【 使用环境 】测试环境
2、是否部分配置不合理引起,实际上我们其他环境未出现类似问题。
【SOP系列 22 】——故障诊断第一步(自助诊断和诊断信息收集)
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手 ] 即可召唤小助手,欢迎试用!
1 个赞
论坛小助手
2024 年11 月 5 日 10:37
#3
根据您的描述,OceanBase 测试环境中的内存使用率逐步升高,并且出现了 HY001, 4013, No memory or reach tenant memory limit 的异常。这表明租户的内存资源已经达到了上限,可能是由于数据写入量过大、未做限流、或者某些内存模块使用过多等原因导致。
日志采集 :
obdiag gather scene run --scene=observer.memory
该命令会收集与内存使用相关的日志和信息,包括但不限于内存使用情况、内存分配和回收记录等。
根因分析 :
obdiag rca run --scene=transaction_other_error
该命令会分析事务执行过程中遇到的内存相关错误,帮助确定具体的内存超限原因。
当前租户的内存配置 :请提供租户的 memory_size 和 memstore_limit 配置。
近期的数据写入情况 :是否有大量的数据写入操作?是否有新的业务上线或数据导入?
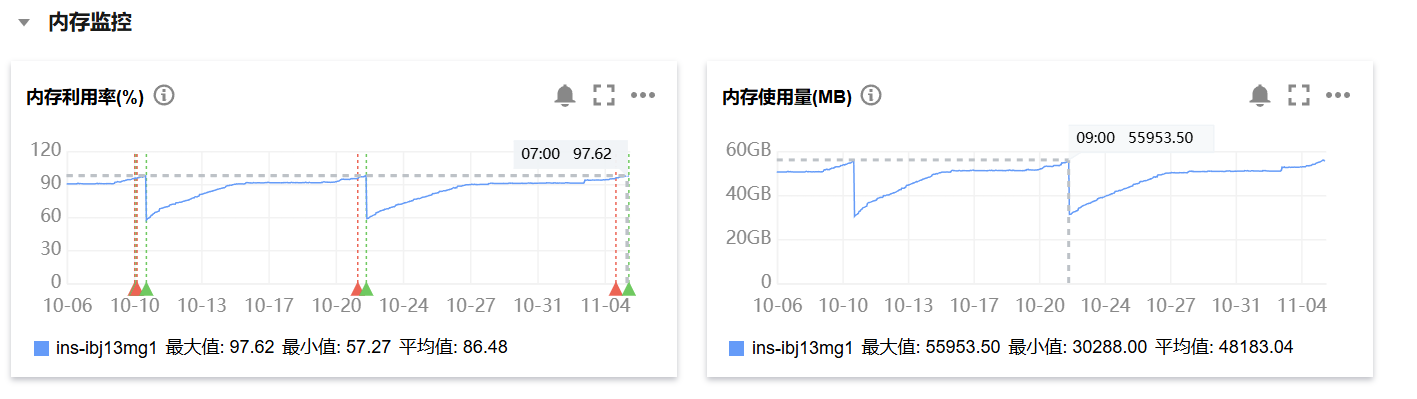
内存使用监控 :是否有监控工具记录了内存使用的变化趋势?如果有,请提供相关图表或数据。
系统日志 :是否有其他系统级别的日志(如操作系统日志)显示内存使用异常?
业务场景 :当前租户的主要业务场景是什么?是否有特定的业务操作可能导致内存使用激增?
通过以上信息,我们可以更准确地定位问题并提供解决方案。感谢您的配合!
