【 使用环境 】测试环境
测试场景:
普通堆表
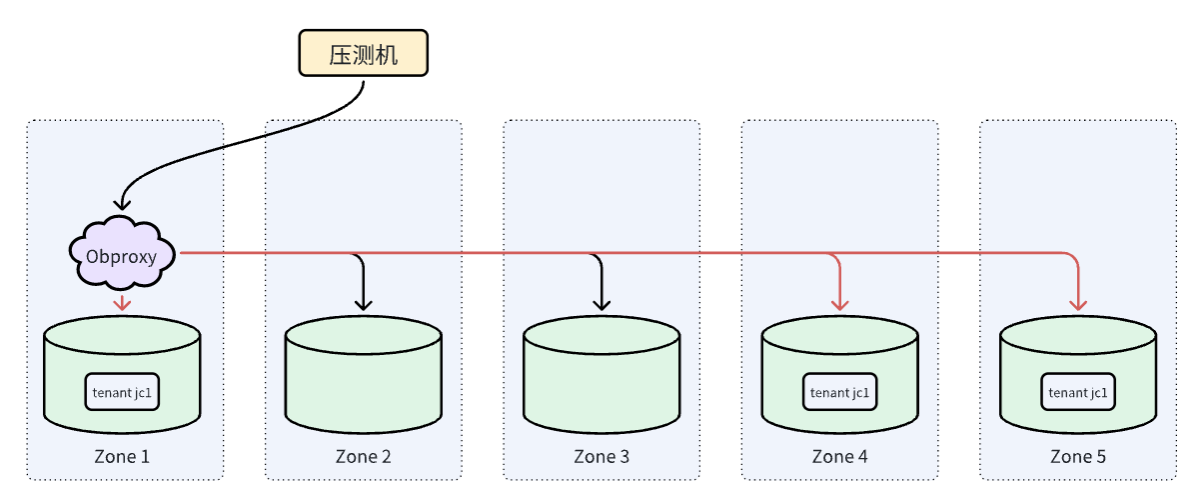
Primary zone 的设置是 zone1;zone4,zone5,primary 在 zone1,zone4和 zone5 是 follower
测试方式 sysbench read_write_mix
链接方式:obproxy
场景 1 - Primary zone
2)EC2 异常重启(在 zone2 新增一个 obproxy,测试时链接的是该 obproxy),observer 进程未随机自动重启, 测试过程中发现下述现象,不太符合预期,我理解会影响 tps 但是不应该出现掉 0:
b. 原 primary zone observer 进程重启后,会被重新选举为 primary,TPS 表现较为平稳,没有出现 a 的情况
场景 2 - Follower zone
a. follower zone 的 observer 进程异常后,对 TPS 影响比较明显
b. observer 进程重启后,对 TPS 影响明显,甚至出现掉 0
2)EC2 异常重启,observer 进程未随机自动重启,下述的 b 项不符合预期,导致该问题的原因可能是什么?
a. 对 TPS,response time 均无明显影响
b. 重启 follower zone 的EC2 上的 observer 进程后,观察到对 TPS 有明显影响
2 个赞
旭辉
2024 年11 月 4 日 18:25
#3
场景 1 - Primary zone
–primary选举期间 及回切期间 TPS应该都会出现掉0
2)EC2 异常重启(在 zone2 新增一个 obproxy,测试时链接的是该 obproxy),observer 进程未随机自动重启, 测试过程中发现下述现象,不太符合预期,我理解会影响 tps 但是不应该出现掉 0:
–这里的EC2是指什么?
场景 2 - Follower zone
1)observer 进程异常终止,有两个疑问,不确定原因以及是否符合预期。我的预期是 follower zone 的 observer 进程重启前后,对 TPS 都应该没有太多的负面影响。实测的结果如下:
a. follower zone 的 observer 进程异常后,对 TPS 影响比较明显
b. observer 进程重启后,对 TPS 影响明显,甚至出现掉 0
– 这里应该不符合预期
2)EC2 异常重启,observer 进程未随机自动重启,下述的 b 项不符合预期,导致该问题的原因可能是什么?
a. 对 TPS,response time 均无明显影响
b. 重启 follower zone 的EC2 上的 observer 进程后,观察到对 TPS 有明显影响
–这里的EC2是指什么?
2 个赞
旭辉
2024 年11 月 5 日 17:14
#5
你这里每个zone是一台observer吗?EC2是指zone的第二台云主机?
是的,一共 5 个 zone,每个zone 有一台云主机(EC2)
旭辉
2024 年11 月 6 日 15:00
#7
场景1 的第1个小场景是符合预期的,你设置了primary zone必然会发生切主,可以参考下你提的这个帖子
【 使用环境 】测试环境
【 使用版本 】v4.3.2
【问题描述】目前在做版本升级以及高可用相关的测试,对 OB 切主的时机有一些疑问:
根据文档的描述 RS 只是在接收各个 Observer 上报的元信息,在不同的场景下,RS 承担的角色不同?比如磁盘,服务器故障等,根据心跳以及操作系统层面的信息情况来判断是否会主动触发切主,或者补数据副本的操作?官方文档的描述如下:
“OBSer…
场景1 的第2个小场景
场景 2 - Follower zone
2)EC2 异常重启,observer 进程未随机自动重启 --这里怎么理解?是说observer服务器异常重启,observer进程没有自动重启?怎么观察到的?