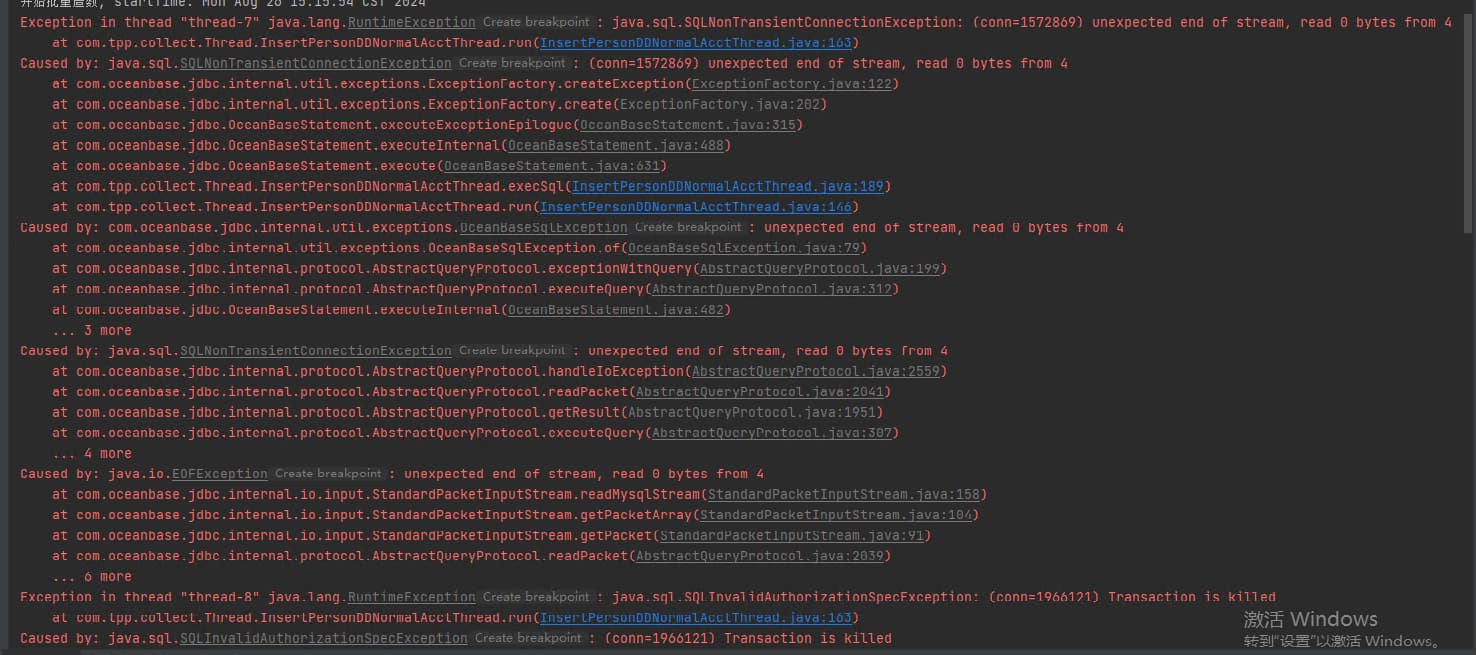
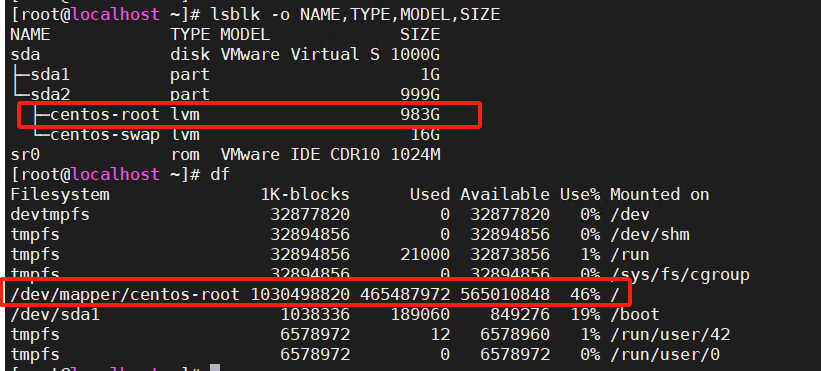
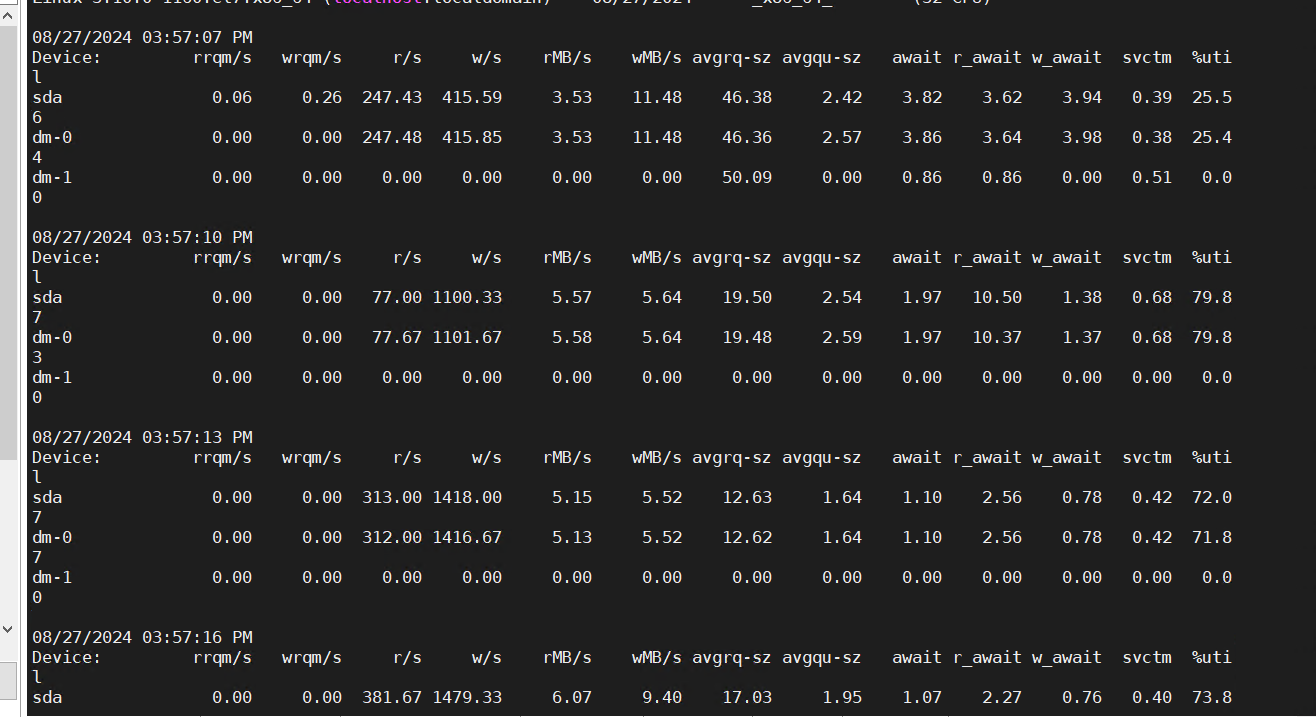
