【 使用环境 】生产环境 or 测试环境
https://ask.oceanbase.com/t/topic/35605619
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手 ] 即可召唤小助手,欢迎试用!
obloader导入一张销售流水数据表,目前针对1亿多数据量,半小时导入完成后,查询速度较慢,
create table if not exists da_sale
(
change_date int comment "销售日期,
store_code varchar(40) comment "门店代码,
pdt_no varchar(40) comment "商品代码,
size varchar(40) comment "尺码,
qty int comment "销量,
price decimal(14,2) comment "实收价,
pricelist int comment "吊牌价,
is_groupbuy varchar(4) comment "是否团购,
amt decimal(14,2) comment "实收金额,
amt_list int comment "吊牌金额,
tot_qty int comment "累计销量,
change_month varchar(12)
);
create index idx_da_sale on da_sale(store_code,pdt_no,change_date)
这种情况下如何排查优化
1 个赞
论坛小助手
2024 年12 月 17 日 17:44
#3
根据您提供的信息,obloader 导入大量数据后查询性能下降,这可能是由于多种因素引起的。以下是一些可能的原因和优化建议:
检查索引
数据分布和分区
数据分布 :确保数据在各个节点上均匀分布。您可以使用 EXPLAIN 查看查询计划,确认数据是否均匀分布在各个节点上。
分区表 :对于大规模数据表,建议使用分区表来提高查询性能。例如,按 change_date 或 change_month 进行分区:CREATE TABLE da_sale (
change_date INT COMMENT '销售日期',
store_code VARCHAR(40) COMMENT '门店代码',
pdt_no VARCHAR(40) COMMENT '商品代码',
size VARCHAR(40) COMMENT '尺码',
qty INT COMMENT '销量',
price DECIMAL(14,2) COMMENT '实收价',
pricelist INT COMMENT '吊牌价',
is_groupbuy VARCHAR(4) COMMENT '是否团购',
amt DECIMAL(14,2) COMMENT '实收金额',
amt_list INT COMMENT '吊牌金额',
tot_qty INT COMMENT '累计销量',
change_month VARCHAR(12)