具体信息可参考以下文档:
常见内存问题 4000 ~ 4499
附上敏捷诊断工具 obdiag 使用帮助链接
1 个赞
淇铭
2024 年11 月 5 日 10:54
#4
1 个赞
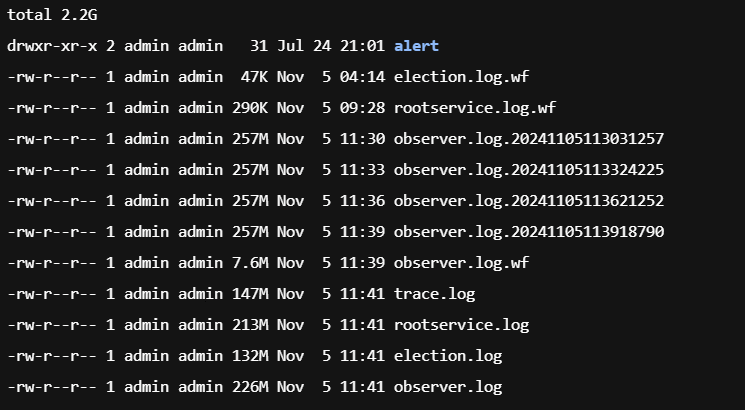
老师,我发现,当前日志已经被清空了。
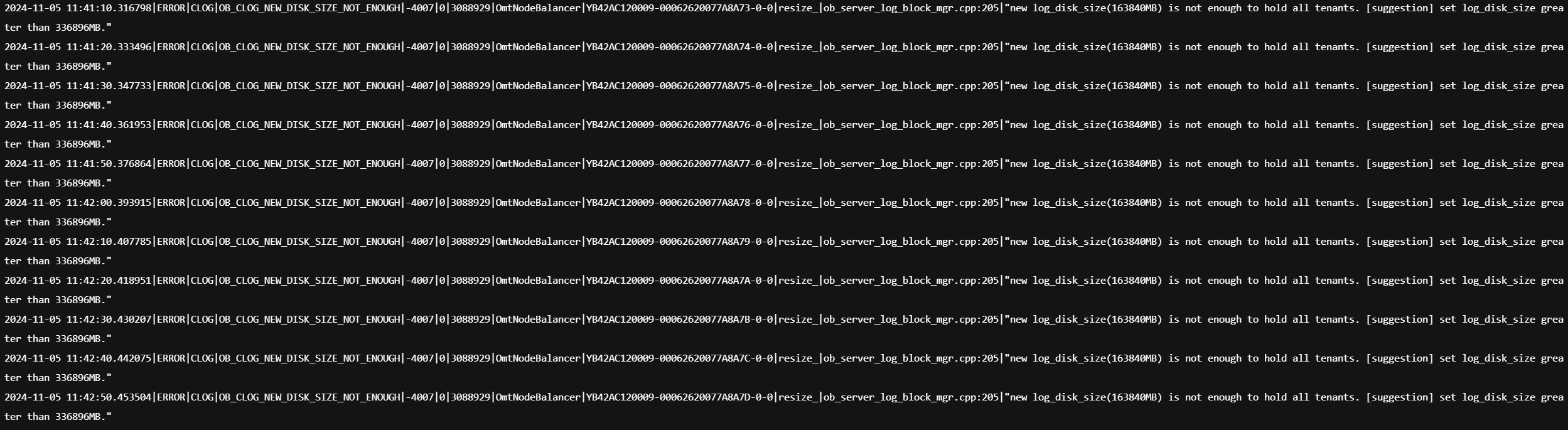
另外,咨询一下,alert.log日志出现以下异常:
1 个赞
论坛小助手
2024 年11 月 5 日 11:49
#6
根据您提供的信息,当前日志已经被清空,并且 alert.log 日志中出现了 OB_CLOG_NEW_DISK_SIZE_NOT_ENOUGH 的异常。这些异常提示日志盘的空间不足,无法容纳所有租户的日志。