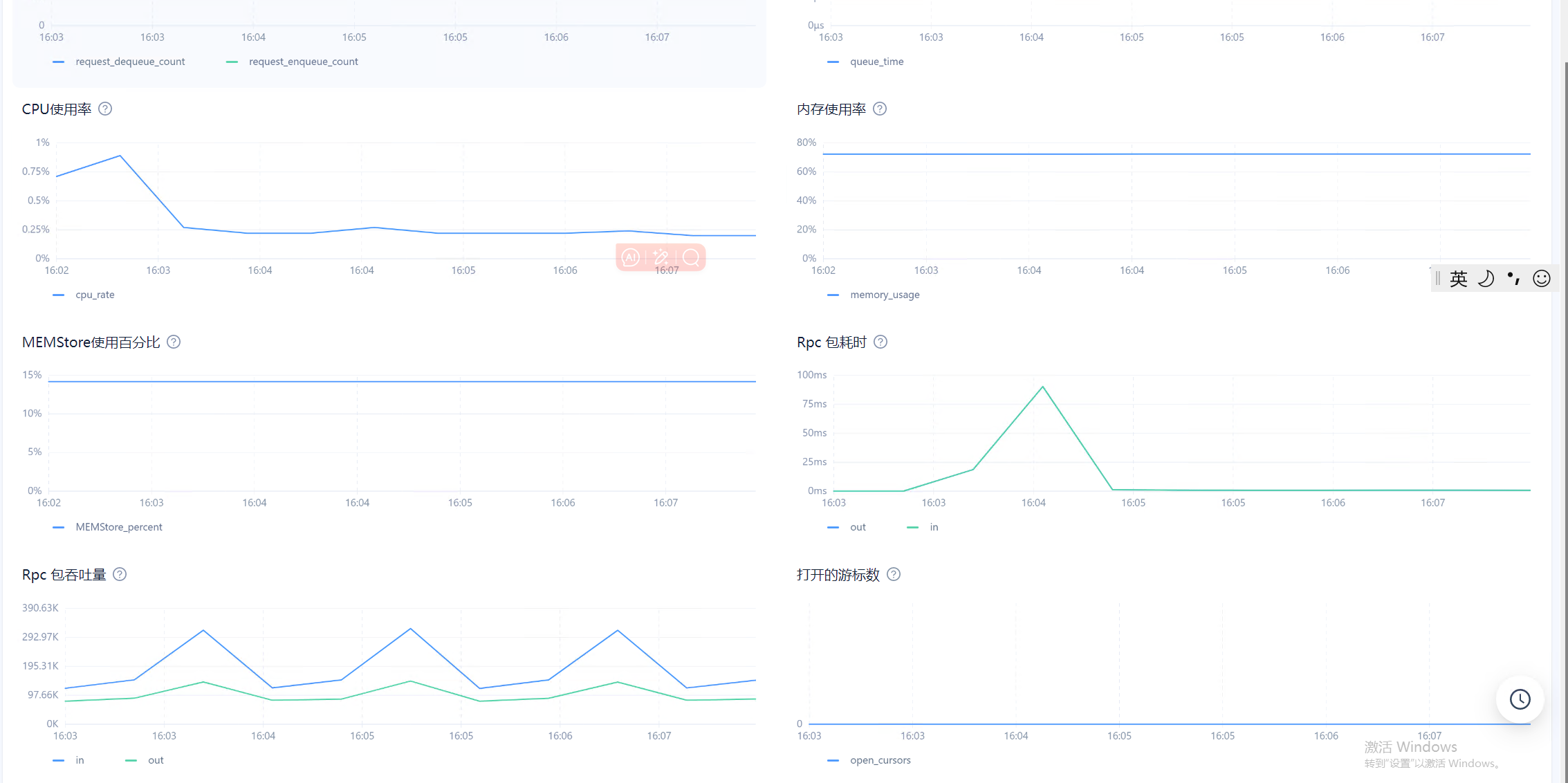
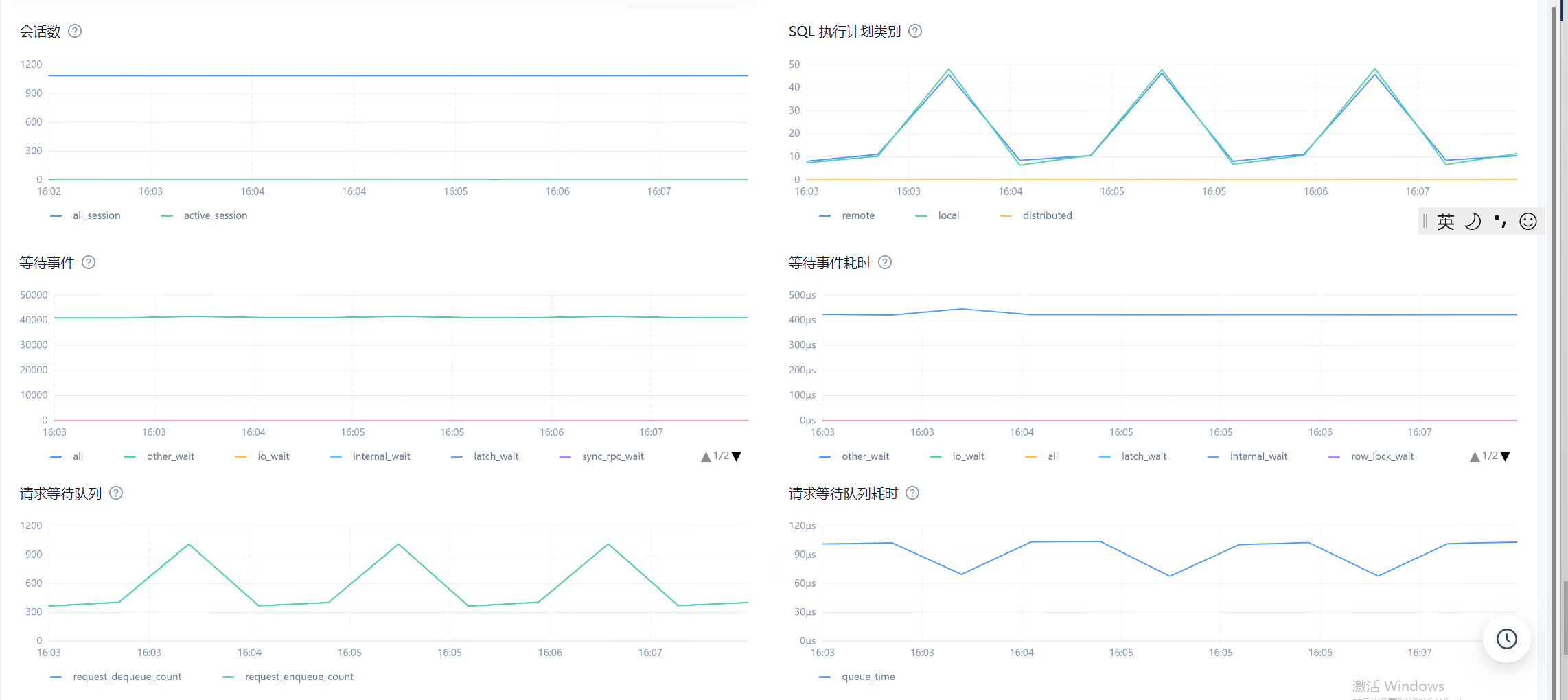
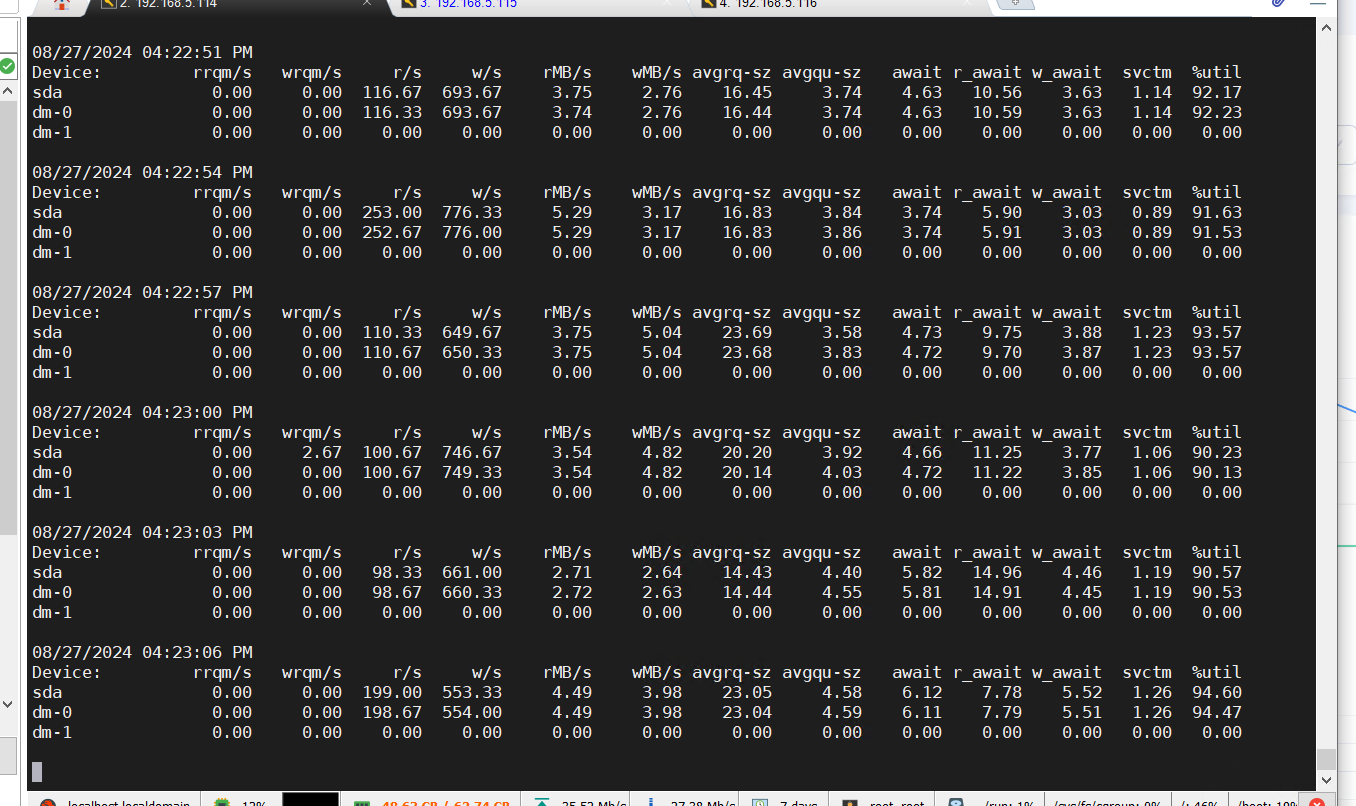