) PARTITION BY RANGE (change_date) (
PARTITION p0 VALUES LESS THAN (20230101),
PARTITION p1 VALUES LESS THAN (20230201),
PARTITION p2 VALUES LESS THAN (20230301),
-- 添加更多分区
);
查询优化
系统参数调整
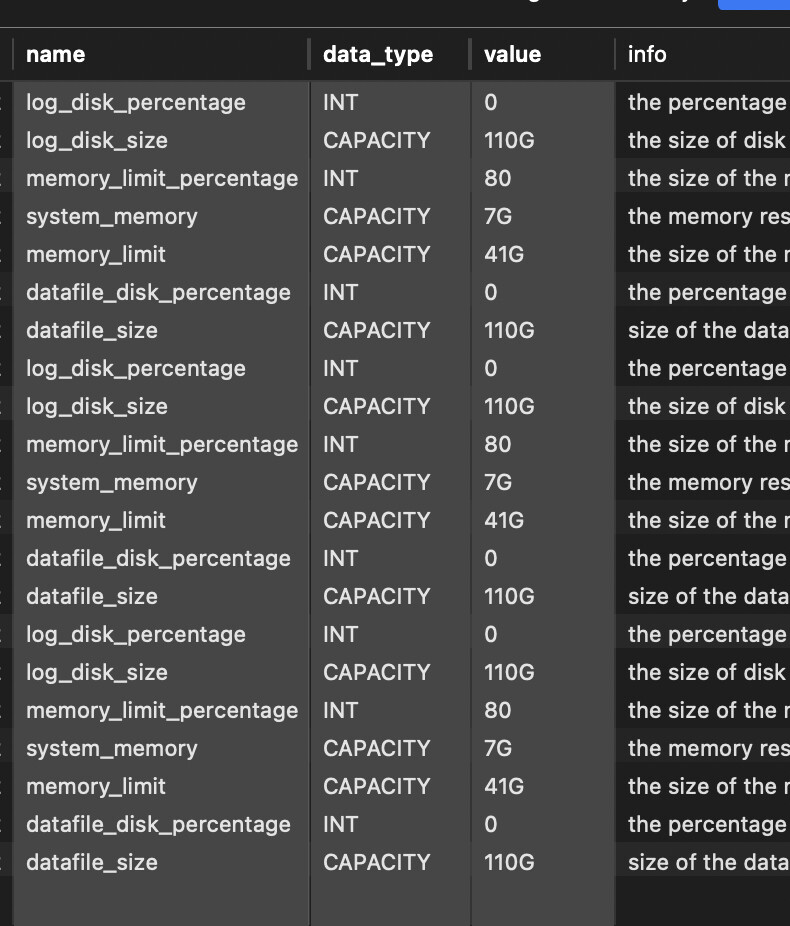
内存和缓存 :检查系统参数,确保有足够的内存和缓存来支持查询。例如,调整 memory_limit 和 memory_limit_percentage 参数。
并行度 :增加查询的并行度可以提高查询性能。您可以调整 parallel_query 相关参数。
合并操作
日志和诊断
日志分析 :使用 obdiag 工具收集诊断信息,分析日志文件,查找可能的性能瓶颈。
全链路诊断 :如果问题仍然存在,可以使用全链路诊断机制,追踪 SQL 请求在数据库全链路过程中的执行情况,帮助快速定位问题。
其他建议
硬件资源 :确保硬件资源(如 CPU、内存、磁盘 I/O)足够支持当前的查询负载。
数据预处理 :在导入数据前,可以对数据进行预处理,例如删除重复数据、优化数据格式等。
希望以上建议能帮助您优化查询性能。如果问题仍然存在,建议联系 OceanBase 的技术支持团队获取进一步的帮助。
更多信息请查看:
向量索引 使用 LOAD DATA 语句导入数据 OceanBase AP 核心特性 全链路追踪概述 OceanBase AP 概述 分布式执行和并行查询 SQL 调优典型场景和案例 obloader/obdumper 列存 FAQ 自适应合并
1 个赞
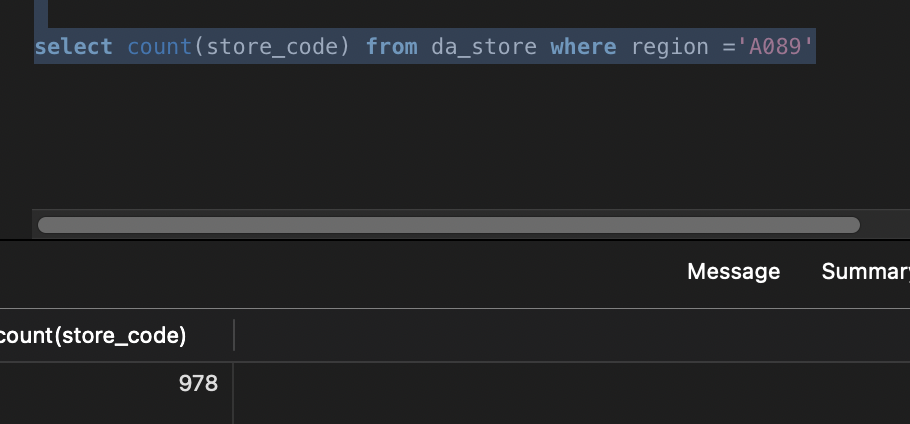
count计数查询直接超时,调整超时时间1分钟仍然失败,
1 个赞
论坛小助手
2024 年12 月 17 日 17:46
#5
根据您提供的信息,count 计数查询直接超时,即使调整超时时间到 1 分钟仍然失败,而 limit 10 查询也耗时较长。这表明查询性能存在严重问题。以下是一些详细的排查和优化建议:
检查查询计划
优化 count 查询
优化 limit 查询
使用索引 :确保 limit 查询使用了合适的索引。例如,如果经常查询前 10 条记录,可以创建一个覆盖索引:CREATE INDEX idx_limit ON da_sale(store_code, pdt_no, change_date);
避免大偏移量 :如果 limit 查询涉及较大的偏移量,可以考虑使用子查询来优化:SELECT * FROM da_sale WHERE change_date IN (SELECT change_date FROM da_sale ORDER BY change_date LIMIT 10);
调整系统参数
数据分布和分区
数据分布 :确保数据在各个节点上均匀分布。您可以使用 EXPLAIN 查看查询计划,确认数据是否均匀分布在各个节点上。
