【 使用环境 】 测试环境
【 OB or 其他组件 】
【 使用版本 】4.2.0
【问题描述】
服务器因cpu过载,进行了重启。
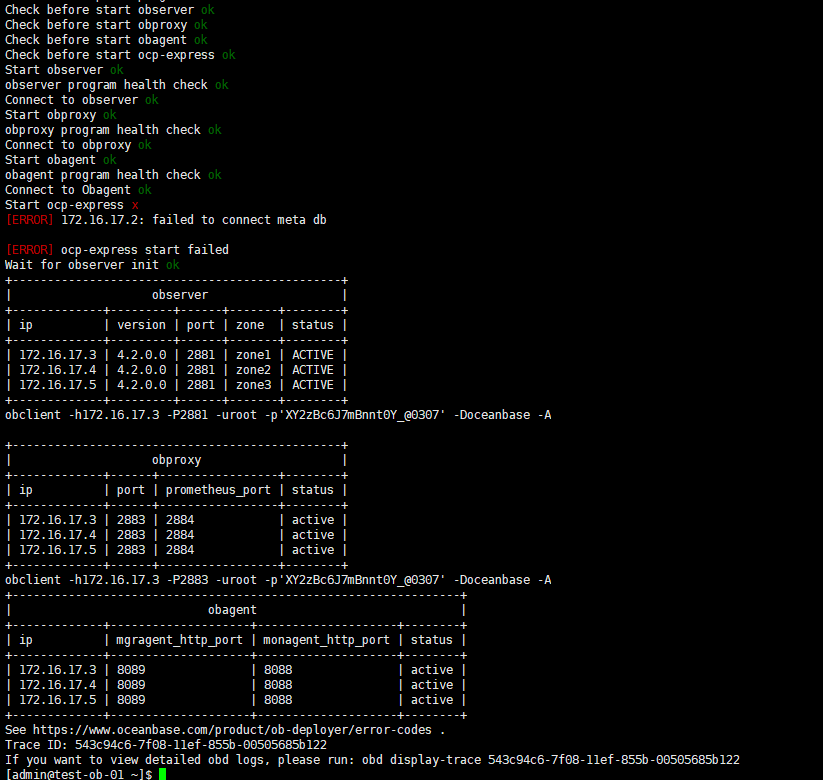
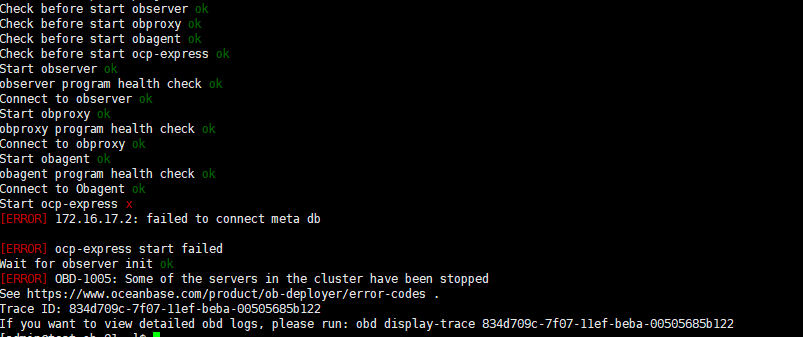
通过obd 命令启动集群,一直无法启动成功。
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
【 使用环境 】 测试环境
【 OB or 其他组件 】
【 使用版本 】4.2.0
【问题描述】
服务器因cpu过载,进行了重启。
通过obd 命令启动集群,一直无法启动成功。
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
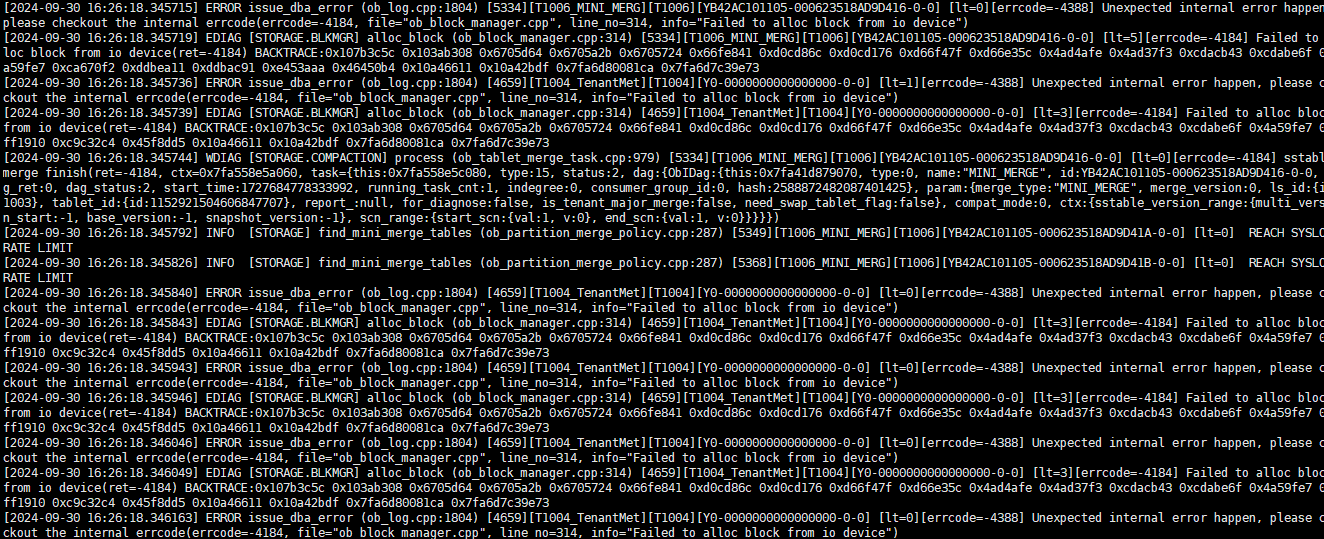
根据您提供的日志信息,问题主要集中在“Failed to alloc block from io device”,这表明在尝试分配磁盘块时遇到了问题,可能是由于磁盘空间不足或磁盘损坏导致的。此外,您提到服务器因CPU过载进行了重启,这可能进一步影响到了存储设备的状态。以下是针对这个问题的一些建议:
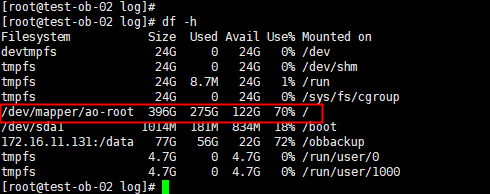
检查磁盘空间:首先确认是否有足够的磁盘空间来启动OceanBase集群。可以通过执行df -h命令来查看磁盘使用情况。如果磁盘空间不足,您需要清理不必要的文件或增加磁盘容量。
检查磁盘健康状态:使用smartctl -a /dev/sdX(替换sdX为实际的磁盘设备名)命令来检查磁盘的SMART状态,确认磁盘是否存在硬件故障。如果磁盘存在问题,可能需要更换磁盘。
调整内存配置:如果内存不足也可能导致启动失败。您可以尝试调整集群的内存配置。具体操作是使用obd cluster edit-config <deploy name>命令打开配置文件,调整memory_limit和system_memory的值 [1]。通常情况下,memory_limit/3 ≤ system_memory ≤ memory_limit/2。对于OceanBase数据库4.x版本,memory_limit不能低于6GB。
