServer 版本信息、执行的操作序列,以及相关日志信息,以便值班的技术支持同学在本地复现和协助排查根因。
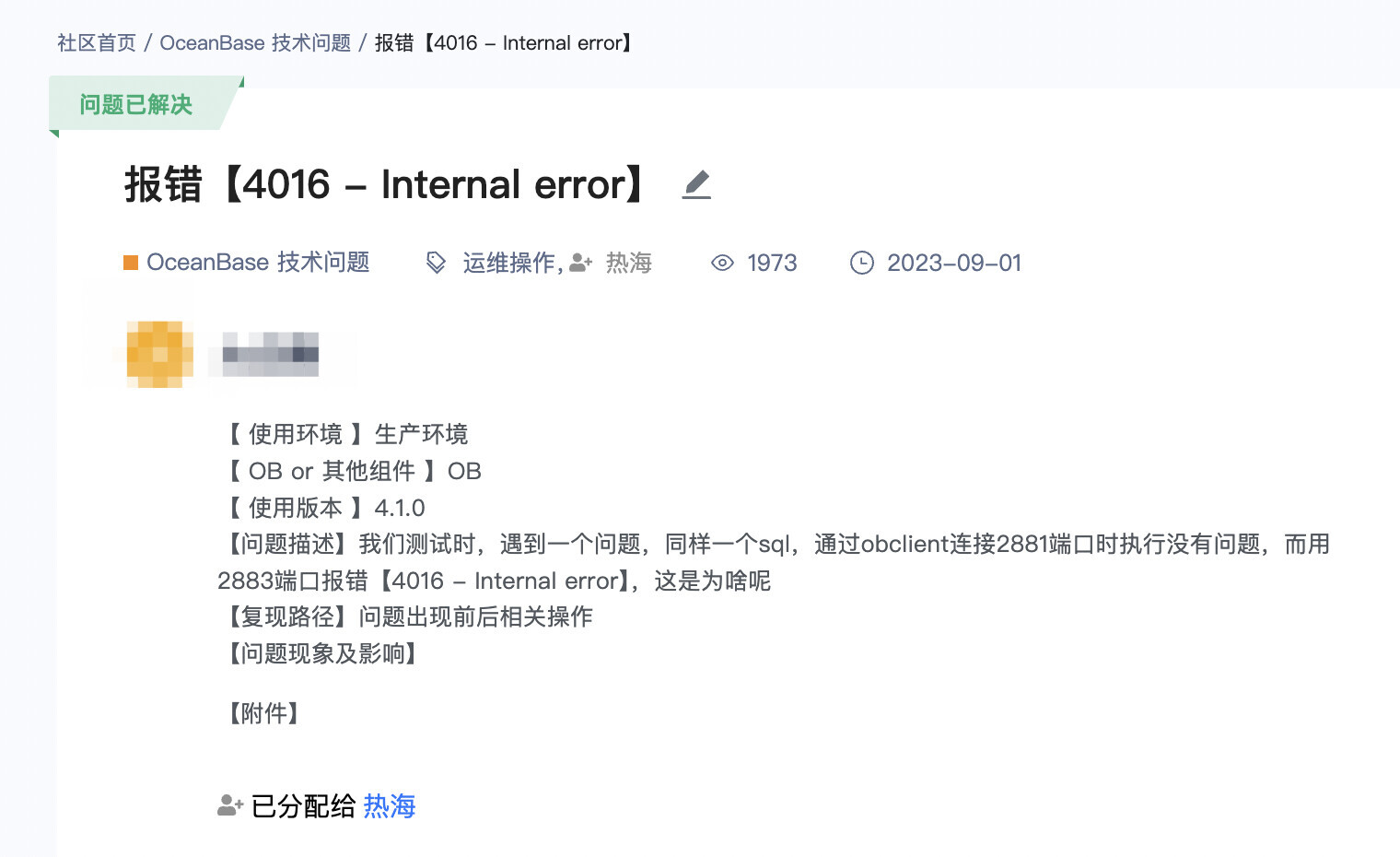
类似于下面这个帖子,如果只提供一个错误码和对应的报错信息 Internal error,大概率是看不出问题原因的,还需要用户协助提供这个错误码对应的日志信息。
本次课程,会简单为大家介绍下,在遇到非预期的报错时,需要为论坛值班同学提供哪些信息,以及如何捞取 OBServer 的日志。
边学边练,效果拔群
-
在线实验地址:https://www.oceanbase.com/demo/get-observer-log
- 正所谓 “纸上得来终觉浅,实践才能出真知”,强烈推荐大家点击上面的链接,根据在线体验页面左边的实验文档,亲手实践一把!