分区表 :对于大规模数据表,建议使用分区表来提高查询性能。例如,按 change_date 或 change_month 进行分区:CREATE TABLE da_sale (
change_date INT COMMENT '销售日期',
store_code VARCHAR(40) COMMENT '门店代码',
pdt_no VARCHAR(40) COMMENT '商品代码',
size VARCHAR(40) COMMENT '尺码',
qty INT COMMENT '销量',
price DECIMAL(14,2) COMMENT '实收价',
pricelist INT COMMENT '吊牌价',
is_groupbuy VARCHAR(4) COMMENT '是否团购',
amt DECIMAL(14,2) COMMENT '实收金额',
amt_list INT COMMENT '吊牌金额',
tot_qty INT COMMENT '累计销量',
change_month VARCHAR(12)
) PARTITION BY RANGE (change_date) (
PARTITION p0 VALUES LESS THAN (20230101),
PARTITION p1 VALUES LESS THAN (20230201),
PARTITION p2 VALUES LESS THAN (20230301),
-- 添加更多分区
);
合并操作
日志和诊断
日志分析 :使用 obdiag 工具收集诊断信息,分析日志文件,查找可能的性能瓶颈。
全链路诊断 :如果问题仍然存在,可以使用全链路诊断机制,追踪 SQL 请求在数据库全链路过程中的执行情况,帮助快速定位问题。
硬件资源
确保硬件资源 :确保硬件资源(如 CPU、内存、磁盘 I/O)足够支持当前的查询负载。
统计信息
更新统计信息 :确保统计信息是最新的,这有助于优化器生成更优的执行计划。您可以运行:ANALYZE TABLE da_sale;
联系技术支持
技术支持 :如果以上措施仍然无法解决问题,建议联系 OceanBase 的技术支持团队获取进一步的帮助。
希望以上建议能帮助您优化查询性能。如果问题仍然存在,建议联系 OceanBase 的技术支持团队获取更多帮助。
检索到的文档如下:
OceanBase 术语 GV$OB_SQL_AUDIT 集群管理 FAQ 分页查询 连接次序 ob_trx_idle_timeout 在您开始前 LIMIT ob_query_switch_leader_retry_timeout
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
辞霜
2024 年12 月 17 日 17:49
#6
试试使用count(1) count*无法走索引的。
是的,count(*)直接超时,count(1)基本在毫秒级别,谢谢
2 个赞
辞霜
2024 年12 月 17 日 18:02