日志盘空间不足 :
alert.log 中的错误信息 OB_CLOG_NEW_DISK_SIZE_NOT_ENOUGH 表明当前日志盘的空间不足,无法满足所有租户的需求。
建议的解决方案是增加日志盘的大小,使其大于 336896MB。
日志文件被清空 :
日志文件被清空可能是由于日志轮转或日志归档策略导致的。OceanBase 默认会进行日志轮转,当日志文件大小达到 256MB 时,系统会进行日志轮转,并生成新的日志文件。
如果日志文件被清空,可以检查日志归档配置,确保日志文件不会被频繁删除。
检查日志盘空间 :
使用以下 SQL 语句检查日志盘的使用情况:SELECT tenant_id, svr_ip, svr_port,
LOG_DISK_IN_USE / 1024 / 1024 / 1024 AS LOG_DISK_IN_USE_G,
LOG_DISK_SIZE / 1024 / 1024 / 1024 AS LOG_DISK_SIZE_G,
LOG_DISK_IN_USE * 100 / LOG_DISK_SIZE AS LOG_DISK_USED_PERCENTAGE
FROM GV$OB_UNITS;
增加日志盘空间 :
如果日志盘空间不足,可以通过以下步骤增加日志盘空间:
检查日志归档配置 :
确保日志归档配置合理,避免日志文件被频繁删除。可以通过以下配置项进行调整:
收集诊断信息 :
希望以上步骤能帮助您解决问题。如有进一步的问题,请随时联系 OceanBase 的技术支持团队。
详情请参考:
