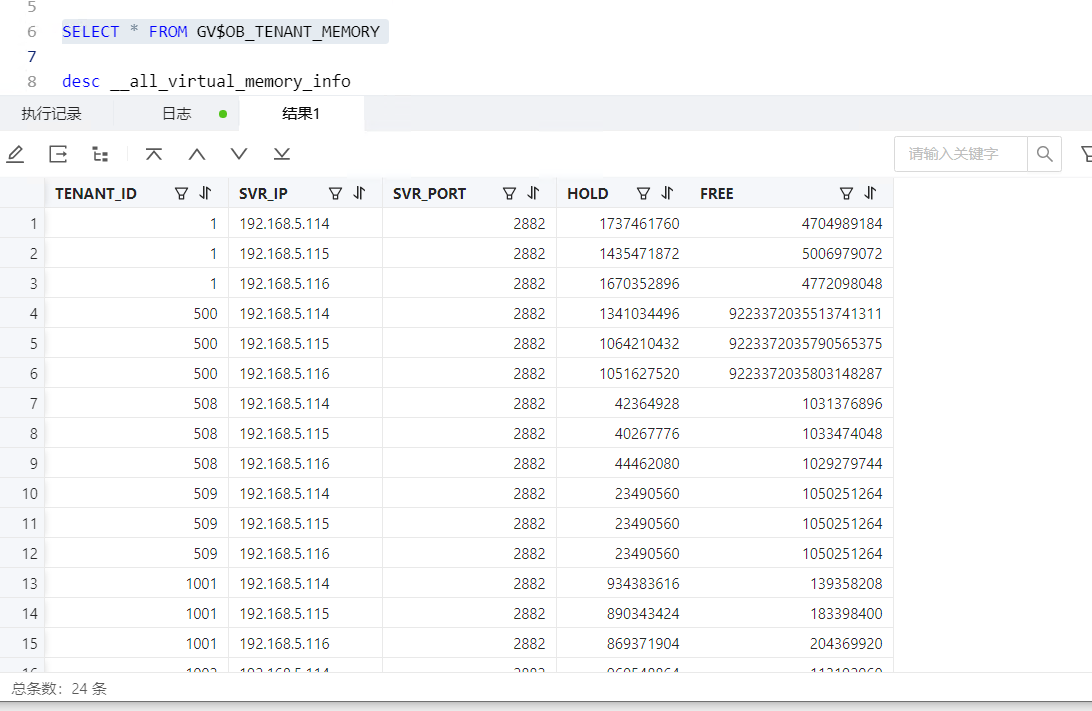
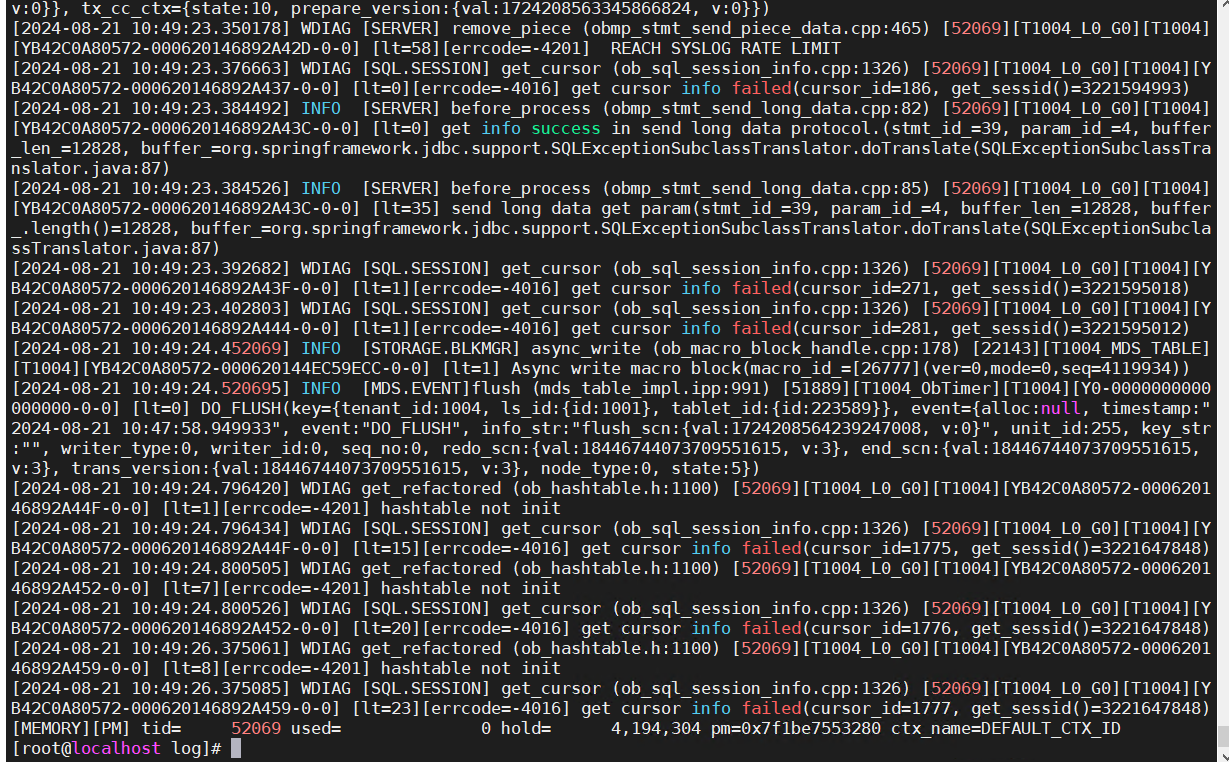
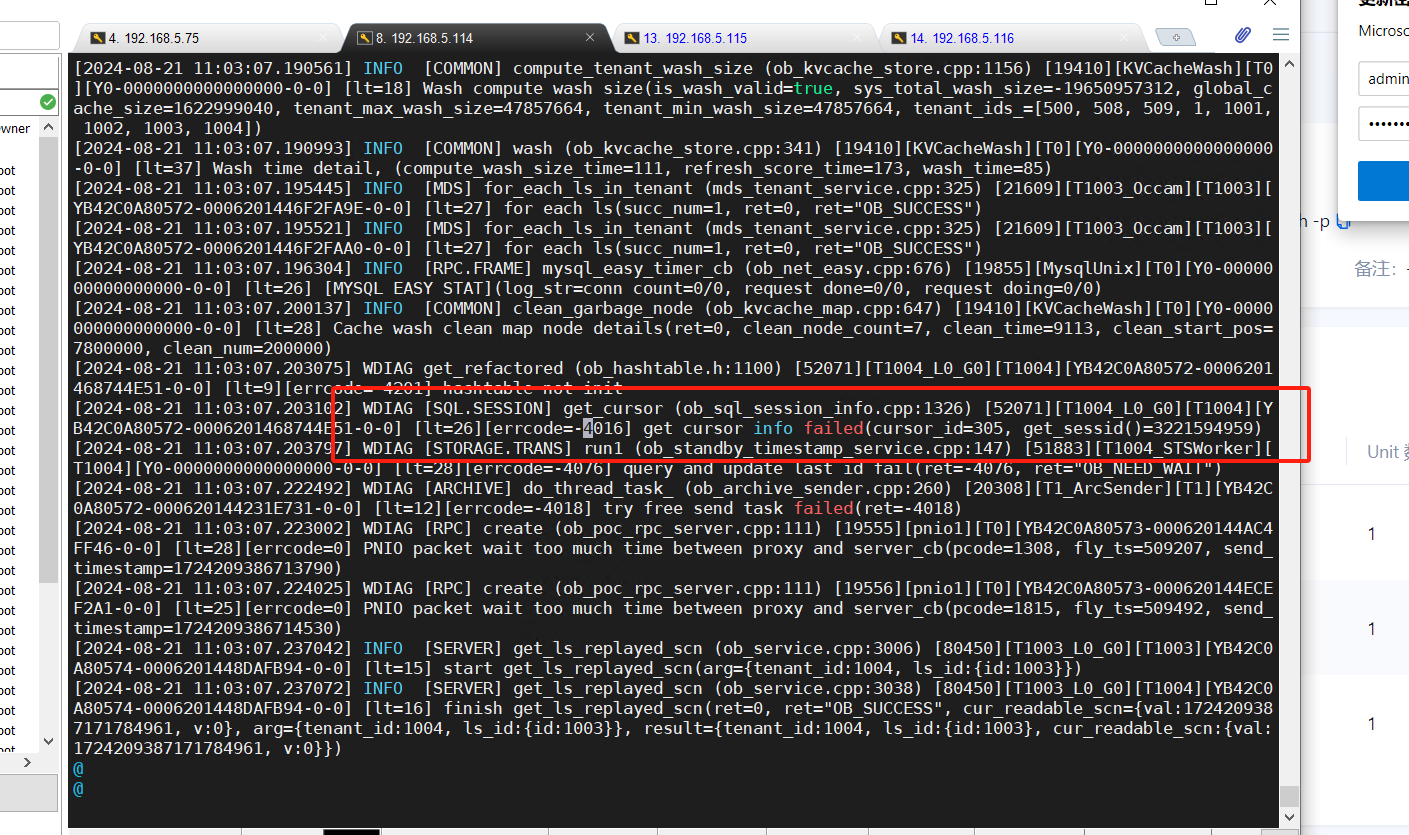
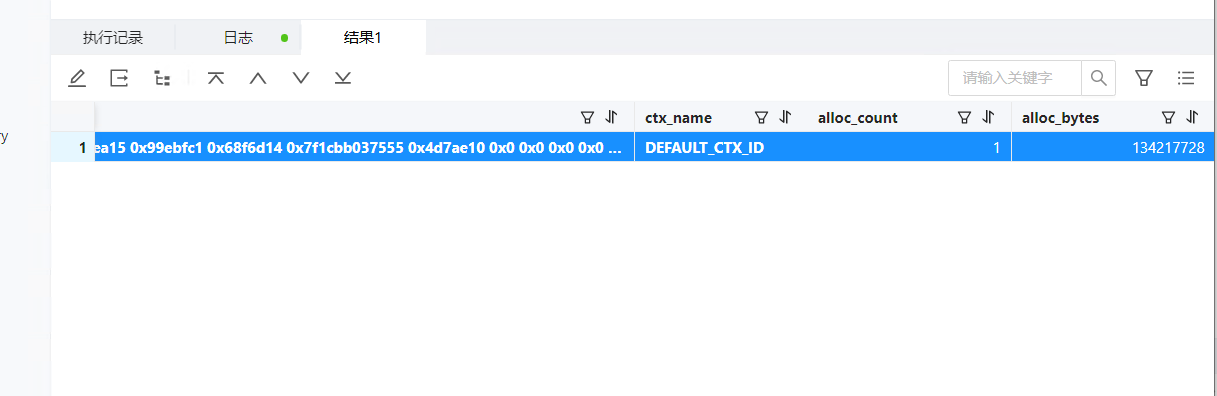