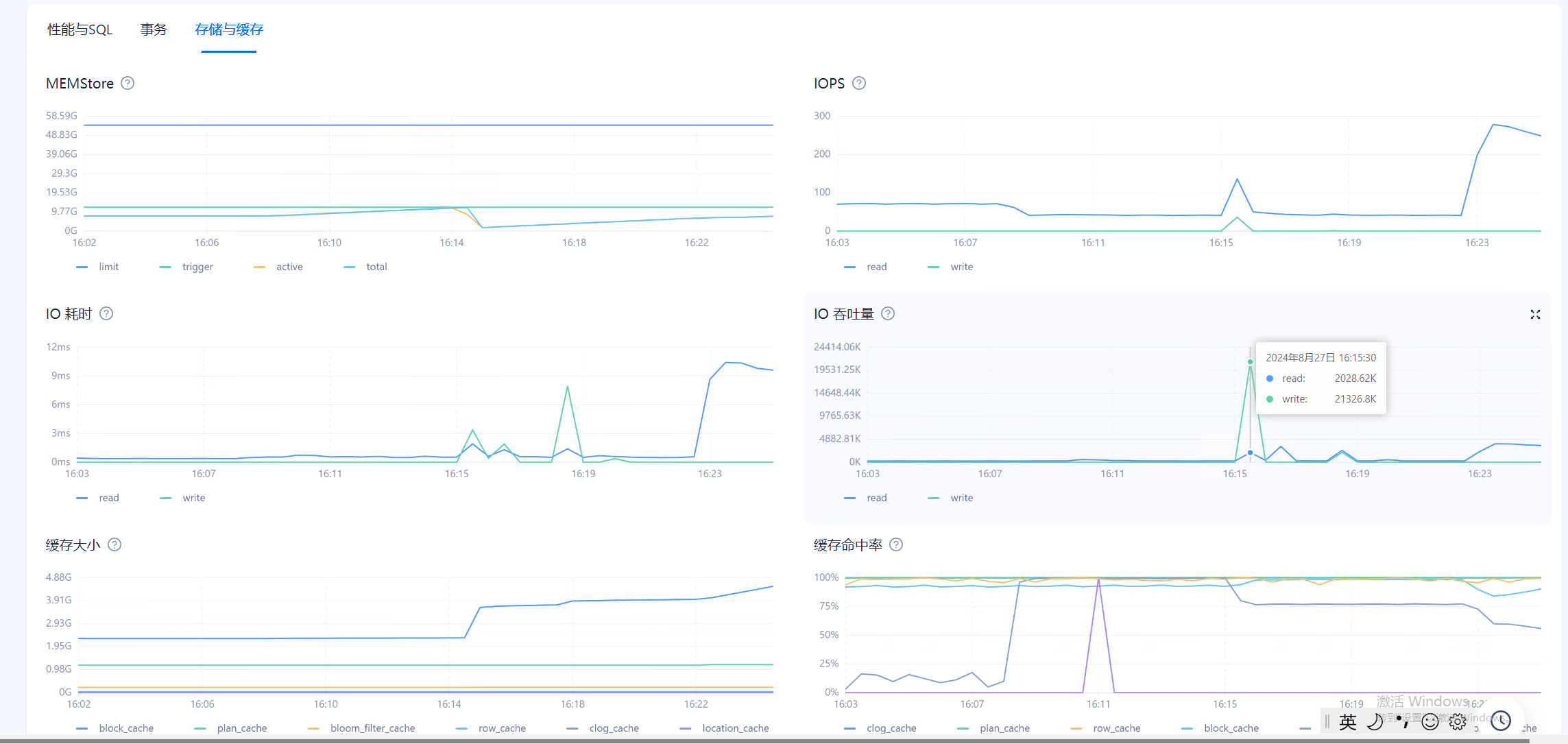
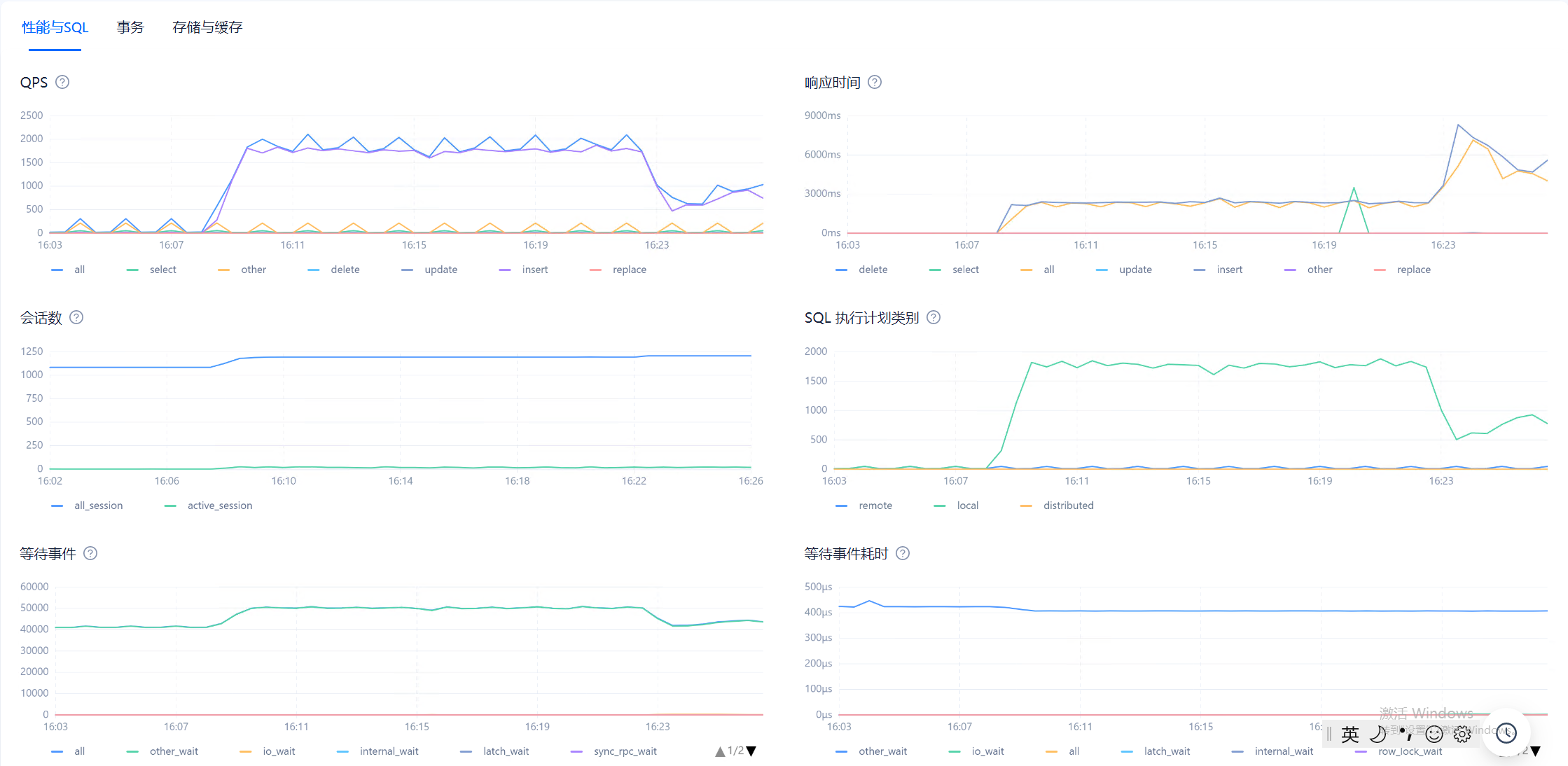