释放缓存:如果内存不足但存在可以释放的cached内存,可以尝试释放缓存来增加可用内存。执行以下命令之一:
sudo sysctl -w vm.drop_caches=1
# 或
sudo echo 1 > /proc/sys/vm/drop_caches
查看日志详细信息:如果上述步骤未能解决问题,建议查看更详细的日志信息。您可以使用obd display-trace <cluster name>命令来获取更多的诊断信息 [1]。
使用obdiag工具:推荐使用OceanBase敏捷诊断工具obdiag来收集诊断信息,以便于进一步分析问题原因。详情参见链接:https://ask.oceanbase.com/t/topic/35605619。
综上所述,首先应检查磁盘空间和健康状态,然后根据需要调整内存配置或释放缓存。如果问题依旧存在,建议使用obdiag工具进一步诊断。 [1]
更多信息请查看:
发一下obd.log和observer.log的日志 尽量发一个全的日志 有助于分析
也可以按照论坛小助手说的 obdiag分析
obdiag rca run --scene=log_error
这个日志也发一下
/var/log/messages
看起来是无法从磁盘分配空间了,
df -h 看下
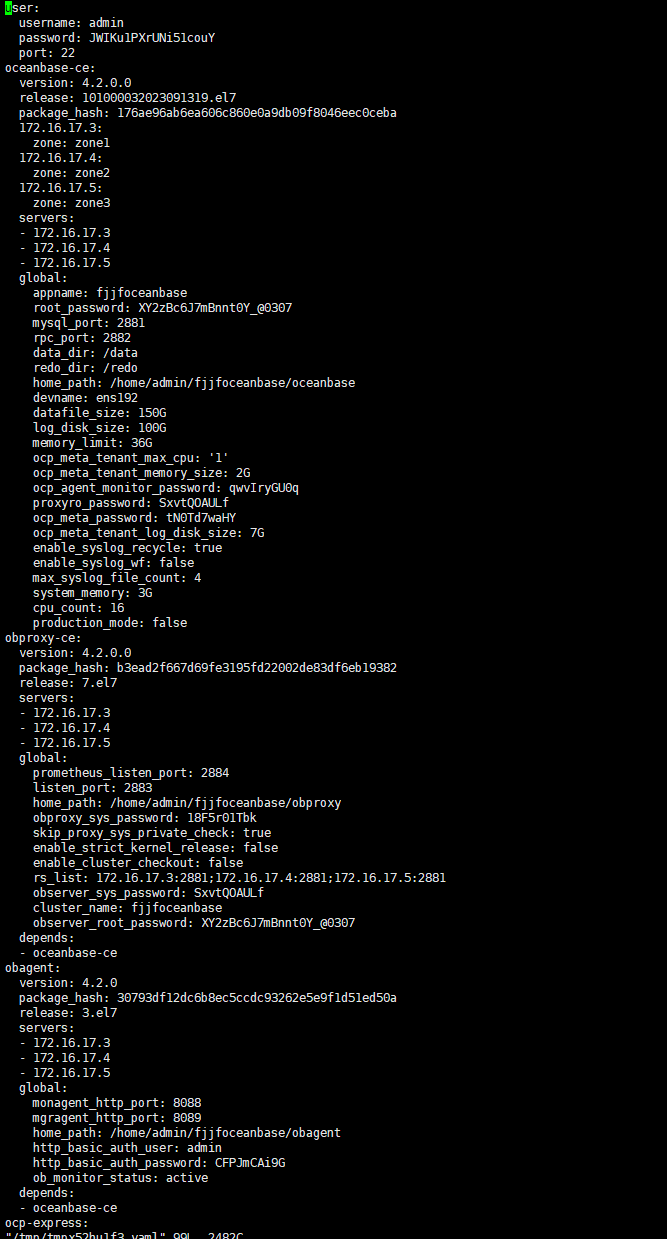
发下yaml配置文件
发下完整的observer.log
磁盘可能是有问题,我能如何清理?
我现在分配了足够磁盘给他了,但是我看又没实际生效。
看着配置文件没有全部发完 尽量obd.log和observer.log的日志 全部都发一下
启动ocp-express报错了 日志发过来具体分析
日志已经上传
根据您提供的信息,您已经分配了足够的磁盘空间给OceanBase集群,但从日志来看,似乎并没有实际生效。这可能是因为OceanBase集群尚未正确识别到新的磁盘空间分配。以下是一些可能的原因和解决方案:
首先确保新分配的磁盘空间已经被正确挂载到OceanBase集群所需的目录。您可以使用df -h命令来检查磁盘挂载情况,并确认是否已经挂载到预期的位置。例如,OceanBase集群通常会将数据存储在/data目录下,因此请确保该目录有足够的空间。
如果磁盘已经正确挂载,但集群仍然无法识别新的磁盘空间,您可以尝试重新初始化集群。具体步骤如下:
# 停止集群
obd cluster stop <cluster_name>