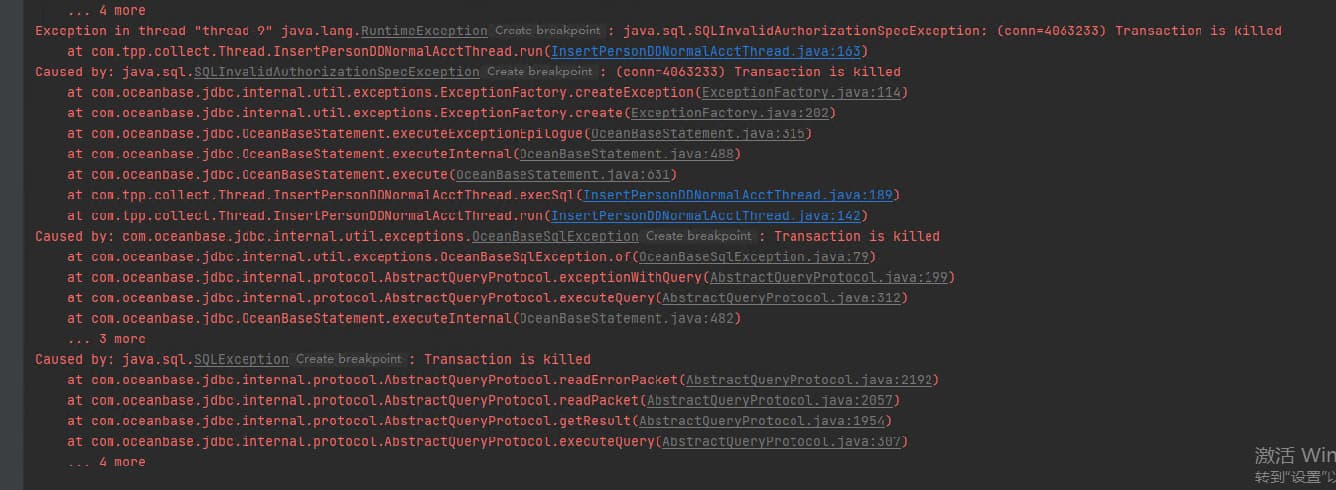
4013内存排查
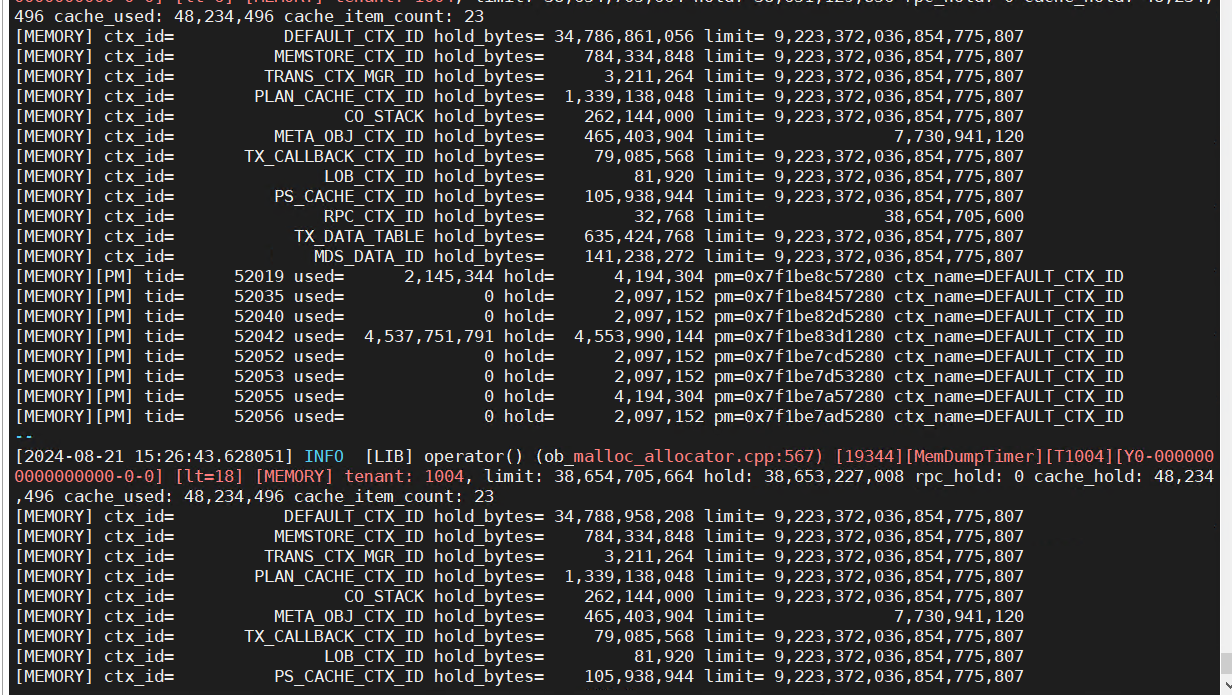
查看模块内存: select * from gv$ob_memory where tenant_id=500 order by used desc limit 20;