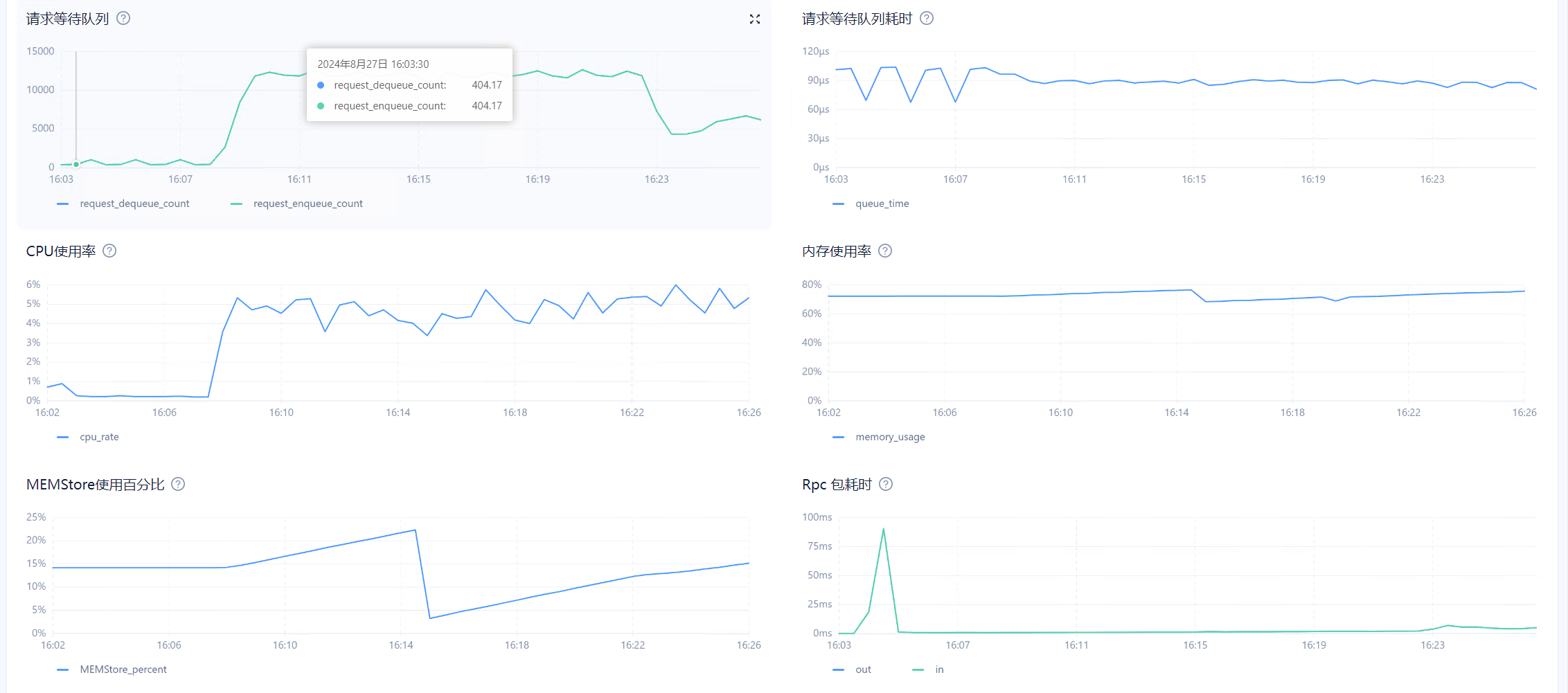
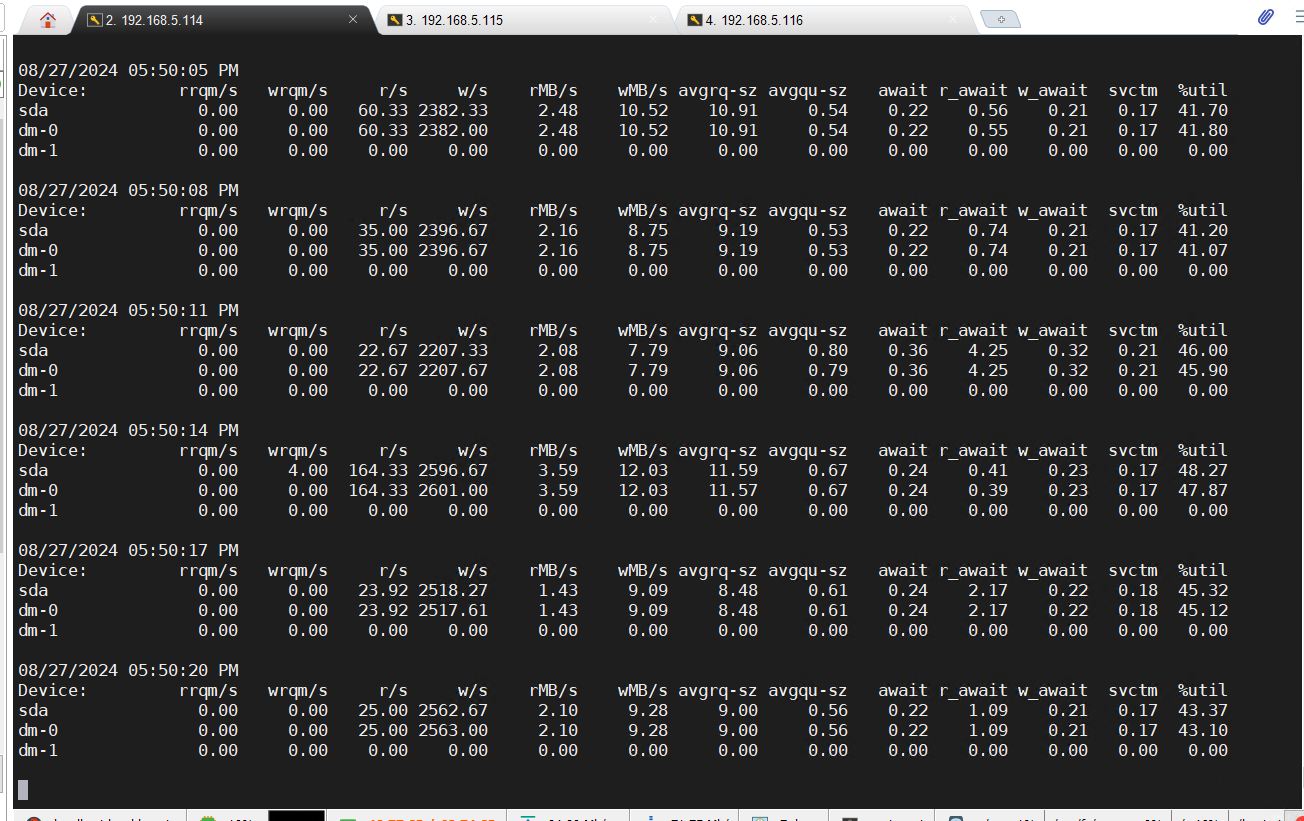
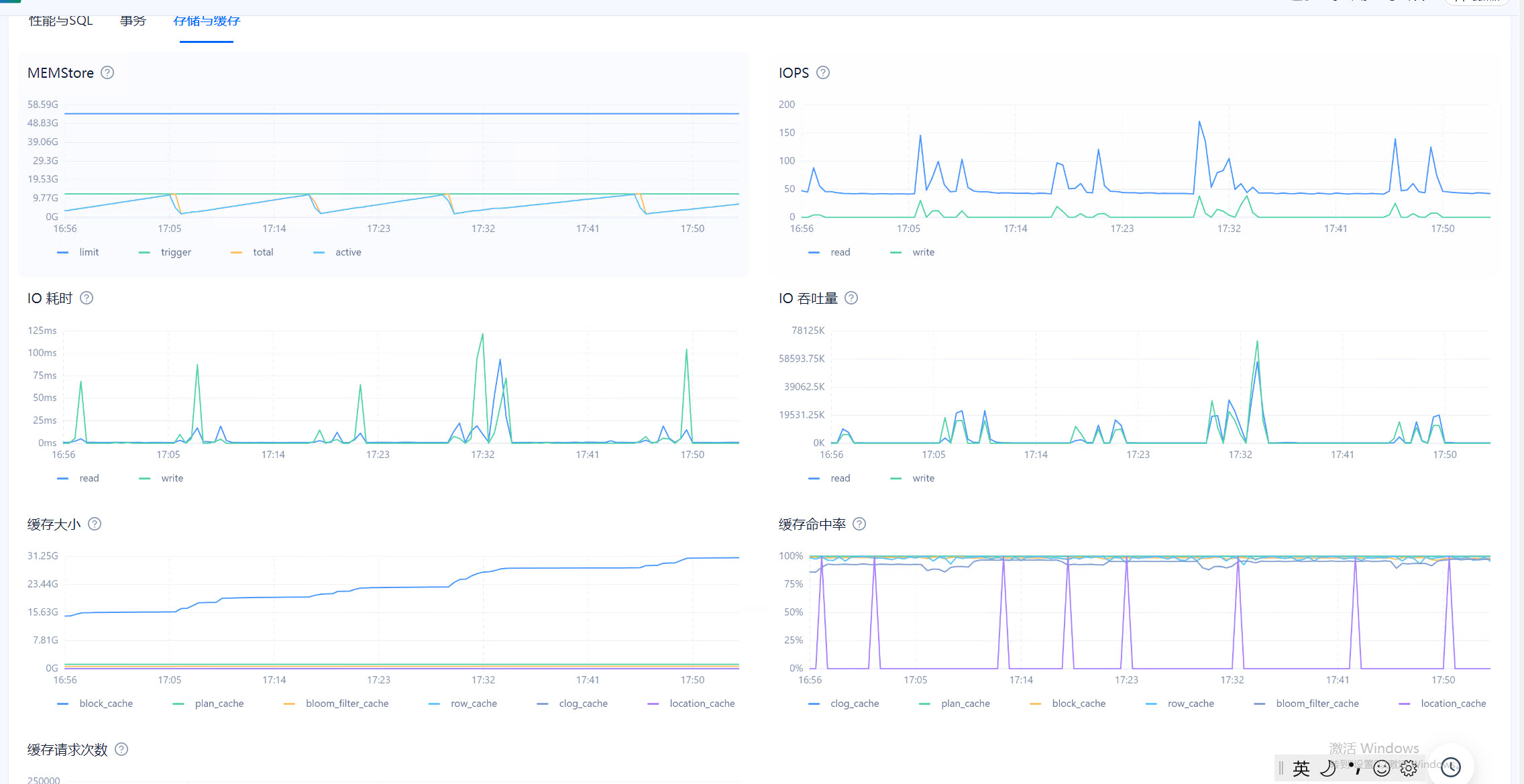