# 删除集群数据
rm -rf /data/*
# 重新初始化集群
obd cluster init <cluster_name>
如果重新初始化集群后仍然存在问题,您可以尝试调整集群的配置文件,确保配置文件中的磁盘路径设置正确。使用以下命令编辑配置文件:
obd cluster edit-config <cluster_name>
在配置文件中,确保data_dir和redo_dir指向正确的磁盘路径。例如:
data_dir: /data
redo_dir: /data
如果以上步骤仍然无法解决问题,建议查看集群的日志文件,以获取更详细的错误信息。您可以使用以下命令查看日志:
tail -f /data/observer.log
最后,推荐使用OceanBase敏捷诊断工具obdiag来收集诊断信息,以便于进一步分析问题原因。详情参见链接:https://ask.oceanbase.com/t/topic/35605619。
假设您已经分配了新的磁盘空间,并将其挂载到/data目录,您可以按照以下步骤操作:
# 检查磁盘挂载情况
df -h
# 停止集群
obd cluster stop test-ob-62
# 删除集群数据
rm -rf /data/*
# 重新初始化集群
obd cluster init test-ob-62
# 编辑配置文件
obd cluster edit-config test-ob-62
# 在配置文件中设置正确的磁盘路径
data_dir: /data
redo_dir: /data
# 启动集群
obd cluster start test-ob-62
df -h命令检查磁盘挂载情况。希望这些步骤能帮助您解决问题。如果问题依然存在,请提供更多详细信息以便进一步诊断。
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
user:
username: admin
password: JWIKu1PXrUNi51couY
port: 22
oceanbase-ce:
version: 4.2.0.0
release: 101000032023091319.el7
package_hash: 176ae96ab6ea606c860e0a9db09f8046eec0ceba
172.16.17.3:
zone: zone1