日志概述 日志 日志同步问题 使用 LOAD DATA 语句导入数据 无主
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
1 个赞
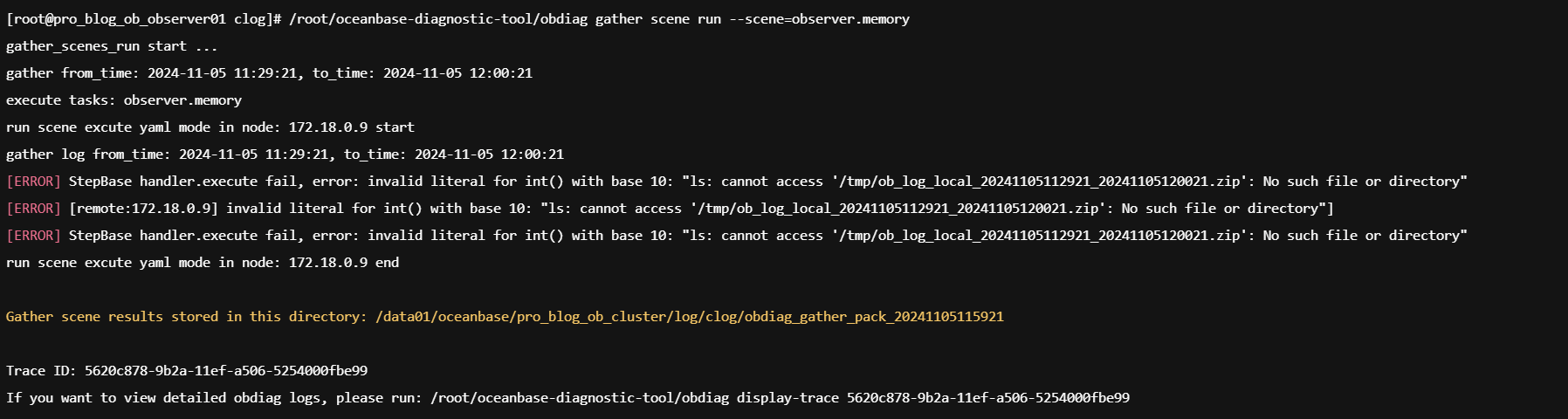
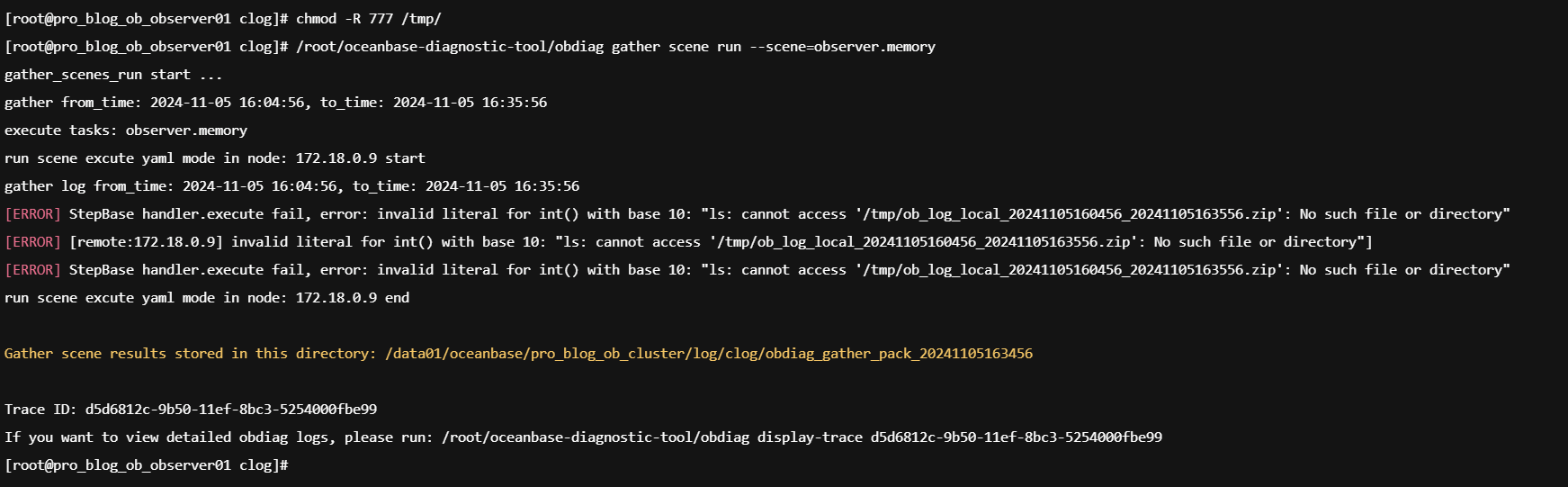
这个命令执行有点小问题,是我没配置好吗?执行其他倒是正常。
observer.logobserver.log (1).tar.gz (19.5 MB)
1 个赞
淇铭
2024 年11 月 5 日 13:54
#8
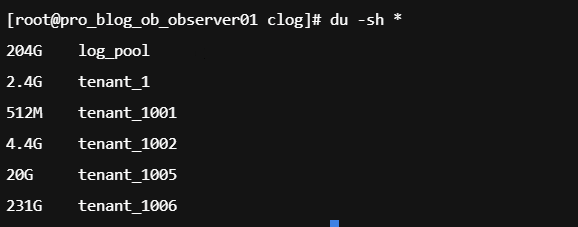
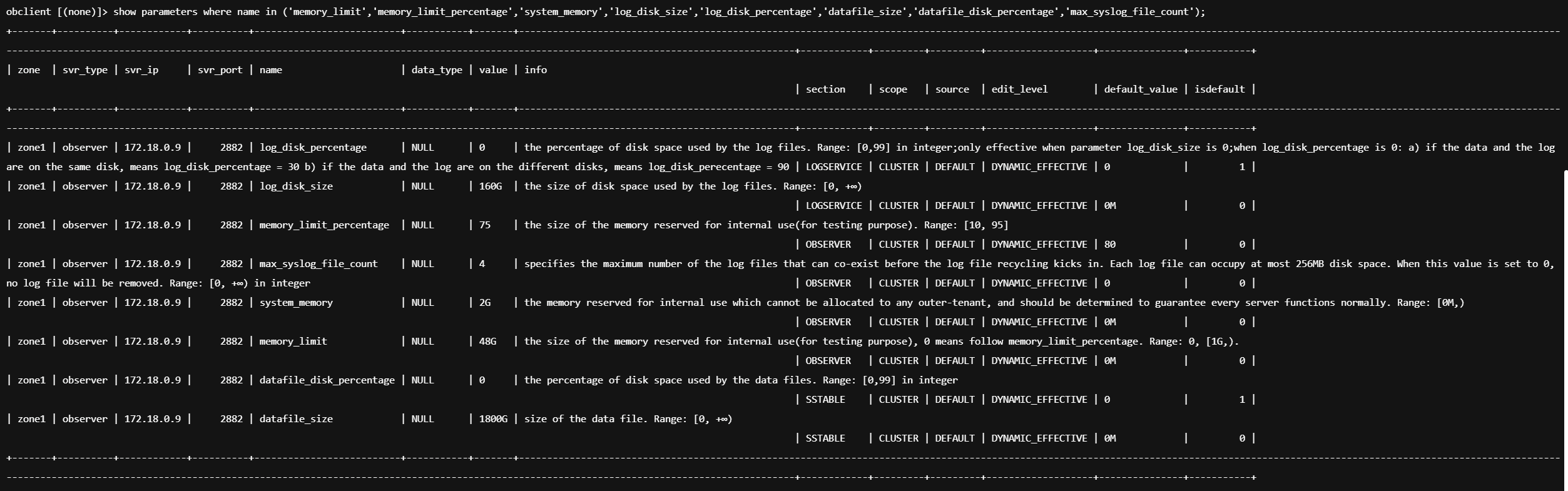