-
课后小测地址:https://exam.oceanbase.com/pre?did=2cBMqk2TakXMxVUy3CLc0
- 大家完成课后小测,并在小测中上传实验截图,就可以从社区论坛中获取积分,并有机会获得抽奖的礼物。
- 坚持完成全部十期实验并通过结课考试的同学,还可以获得更多的积分奖励,并有机会获得 OBCA / OBCP 考试券。活动详情见:OceanBase DBA 实战营(第二季)—— 体验再升级,福利不停息!
-
大家积极参与在线体验的实验,也是我能够持续为大家更新《DBA 实战营(第二季)》课程内容的动力!
- 大家如果都不来在线体验进行实验并完成课后小测的话,老大马上就要让我停更 OceanBase 社区的这些教程了……
需要给社区值班同学提供的信息
提供信息的目的是为了让技术支持同学能够在他的本地环境中复现用户遇到的问题,一般情况下,需要提供:
- 组件版本和部署方式,例如:OceanBase_CE-v4.3.5.1 单机部署。
- 报错涉及的表结构。
- 导致报错的 SQL 执行序列。(前三个是为了让值班同学能在相同的环境中,复现你遇到的问题)
- 报错对应的日志信息。
其中,组件版本在连接数据库时能看到,一般类似于:
Welcome to the OceanBase monitor. Commands end with ; or \g.
Server version: 5.7.25 OceanBase_CE 4.3.5.1
(r101000042025031818-b6d5706eb3d2c5f501c7fa646ddbf32f3dc87069)
或者通过执行如下 SQL 获取:
obclient> select version();
+------------------------------+
| version() |
+------------------------------+
| 5.7.25-OceanBase_CE-v4.3.5.1 |
+------------------------------+
1 row in set (0.00 sec)
捞取报错对应的 OBServer 日志信息
比如说我在一个特殊的 OBServer 版本中,想创建一个名字叫 zlatan_db 的 database,结果遇到了报错:
obclient> create database zlatan_db;
ERROR 4016 (HY000): Internal error
然后就可以捞日志出来,先自己看一眼。如果没啥线索,再找去社区论坛发帖找值班同学帮忙分析。
捞日志方法一:select last_trace_id()
第一种方法是:在同一个 session 中,紧接着报错的 SQL(中间不要插入其他 SQL) ,去执行 select last_trace_id() 。
obclient> create database zlatan_db;
ERROR 4016 (HY000): Internal error
obclient> select last_trace_id();
+------------------------------------+
| last_trace_id() |
+------------------------------------+
| Y584A0B9E1F14-0006299CA6E2263B-0-0 |
+------------------------------------+
1 row in set (0.00 sec)
然后拿着这个 trace_id 去类似于 /home/user_name/oceanbase/log 的日志目录中 grep 一下。
如果目录里的日志文件不多,可以直接 grep trace_id *。
grep Y584A0B9E1F14-0006299CA6E2263B-0-0 * > zlatan.log
否则可以考虑根据报错发生的时间范围,grep 在这个时间范围内生产的指定几个 log 文件。
grep Y584A0B9E1F14-0006299CA6E2263B-0-0 observer.log.2024121918* rootservice.log.2024121918* > zlatan.log
最后把 zlatan.log 当做附件上传到论坛的问题帖中。
如果大家愿意再自己多走一步的话,可以在这个 zlatan.log 文件里把 ret=-4016 (因为报错的错误码是 4016)这个关键字高亮一下。按日志时间顺序看,最早出现 ret=-4016 的地方,就是问题发生的直接原因。

rootservice.log.20241219182047574:[2024-12-19 18:12:51.807165] WDIAG [RS]
create_database (ob_root_service.cpp:3039) [44788][DDLQueueTh0][T0]
[Y584A0B9E1F14-0006299CA6E2263B-0-0] [lt=18][errcode=-4016]
create database failed, because db_name is forbidden by zlatan. just for test.(ret=-4016)
rootservice.log.20241219182047574:[2024-12-19 18:12:51.807177] WDIAG [RS] process_
(ob_rs_rpc_processor.h:206) [44788][DDLQueueTh0][T0]
[Y584A0B9E1F14-0006299CA6E2263B-0-0] [lt=10][errcode=-4016] process failed(ret=-4016)
rootservice.log.20241219182047574:[2024-12-19 18:12:51.807187] INFO [RS]
process_ (ob_rs_rpc_processor.h:226) [44788][DDLQueueTh0][T0]
[Y584A0B9E1F14-0006299CA6E2263B-0-0] [lt=8] [DDL]
execute ddl like stmt(
ret=-4016, cost=117618, ddl_arg=ddl_stmt_str:"create database zlatan_db",
exec_tenant_id:1002, ddl_id_str:"", sync_from_primary:false,
based_schema_object_infos:[], parallelism:0, task_id:0, consumer_group_id:0)
在日志中的第一行,大家可以看到,这个 4016 报错的直接原因就是:create database failed, because db_name is forbidden by zlatan. just for test.