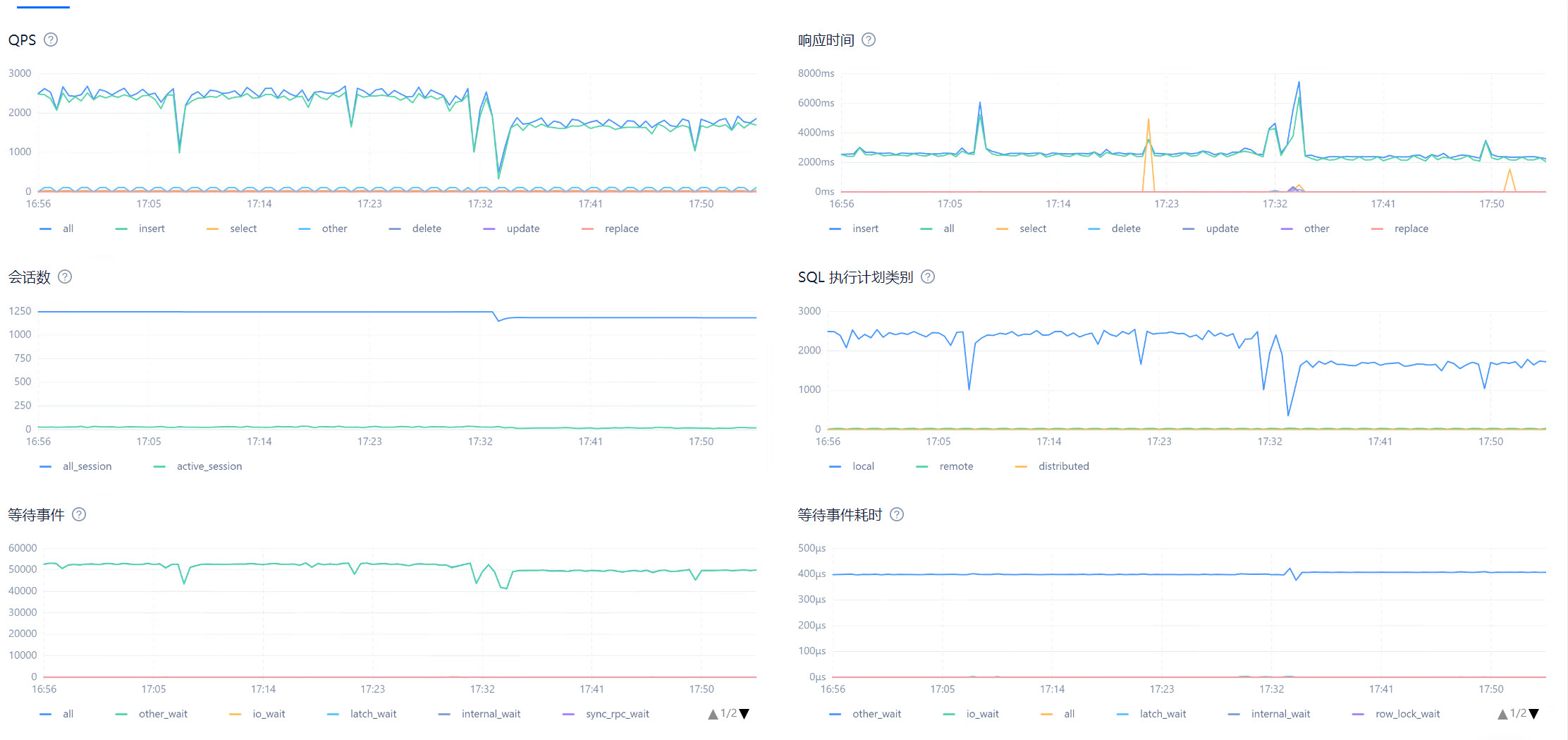
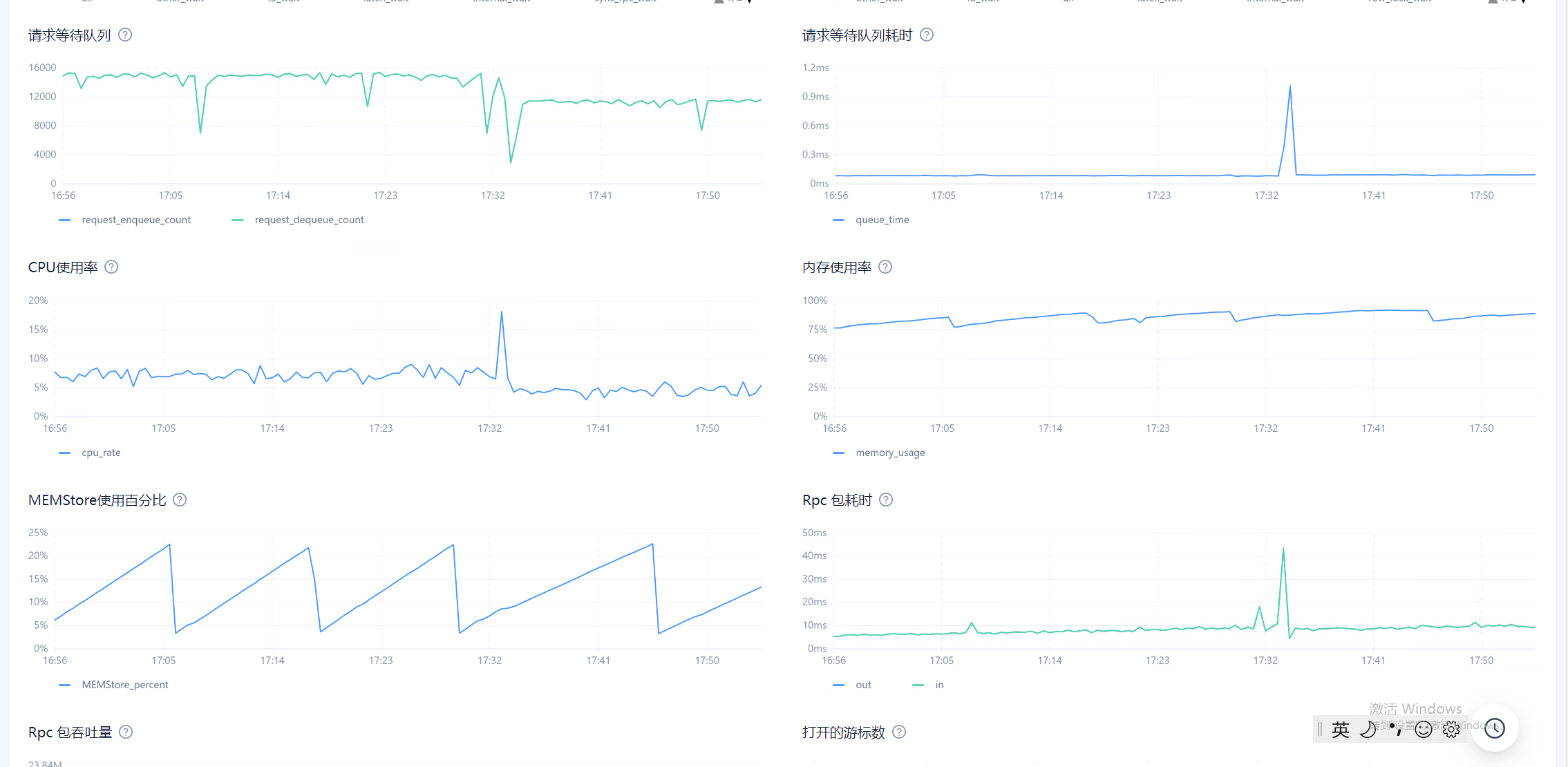
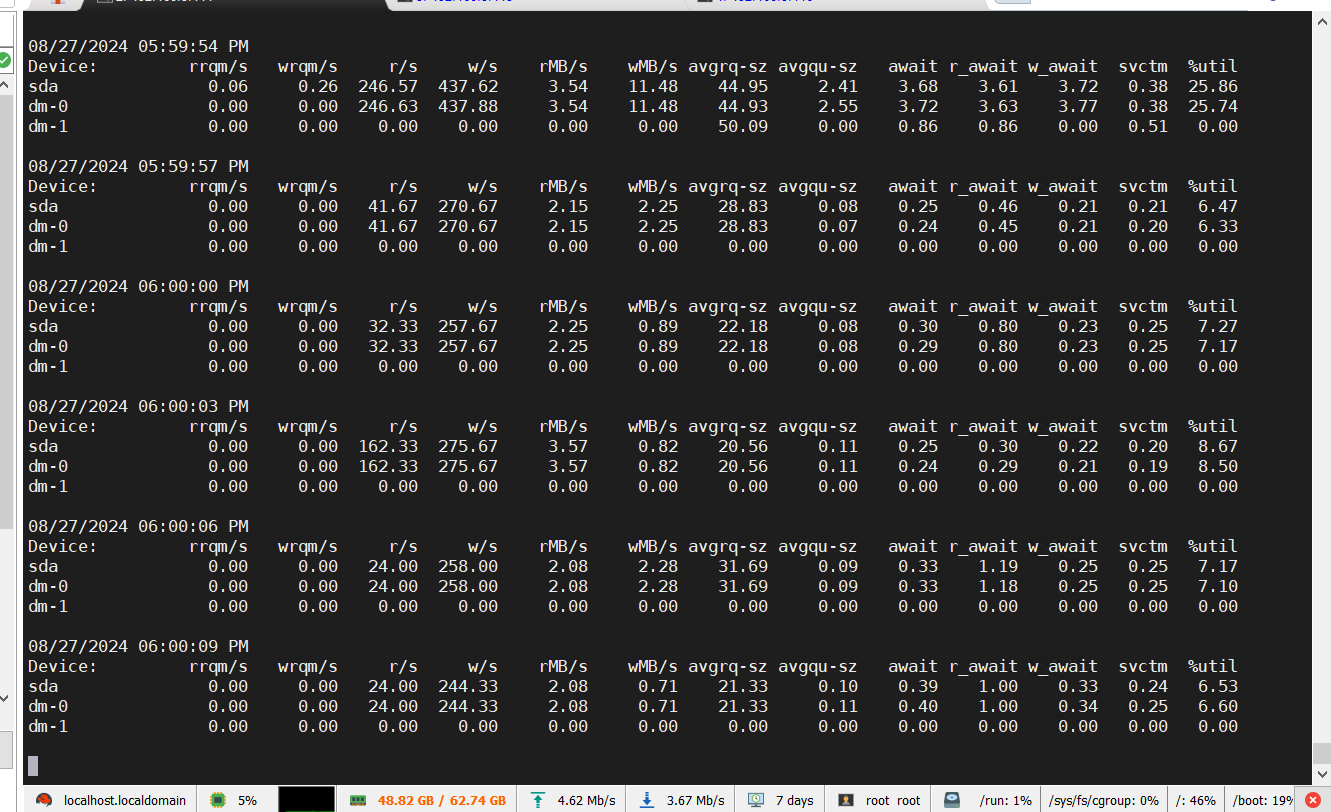