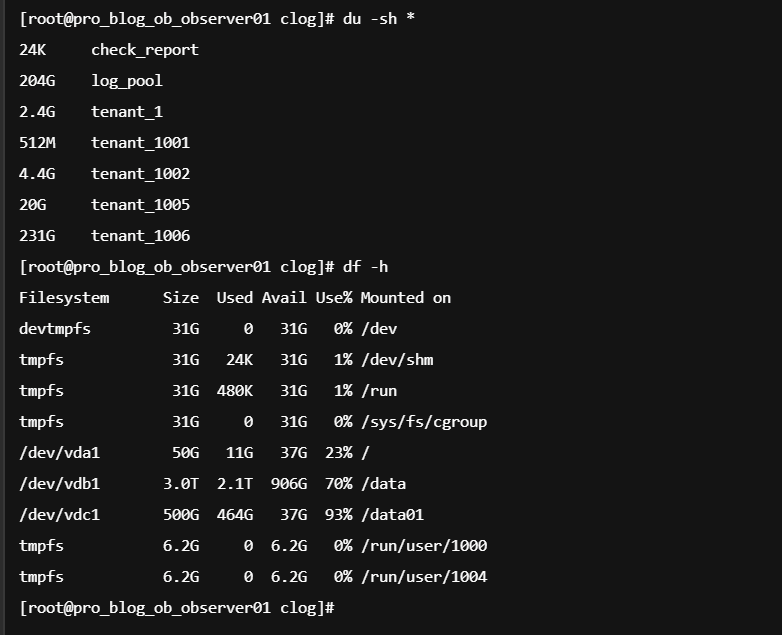
日志清空了 就不好查了 日志设置的空间不够 log_disk_size这个参数设置的过小了 是内存memory_limit的三到四倍
老师,你好,
后面我们此前已经增加过log_disk_size,好像没体现在参数上,实际情况如下:
1 个赞
AntTech_ZUHSV7:
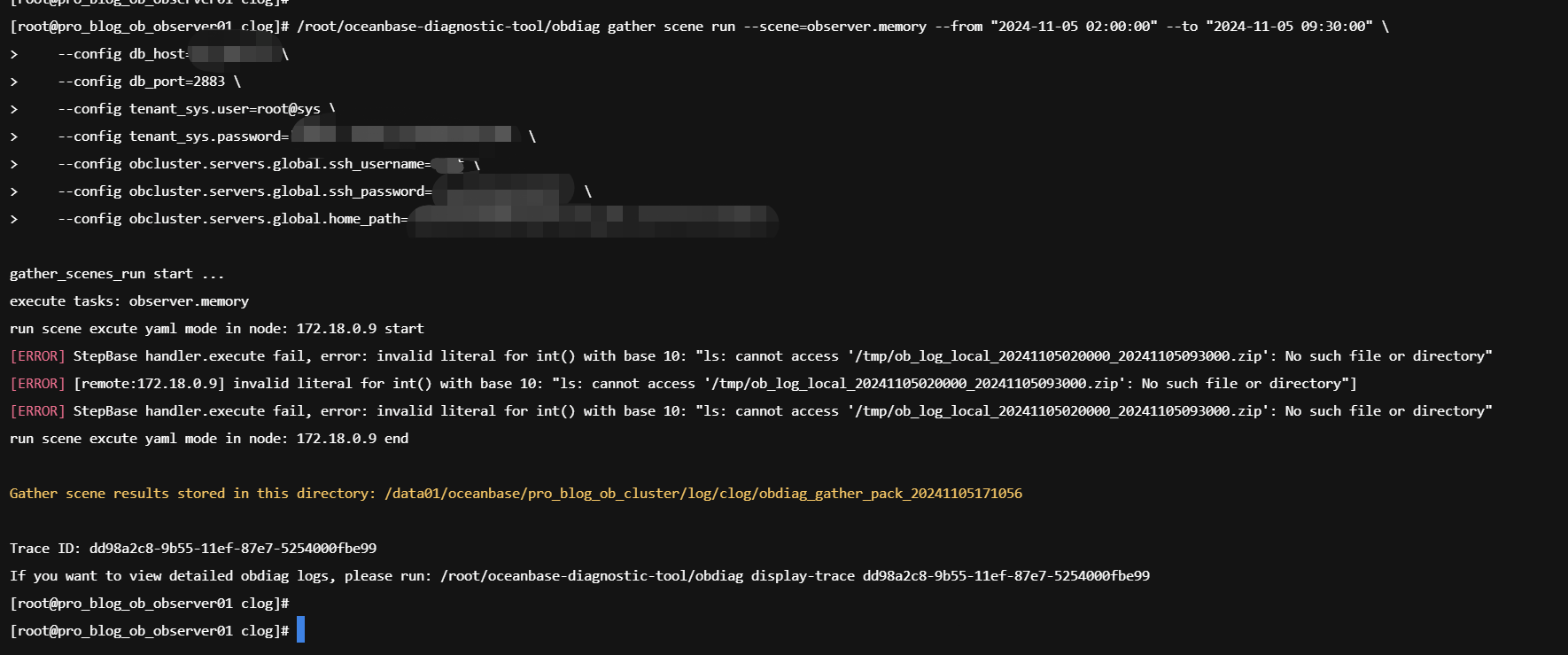
另外,老师,请问执行:obdiag gather scene run --scene=observer.memory
失败的原因是什么没配置好吗?
1 个赞
淇铭
2024 年11 月 5 日 16:31
#12