从第一行日志中,基本就就能看出,报错原因是创建 zlatan_db 这个特殊的 database_name 的行为,被数据库系统给禁止了。大概是因为兹拉坦这个名字太敏感之类的吧,哈哈~
(其实是因为在我自己编译安装的这个特殊 OBServer 版本中,悄悄修改了一些代码,不允许用户创建名字叫 zlatan_db 的 database。这个特殊版本只用来作为课程示例,大家在官方渠道下载的安装包,肯定不会遇到,不用担心~)
int ObRootService::create_database(
const ObCreateDatabaseArg &arg,
UInt64 &db_id)
{
int ret = OB_SUCCESS;
// other codes, we ignore
// ...
// add by zlatan, just for debug
ObString forbidden_db_name = "zlatan_db";
if (arg.database_schema_.get_database_name_str() == forbidden_db_name) {
ret = OB_ERR_UNEXPECTED;
LOG_WARN("create database failed, because db_name is forbidden by zlatan. just for test.", K(ret));
}
return ret;
}
捞日志方法二:grep “ret=-errno”
第一种方法在使用上有一些限制,需要在在同一个 session 中,紧接着报错的 SQL,去执行 select last_trace_id() 。
如果在报错 SQL 之后,已经执行了其他 SQL,或者已经退出对应 session,可以在日志里先通过 grep "ret=-errno" ,获取 trace_id。
$grep "ret=-4016" *
observer.log.20241219181453955:[2024-12-19 18:12:51.807313]
WDIAG [RPC] send (ob_poc_rpc_proxy.h:176) [46486][T1002_L0_G0][T1002]
[Y584A0B9E1F14-0006299CA6E2263B-0-0] [lt=10][errcode=-4016]
execute rpc fail(addr="11.158.31.20:22602", pcode=520, ret=-4016, timeout=999999400)
...
现在有了 trace_id,就回到了方法一,通过 trace_id Y584A0B9E1F14-0006299CA6E2263B-0-0 去 grep 出完整日志即可。
grep Y584A0B9E1F14-0006299CA6E2263B-0-0 * > zlatan.log
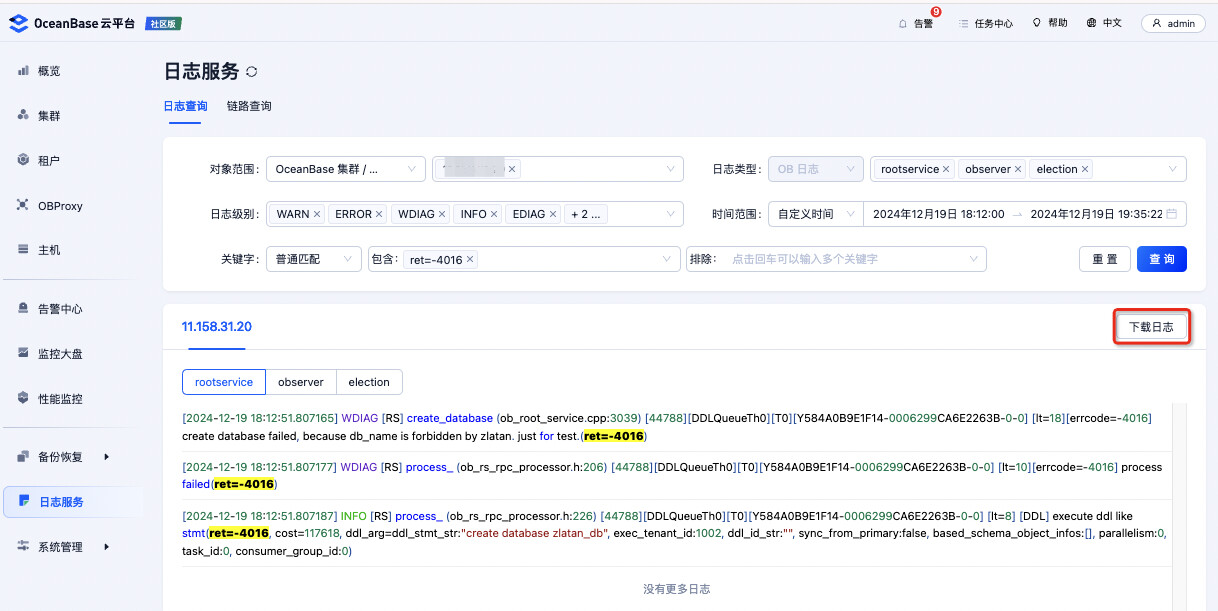
捞日志方法三:OCP 白屏捞日志
如果不喜欢在黑屏命令行中 grep 日志,可以用 OCP 提供的白屏日志服务。
关键字依然是 ret=-errno ,而且更便捷地选择日志的时间范围,这里需要捞取的日志级别可以无脑全选。
发现如果是个分布式的集群,但是不想去每台节点都 grep 一把日志,还是用 OCP 的白屏日志收集比较好。
捞日志方法四:obdiag 捞日志
靖顺、渠磊两位老哥开发的 obdiag,也支持一键自动取多个节点捞日志,即使是分布式集群外加 OBProxy,也能通过一条命令在黑屏环境下快速捞到日志。