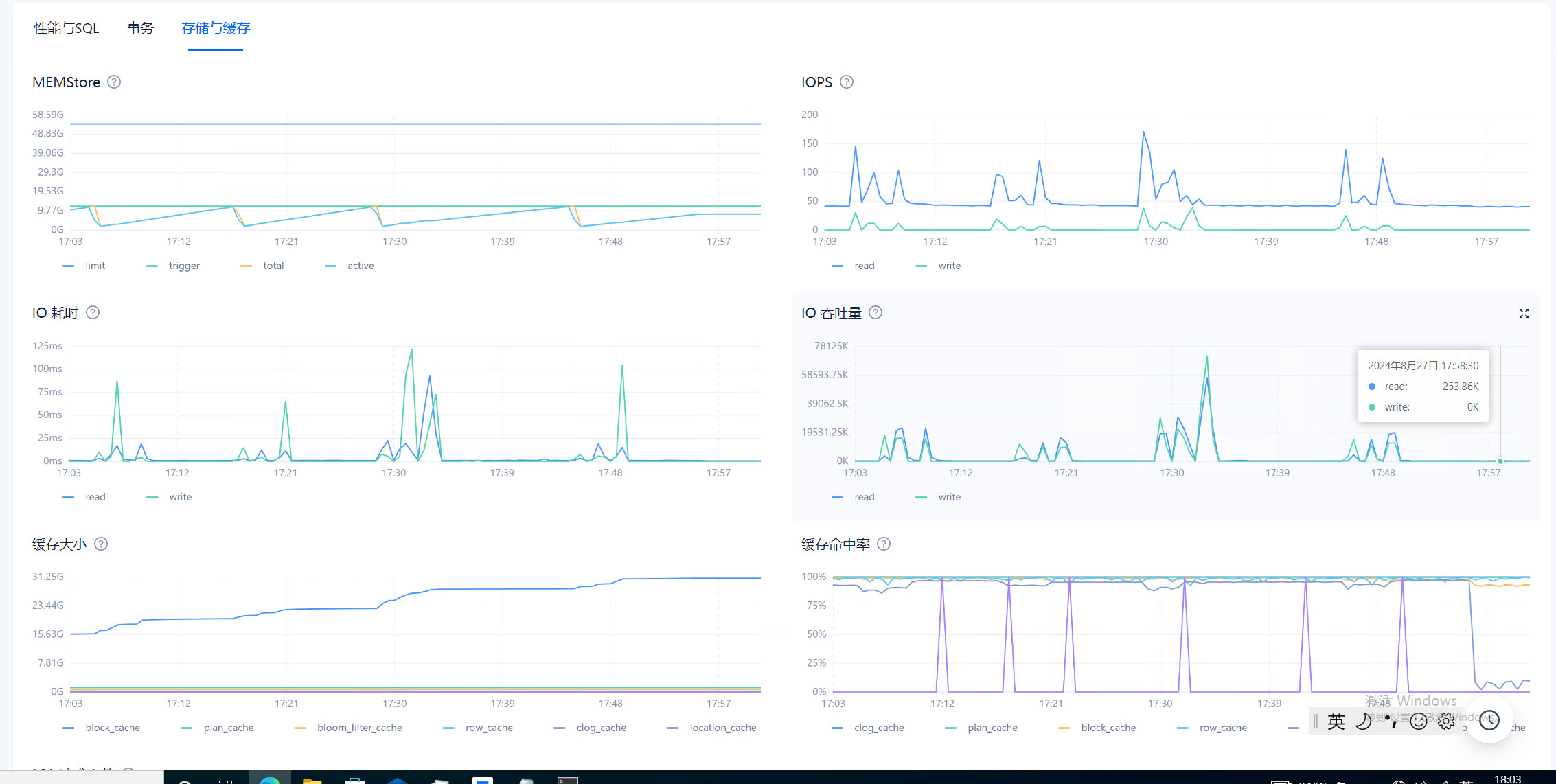
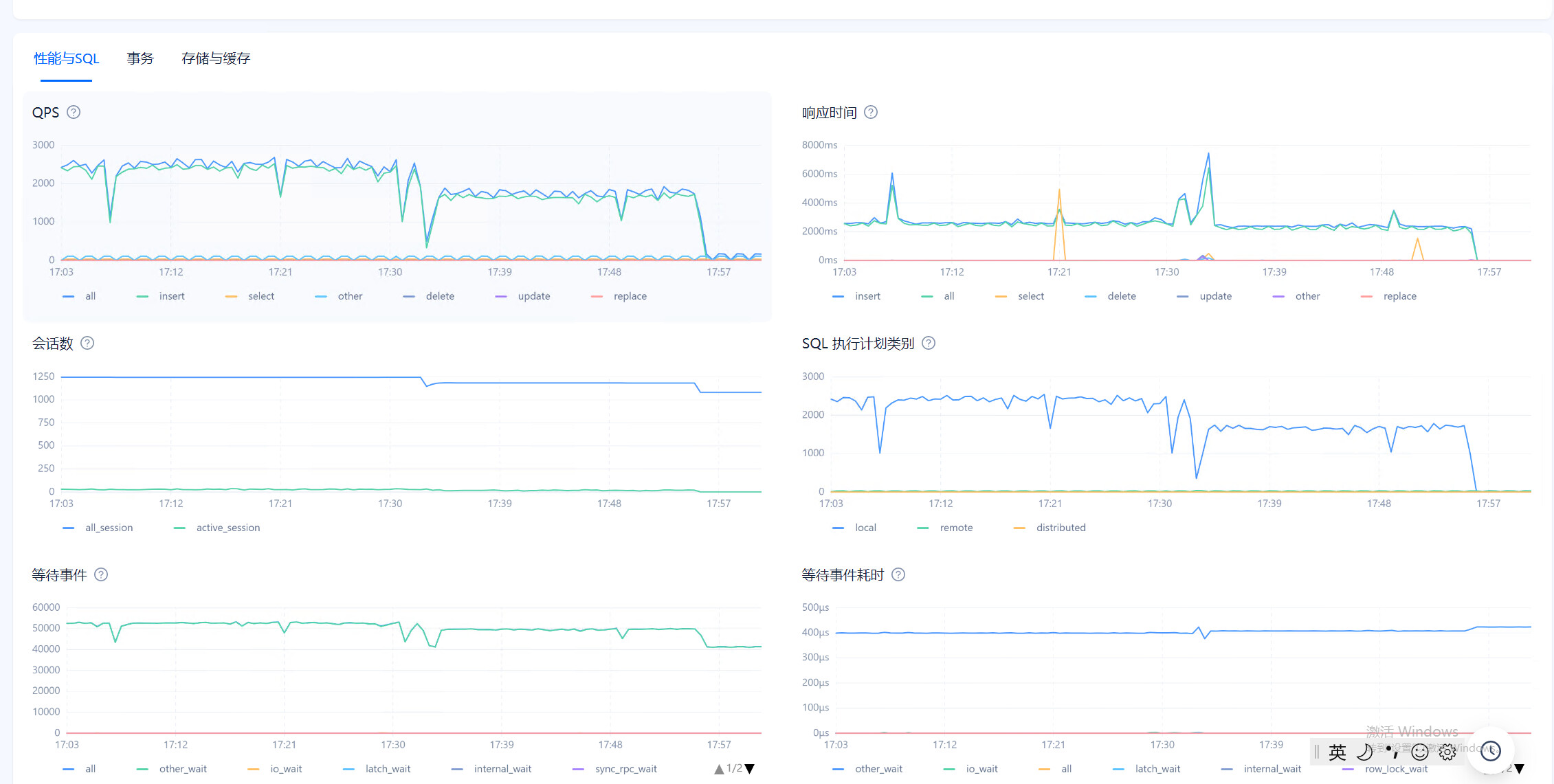
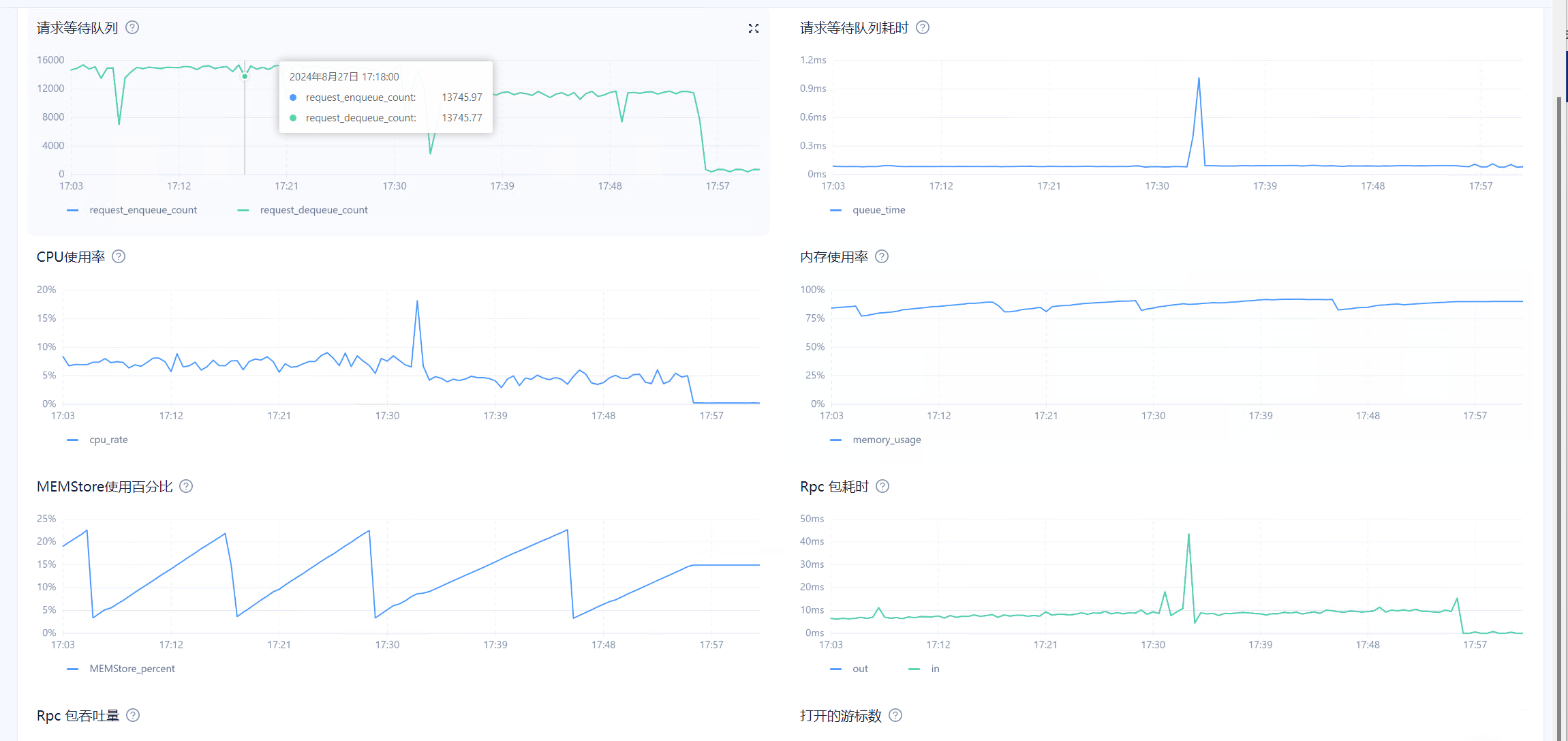