我楼上回复你了 看着是/tmp这个文件夹 没有权限写入
淇铭
2024 年11 月 5 日 16:34
#13
我看你设置了这个参数 memory_limit_percentage 你的物理内存看一下 cat /proc/meminfo
老师,麻烦看看。
[root@test clog]# cat /proc/meminfo
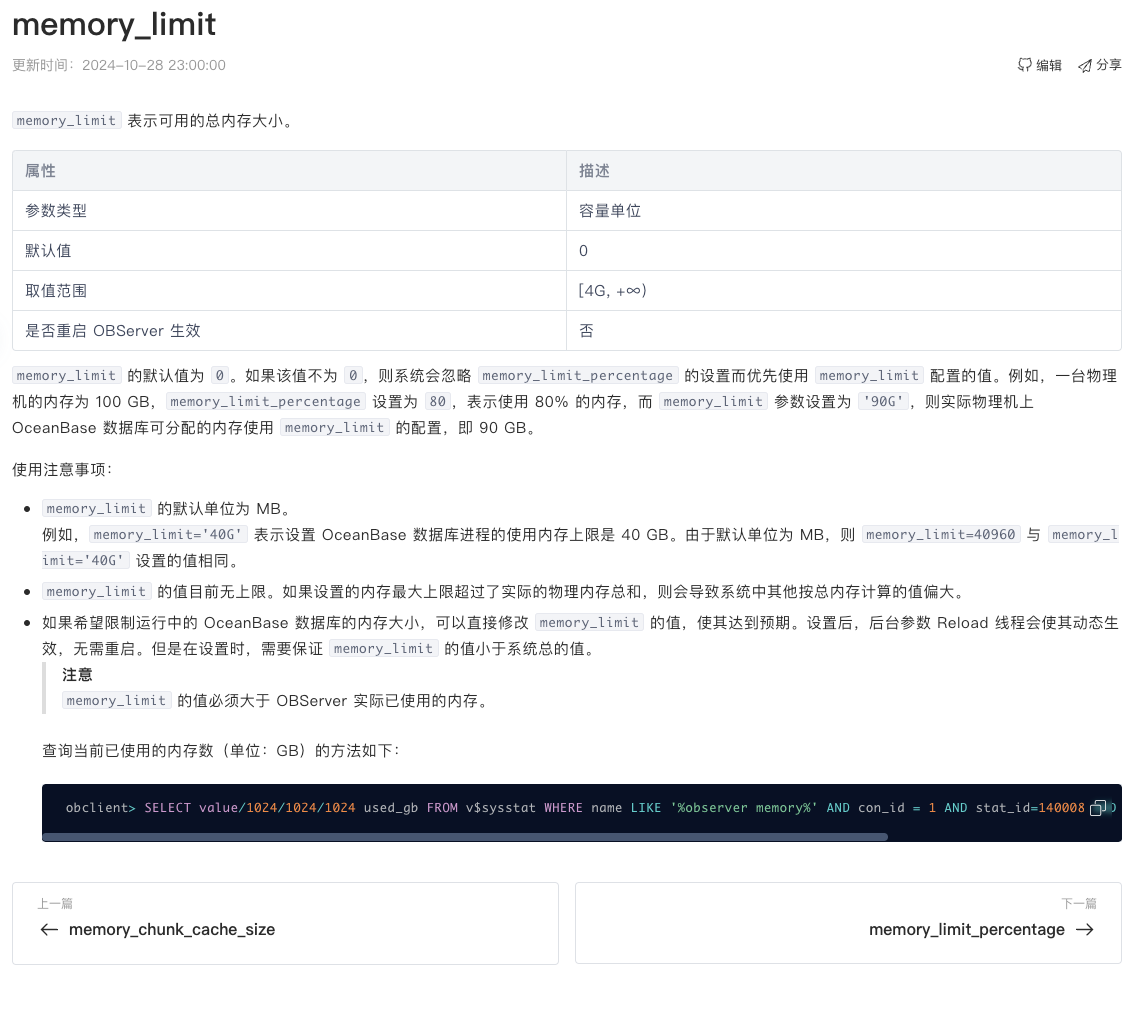
另外,是否配置 memory_limit_precent,而非配置 memory_limit 比较好呢?
淇铭
2024 年11 月 5 日 16:56
#17
memory_limit_precent可以根据物理内存动态扩容 比如物理内存扩大了 这个参数会根据物理内存计算
1 个赞
靖顺
