

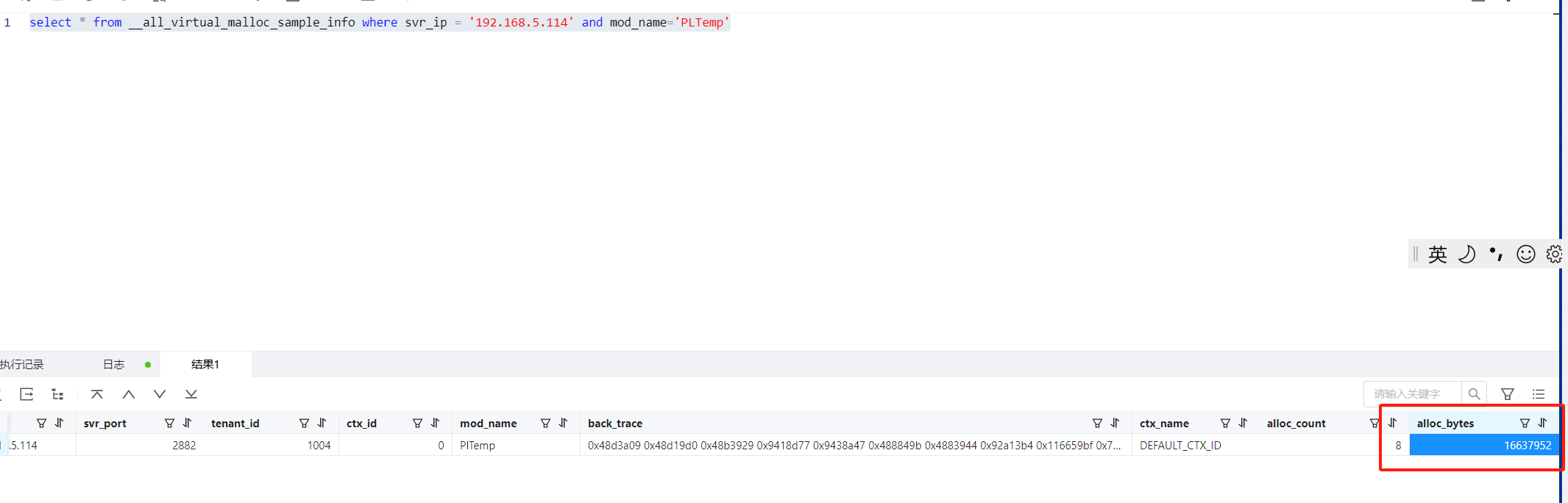
现在的确实没有那么大了,不过也没有出现内存不足的报错,我让同事造数看下能不能复现
这里应该是小写“L”,PlTemp,你再查下看看
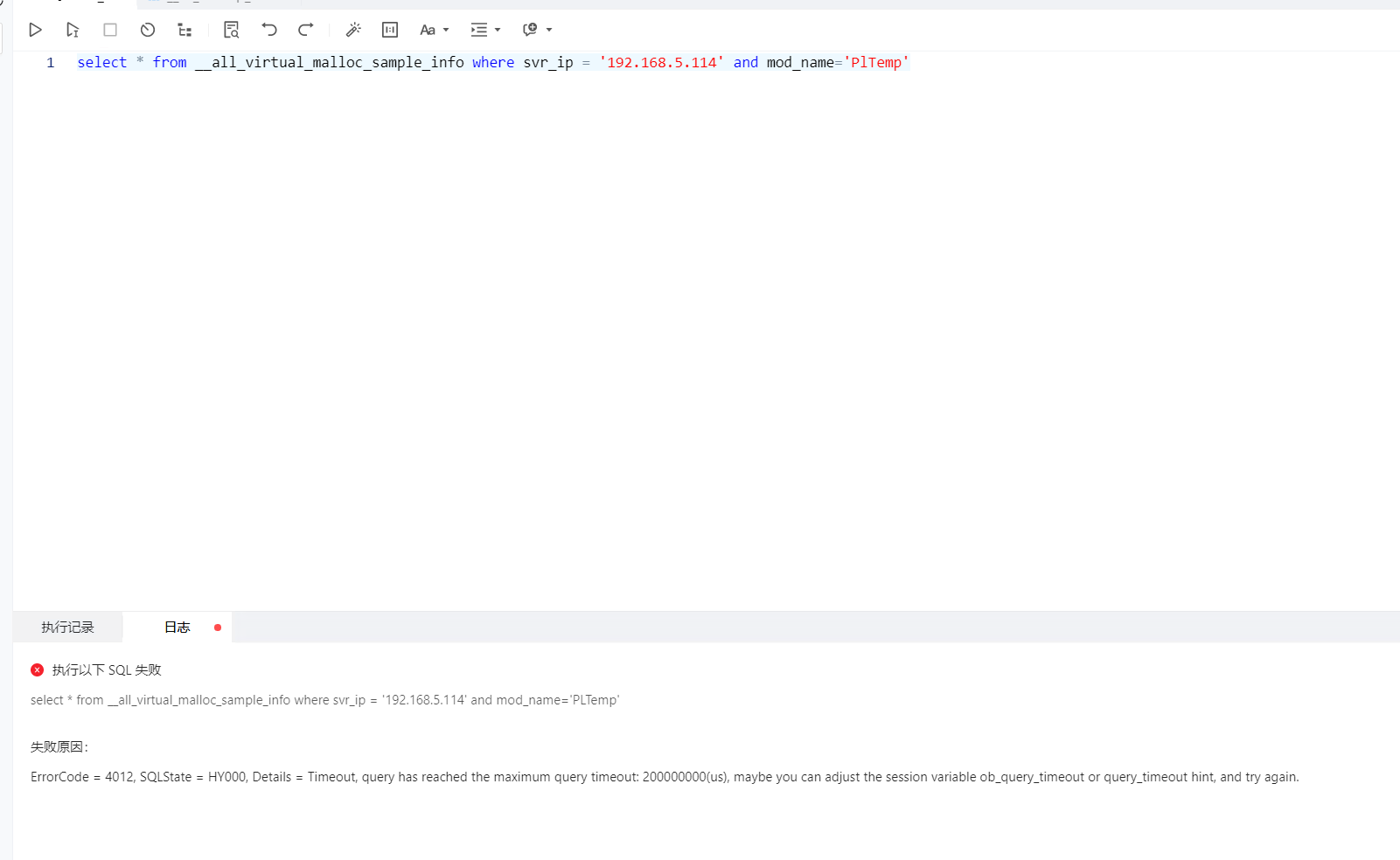
目前看起来可能PlTemp模块发生了内存泄漏,需要获取下准确的堆栈信息进行修复,
所以复现后发下上面两个步骤的结果,
另外你是使用存储过程方式造数的吗?