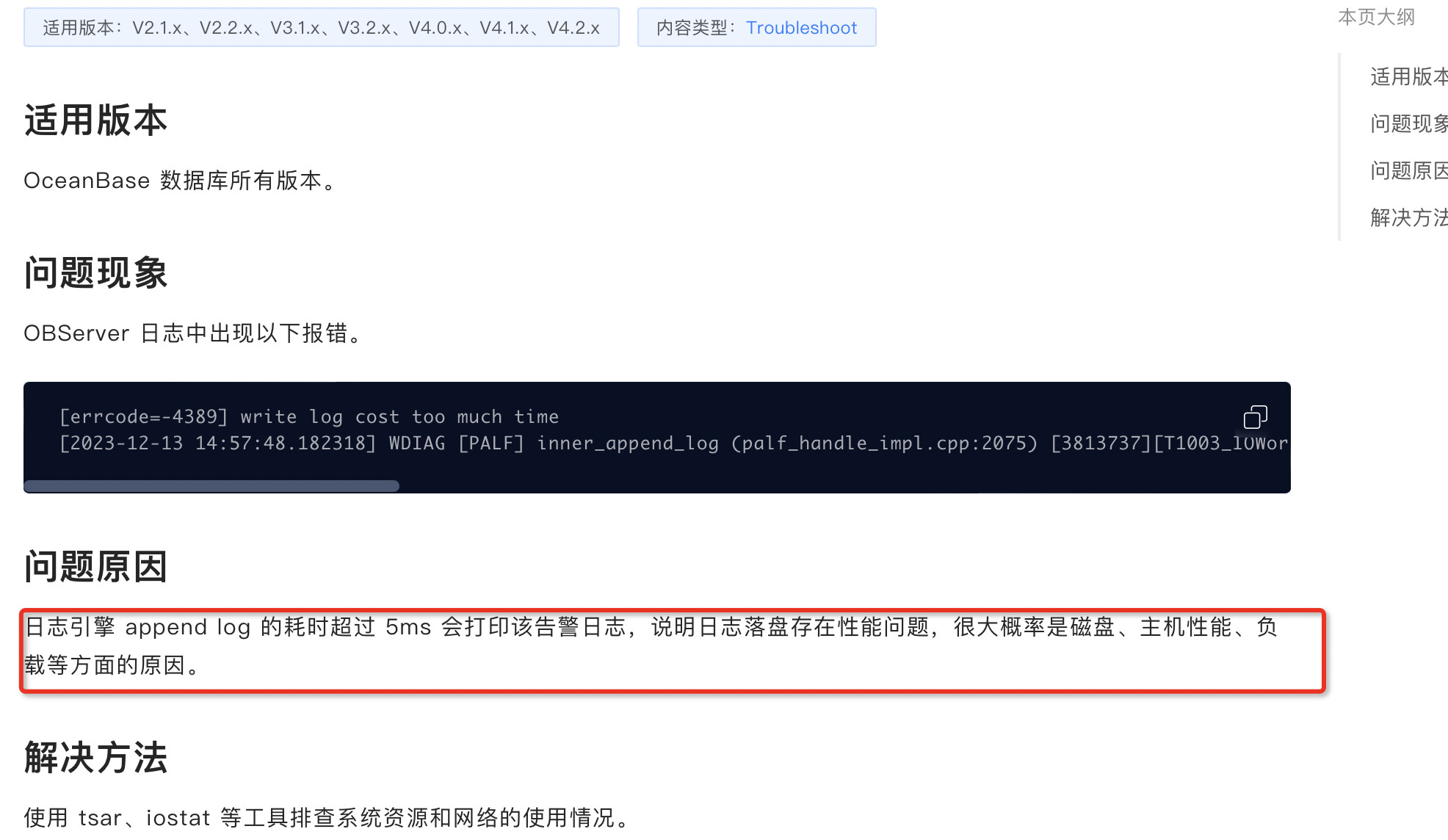
目前在observer.log看到大量 4389的报错,clog日志同步太慢,和IO调度相关,使用的什么类型的磁盘呢?