2024 年11 月 5 日 16:59
#18
明白了。我们服务器配置会维持一段时间,所以使用memory_limit 和memory_limit_precent 影响应该不大。
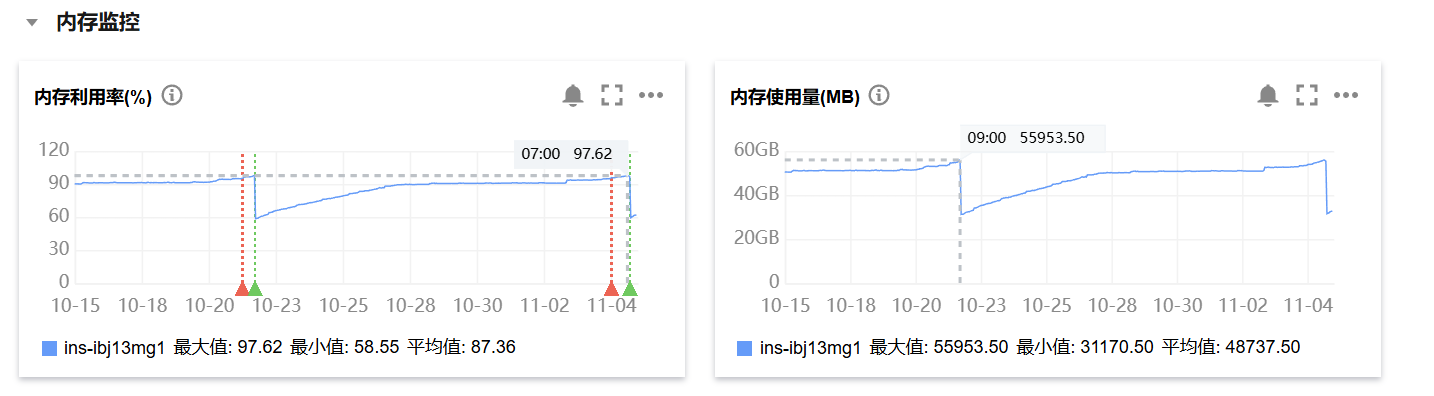
目前内存使用率是正常的,但是还是看出逐步上升的情况。
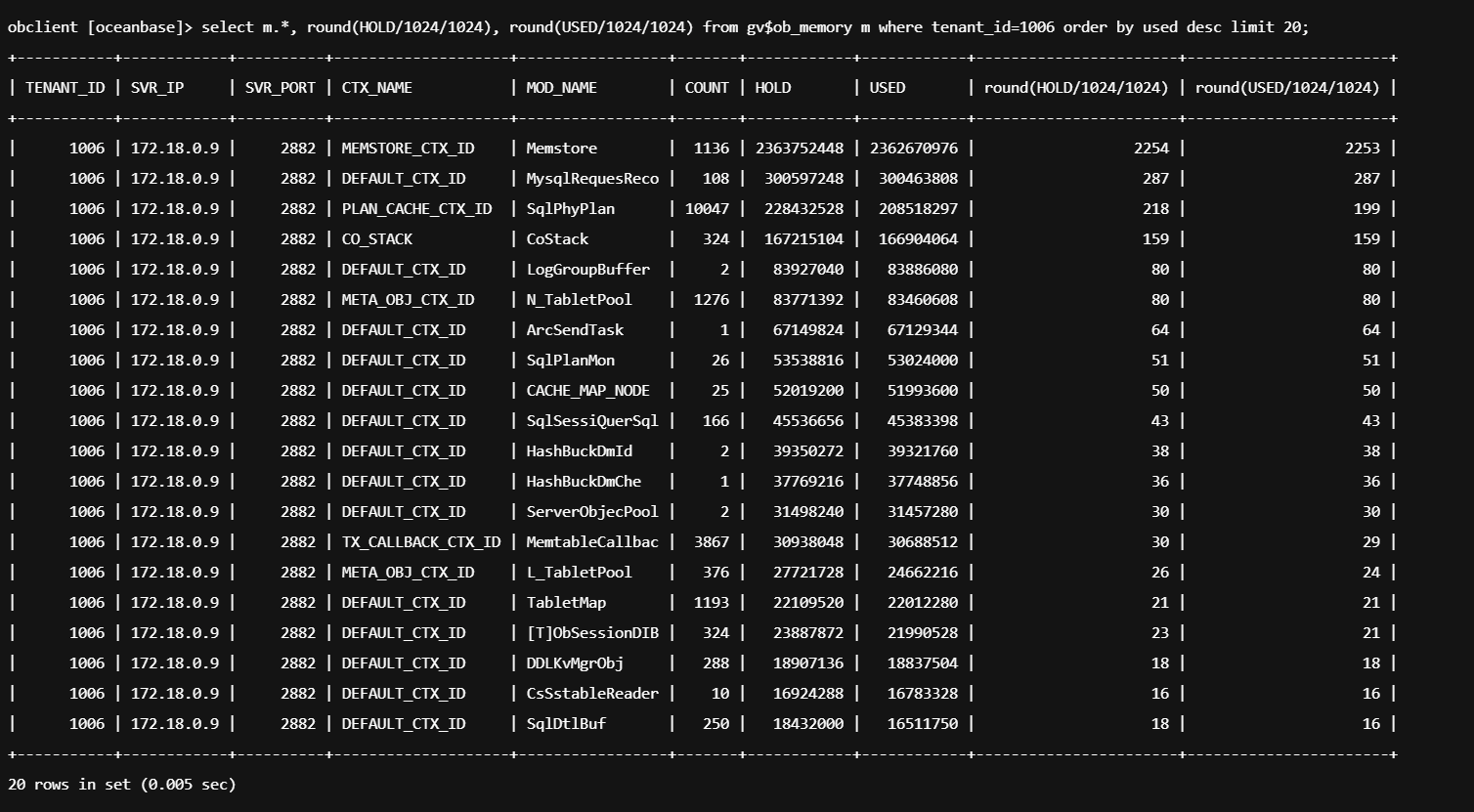
里面比较大的租户是1006。
靖顺
2024 年11 月 5 日 17:12
#21
看到obdiag在内存收集这个场景使用报错了,帮忙提供一下obdiag的版本, obdiag --version
另外obdiag check 可以帮你做巡检,扫一下看看内存的这个问题是不是有已知的问题存在。