不是,只是简单的insert拼接
收到你的报告,从报告看这个时段没有严重的问题,你可以发下21号 以及最新的observer.log吗?
或者参考如下命令,收集下问题时段前后30分钟的报错
obdiag gather scene run --scene=observer.memory --from “2022-06-30 16:25:00” --to “2022-06-30 18:30:00”
https://www.oceanbase.com/docs/common-obdiag-cn-1000000001214431

这次修改了sys的cpu数改成8,应用租户改成15了,重启后又造数了,我查了一下那个表,发现没有PlTemp模块了,另外这次启动ocp-express启动报错,我就没起,请问下这个PlTemp模块是什么情况下会有
PlTemp内存泄露触发场景比较复杂,需要具体分析,
“这次修改了sys的cpu数改成8,应用租户改成15了”,用户租户的cpu由20调整为了15,
sys租户原来cpu是多少呢?之前出现这个问题时cpu使用率高吗?
另外可以发下21号的observer.log吗?
sys原本的cpu是2,出现问题时没监控cpu,21号的observe.log我没找到,log里面券是0823的日志,请问还有其他需要的文件吗,我一起申请,因为在内网,每次拿都需要审批
提供下楼上说的那个文件吧,如果后续再次出现问题了再提供下相应日志
21号的observer.log我找不到在哪里,麻烦告知一下路径
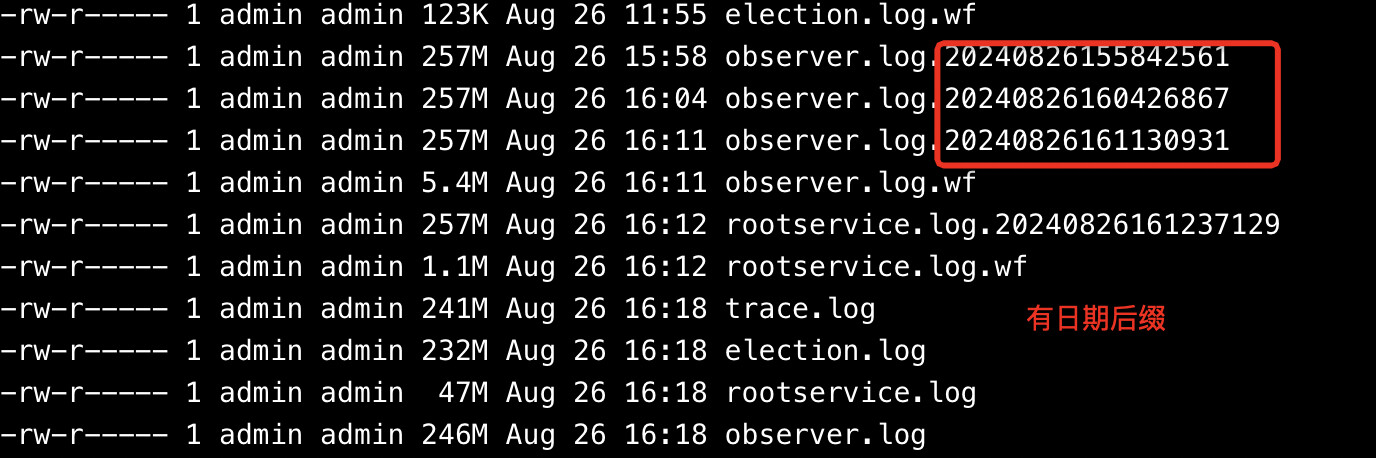
我查了下配置,配置开启了日志清理,最多存4个文件,21号的observer.log日志已经不存在了
如果能复现或者后续再次出现这个问题 再提供下相应日志和堆栈信息,大概率是PlTemp模块内存泄露,要上升到开发分析,需要足够的日志
能否到这个帖子帮忙跟进下,后续如果还有复现出内存问题,我再发到这个帖子上
好的