grep “errcode=-4389” observer.log|more
[2024-08-26 15:54:16.204850] WDIAG [STORAGE.TRANS] test_lock (ob_trans_ctx.cpp:235) [6864][T1003_ApplySrv0][T1003][Y0-0000000000000000-0-0] [lt=30][errcode=-4389] transaction log sync use too much time(log_cb={ObTxBaseLogCb:{log_ts:{val:1724658854714052537, v:0}, lsn:{lsn:34922955004}, submit_ts:1724658854714074}, this:0x7f8e9fb557c8, is_inited_:true, trans_id:{txid:57052414}, ls_id:{id:1}, ctx:0x7f8e9fb52950, tx_data_guard:{tx_data:NULL}, is_callbacked_:false, is_dynamic_:false, mds_range_:{range_array_.count():0, range_array_:[]}, cb_arg_array_:[{log_type:0x1, arg:null}, {log_type:0x40, arg:null}, {log_type:0x100, arg:null}], first_part_scn_:{val:18446744073709551615, v:3}}, log_sync_used_time=1490775, ctx_lock_wait_time=1)
[2024-08-26 15:54:16.204995] WDIAG [STORAGE.TRANS] test_lock (ob_trans_ctx.cpp:235) [6864][T1003_ApplySrv0][T1003][Y0-0000000000000000-0-0] [lt=30][errcode=-4389] transaction log sync use too much time(log_cb={ObTxBaseLogCb:{log_ts:{val:1724658854551892861, v:0}, lsn:{lsn:34922953352}, submit_ts:1724658854551918}, this:0x7f8e9fa66f88, is_inited_:true, trans_id:{txid:57052412}, ls_id:{id:1}, ctx:0x7f8e9fa64110, tx_data_guard:{tx_data:NULL}, is_callbacked_:false, is_dynamic_:false, mds_range_:{range_array_.count():0, range_array_:[]}, cb_arg_array_:[{log_type:0x1, arg:null}, {log_type:0x40, arg:null}, {log_type:0x100, arg:null}], first_part_scn_:{val:18446744073709551615, v:3}}, log_sync_used_time=1653076, ctx_lock_wait_time=0)
[2024-08-26 15:54:16.205816] WDIAG [PALF] sliding_cb (log_sliding_window.cpp:2227) [31061][T1004_L0_G1][T1004][YB42C0A80574-00062054D7FBF8D3-0-0] [lt=6][errcode=-4389] log_task life cost too much time(palf_id=1001, self=“192.168.5.114:2882”, log_id=169917714, log_task={header:{begin_lsn:{lsn:364506380552}, end_lsn:{lsn:364506380674}, log_id:169917714, min_scn:{val:1724658854805515280, v:0}, max_scn:{val:1724658854805515280, v:0}, data_len:66, proposal_id:576, prev_lsn:{lsn:18446744073709551615}, prev_proposal_id:9223372036854775807, committed_end_lsn:{lsn:364506380552}, data_checksum:2222604892, accum_checksum:563024905, is_padding_log:false, is_raw_write:false}, state_map:{val:62}, ref_cnt:0, gen_ts:1724658854952721, freeze_ts:1724658854952725, submit_ts:1724658854952752, flushed_ts:1724658855428015, first_ack_ts:1724658856205785, committed_ts:1724658856205786, gen_to_freeze cost time:4, gen_to_submit cost time:31, submit_to_flush cost time:475263, submit_to_first_ack cost time:1253033, submit_to_commit cost time:1253034}, fs_cb_begin_ts=1724658856205788, log_life_time=1253067)
[2024-08-26 15:54:16.205902] WDIAG [LIB] ~ObTimeGuard (utility.h:855) [6961][T1003_TenantWea][T1003][Y0-0000000000000000-0-0] [lt=43][errcode=-4389] destruct(*this=time guard ‘[WRS] [TENANT_WEAK_READ_SERVICE] tenant_id=1003, thread_timer_task’ cost too much time, used=1492648, time_dist: do_cluster_heartbeat=8, generate_cluster_version=1491765)
[2024-08-26 15:54:16.206296] WDIAG [LIB] ~ObTimeGuard (utility.h:855) [5116][IO_SCHEDULE0][T0][YB42C0A80572-00062054C68BD45B-0-0] [lt=17][errcode=-4389] destruct(*this=time guard ‘LocalDevice’ cost too much time, used=307992, time_dist: LocalDevice_submit=307984)
[2024-08-26 15:54:16.206338] WDIAG [LIB] ~ObTimeGuard (utility.h:855) [5116][IO_SCHEDULE0][T0][YB42C0A80572-00062054C68BD45B-0-0] [lt=32][errcode=-4389] destruct(*this=time guard ‘submit_req’ cost too much time, used=308038, time_dist: prepare_req=3, device_submit=307999)
[2024-08-26 15:54:16.206519] WDIAG [LIB] ~ObTimeGuard (utility.h:855) [5119][IO_SCHEDULE0][T0][YB42C0A80572-00062054C55F1AB7-0-0] [lt=8][errcode=-4389] destruct(*this=time guard ‘LocalDevice’ cost too much time, used=408677, time_dist: LocalDevice_submit=408664)
[2024-08-26 15:54:16.206564] WDIAG [LIB] ~ObTimeGuard (utility.h:855) [5119][IO_SCHEDULE0][T0][YB42C0A80572-00062054C55F1AB7-0-0] [lt=30][errcode=-4389] destruct(*this=time guard ‘submit_req’ cost too much time, used=408720, time_dist: prepare_req=2, device_submit=408684)
[2024-08-26 15:54:16.207060] WDIAG [LIB] ~ObTimeGuard (utility.h:855) [5122][IO_SCHEDULE0][T0][YB42C0A80572-00062054C7387457-0-0] [lt=7][errcode=-4389] destruct(*this=time guard ‘LocalDevice’ cost too much time, used=410718, time_dist: LocalDevice_submit=410707)
[2024-08-26 15:54:16.207125] WDIAG [LIB] ~ObTimeGuard (utility.h:855) [5122][IO_SCHEDULE0][T0][YB42C0A80572-00062054C7387457-0-0] [lt=51][errcode=-4389] destruct(*this=time guard ‘submit_req’ cost too much time, used=410782, time_dist: prepare_req=1, device_submit=410725)
[2024-08-26 15:54:16.329830] WDIAG [LIB] ~ObTimeGuard (utility.h:855) [5121][IO_SCHEDULE0][T0][YB42C0A80572-00062054BE285F26-0-0] [lt=18][errcode=-4389] destruct(*this=time guard ‘LocalDevice’ cost too much time, used=535379, time_dist: LocalDevice_submit=535363)
[2024-08-26 15:54:16.329931] WDIAG [LIB] ~ObTimeGuard (utility.h:855) [5121][IO_SCHEDULE0][T0][YB42C0A80572-00062054BE285F26-0-0] [lt=52][errcode=-4389] destruct(*this=time guard ‘submit_req’ cost too much time, used=535479, time_dist: prepare_req=3, device_submit=535418)
[2024-08-26 15:54:16.330474] WDIAG [LIB] ~ObTimeGuard (utility.h:855) [5113][IO_SCHEDULE0][T0][YB42C0A80572-00062054DEC88B21-0-0] [lt=5][errcode=-4389] destruct(*this=time guard ‘LocalDevice’ cost too much time, used=534758, time_dist: LocalDevice_submit=534746)
[2024-08-26 15:54:16.330535] WDIAG [LIB] ~ObTimeGuard (utility.h:855) [5113][IO_SCHEDULE0][T0][YB42C0A80572-00062054DEC88B21-0-0] [lt=30][errcode=-4389] destruct(*this=time guard ‘submit_req’ cost too much time, used=534817, time_dist: prepare_req=2, device_submit=534780)
[2024-08-26 15:54:16.330884] WDIAG [LIB] ~ObTimeGuard (utility.h:855) [5115][IO_SCHEDULE0][T0][Y0-0000000000000000-0-0] [lt=7][errcode=-4389] destruct(*this=time guard ‘LocalDevice’ cost too much time, used=125484, time_dist: LocalDevice_submit=125472)
[2024-08-26 15:54:16.330948] WDIAG [LIB] ~ObTimeGuard (utility.h:855) [5115][IO_SCHEDULE0][T0][Y0-0000000000000000-0-0] [lt=29][errcode=-4389] destruct(*this=time guard ‘submit_req’ cost too much time, used=125549, time_dist: prepare_req=4, device_submit=125511)
[2024-08-26 15:54:16.334500] WDIAG [PALF] inner_append_log (palf_handle_impl.cpp:2123) [6236][T1002_IOWorker][T1002][Y0-0000000000000000-0-0] [lt=12][errcode=-4389] write log cost too much time(ret=-4389, this={palf_id:1002, self:“192.168.5.114:2882”, has_set_deleted:false}, lsn_array=[{lsn:50271464260}], scn_array=[{val:1724658854551918415, v:0}], curr_size=122, accum_size=1586, time_cost=679951)
[2024-08-26 15:54:16.334498] WDIAG [PALF] inner_append_log (palf_handle_impl.cpp:2123) [7105][T1004_IOWorker][T1004][Y0-0000000000000000-0-0] [lt=16][errcode=-4389] write log cost too much time(ret=-4389, this={palf_id:1003, self:“192.168.5.114:2882”, has_set_deleted:false}, lsn_array=[{lsn:422478926881}, {lsn:422478927125}, {lsn:422478927285}, {lsn:422478927406}, {lsn:422478927528}], scn_array=[{val:1724658854725622893, v:0}, {val:1724658854725657199, v:0}, {val:1724658854725657200, v:0}, {val:1724658854725657201, v:0}, {val:1724658854725657202, v:0}], curr_size=1294, accum_size=23019, time_cost=681254)
[2024-08-26 15:54:16.334623] WDIAG [PALF] sliding_cb (log_sliding_window.cpp:2227) [6233][T1002_LogIOCb0][T1002][Y0-0000000000000000-0-0] [lt=8][errcode=-4389] log_task life cost too much time(palf_id=1002, self=“192.168.5.114:2882”, log_id=45783731, log_task={header:{begin_lsn:{lsn:50271464260}, end_lsn:{lsn:50271464382}, log_id:45783731, min_scn:{val:1724658854551918415, v:0}, max_scn:{val:1724658854551918415, v:0}, data_len:66, proposal_id:555, prev_lsn:{lsn:50271464138}, prev_proposal_id:555, committed_end_lsn:{lsn:50271464260}, data_checksum:1715074492, accum_checksum:2817635375, is_padding_log:false, is_raw_write:false}, state_map:{val:58}, ref_cnt:0, gen_ts:1724658855654407, freeze_ts:1724658855654408, submit_ts:1724658855654411, flushed_ts:1724658856334561, first_ack_ts:-1, committed_ts:1724658856204438, gen_to_freeze cost time:1, gen_to_submit cost time:4, submit_to_flush cost time:680150, submit_to_first_ack cost time:0, submit_to_commit cost time:550027}, fs_cb_begin_ts=1724658856334600, log_life_time=680193)