#9
第二条select * 把* 改为所有字段名称试试
2 个赞
目前可以了,count(1)查询后,后续性能都正常,可能主要是硬解析,没走索引导致
2 个赞
淇铭
2024 年12 月 18 日 10:09
#11
如果是obloader导入的数据 建议先手动收集一下 统计信息 在去查询数据
2 个赞
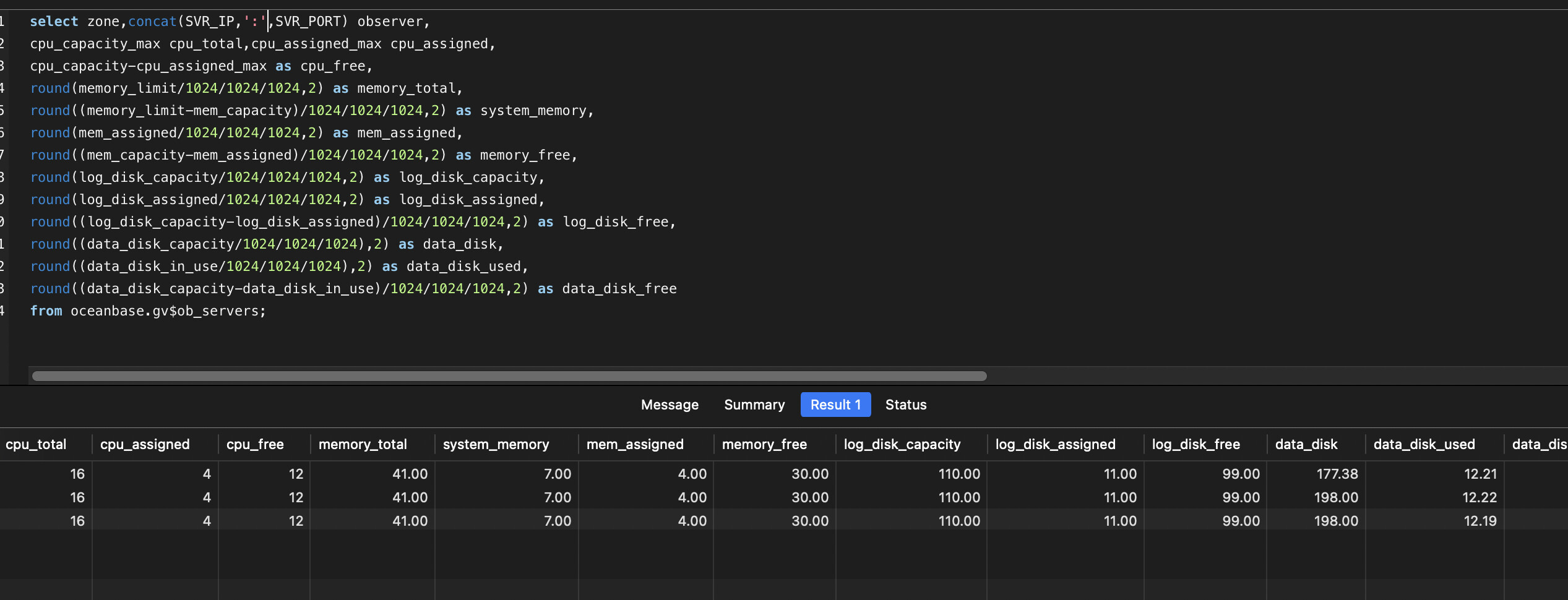
收集完成后,单表查询效率提升,最快的时候2s,针对2张表关联后做总量sum计算,长达20s
2 个赞
淇铭
2024 年12 月 18 日 13:40
#13
1、两个表结构发一下https://www.oceanbase.com/docs/common-obdiag-cn-1000000001768178
1 个赞
is_global_index=false是不是这个有关
2 个赞
淇铭
2024 年12 月 18 日 14:12
#16
1、把da_sale_imp2表结构 也发一下https://www.oceanbase.com/docs/common-obdiag-cn-1000000001768178
CREATE TABLE da_sale_imp2 (change_date int(11) DEFAULT NULL COMMENT ‘销售日期’,store_code varchar(40) DEFAULT NULL COMMENT ‘门店代码’,pdt_no varchar(40) DEFAULT NULL COMMENT ‘商品代码’,size varchar(40) DEFAULT NULL COMMENT ‘尺码’,qty int(11) DEFAULT NULL COMMENT ‘销量’,price decimal(14,2) DEFAULT NULL COMMENT ‘实收价’,pricelist int(11) DEFAULT NULL COMMENT ‘吊牌价’,is_groupbuy varchar(4) DEFAULT NULL COMMENT ‘是否团购’,amt decimal(14,2) DEFAULT NULL COMMENT ‘实收金额’,amt_list int(11) DEFAULT NULL COMMENT ‘吊牌金额’,tot_qty int(11) DEFAULT NULL COMMENT ‘累计销量’,change_month varchar(12) DEFAULT NULL
/*+
da_store:
EXPLAIN EXTENDED SELECT
/*+
da_store:
1 个赞
目前查询仍然是20S以上,obdiag目前未部署,mac上可以本地部署吗,有没有推荐的文档
1 个赞
表结构基本是这种,目前尝试了三种,未分区,分区模式,列存模式,关联查询反馈基本是一致的
1 个赞
淇铭
2024 年12 月 18 日 14:40
#20
你的ob集群搭建的什么环境上?结构什么样的
1 个赞
sql_result-2.txt (1.1 MB)