详见:OceanBase 敏捷诊断工具(obdiag)—— observer 日志收集。
What’s more?
与 obdiag 相关的在线体验也会在 OceanBase 官网陆续上线,欢迎大家持续关注!
捞到日志之后
拿着你捞到的日志,去社区论坛发帖提问吧。
What’s more ?
发现 show trace 命令还可以看到执行失败的 SQL 是在什么时候失败的,可能也能在分析问题的时候帮到大家。
比如下面这个例子,可以看到表不存在这个报错,让 SQL 在 resolver(解析)阶段就停下来了。说明是在 resolver 的检查时就发现了表不存在,然后就没有执行后面的东西了。
obclient> set ob_enable_show_trace = 1;
Query OK, 0 rows affected (0.00 sec)
obclient> insert into z0case(z0_test0,z0_test1) values('11:11:12', '11:11:10');
ERROR 1146 (42S02): Table 'test.z0case' doesn't exist
obclient> show trace;
+-------------------------------+----------------------------+------------+
| Operation | StartTime | ElapseTime |
+-------------------------------+----------------------------+------------+
| com_query_process | 2025-05-09 10:19:39.621982 | 0.551 ms |
| └── mpquery_single_stmt | 2025-05-09 10:19:39.621988 | 0.534 ms |
| └── sql_compile | 2025-05-09 10:19:39.621997 | 0.405 ms |
| ├── pc_get_plan | 2025-05-09 10:19:39.622002 | 0.009 ms |
| └── hard_parse | 2025-05-09 10:19:39.622063 | 0.315 ms |
| ├── parse | 2025-05-09 10:19:39.622063 | 0.079 ms |
| └── resolve | 2025-05-09 10:19:39.622170 | 0.180 ms |
+-------------------------------+----------------------------+------------+
7 rows in set (0.01 sec)
参考
-
珞璃老师在社区论坛中发布的【技巧分享】SQL 执行报错问题排查方法
- 2025.07.17 晚上,在 OceanBase 社区公众号 “老纪的技术唠嗑局” 的视频直播活动中,珞璃老师会亲自为大家讲解 SQL 执行报错问题的排查方法,欢迎大家关注!

最后的最后,欢迎大家通过微信扫描下面的二维码,加入 OceanBase 教程学习交流群(或者添加 OB 社区小助手微信:OBCE666,备注 “实战营”,小助手会邀您进群)。

欢迎大家在课程交流群中,一起对本期课程内容进行讨论和吐槽!