172.16.17.4:
zone: zone2
172.16.17.5:
zone: zone3
servers:
1001租户,1005租户clog空间满了,clog有自动清理机制,不能手动删除
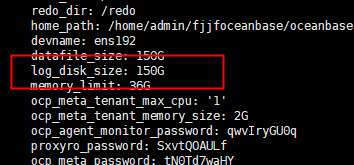
yaml文件中 log_disk_size 先尝试扩容为150G ,再重启试下
修改方式:obd cluster edit-confog 部署名称 --修改参数
收到,我试下。
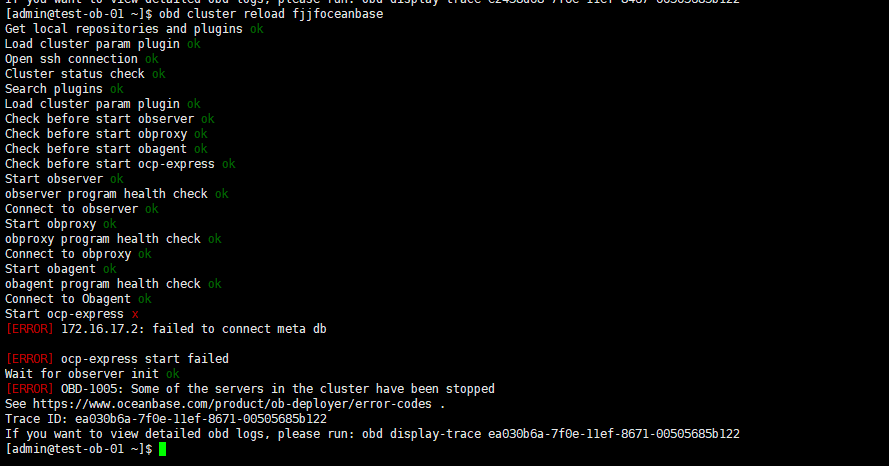
但是启动时用 start命令,它提示我要用reload
截图看下,直接reload也可以
启动报错的情况下,数据库现在能连接了。
ocp_meta_tenant_log_disk_size 也调整下,按同样的方式调整为10G,再试下
如果不生效,带参数启动下
进入ob安装路径 bin目录下
./bin/observer -o “log_disk_size=150G,ocp_meta_tenant_log_disk_size=10G,log_disk_utilization_threshold=95,log_disk_utilization_limit_threshold=98”
或者
./bin/observer -o “log_disk_size=150G,ocp_meta_tenant_log_disk_size=10G,log_disk_utilization_threshold=95,log_disk_utilization_limit_threshold=98”
如果报错libmariadb.so.3: cannot open shared object file修复方式:#将 OceanBase 数据库的 LIB 加到环境变量 LD_LIBRARY_PATH 中,按实际路径替换下面路径即可。echo ‘export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/oceanbase-ce/lib/’ >> ~/.bash_profileexport LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/oceanbase-ce/lib/
这个用什么命令调?