–上面查询的svr_ip和mod_name
根据ip和模块查看模块信息:select * from __all_virtual_malloc_sample_info where svr_ip=‘10.10.10.147’ and mod_name=‘glibc_malloc’ order by alloc_bytes desc limit;
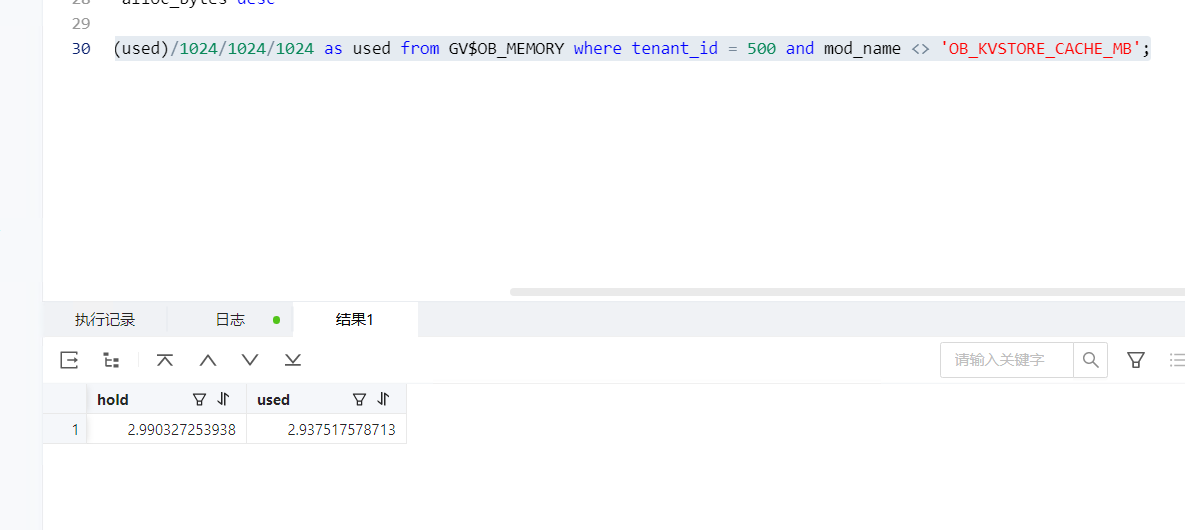
500租户内存使用
select /* MONITOR_AGENT */ sum(hold)/1024/1024/1024 as hold, sum(used)/1024/1024/1024 as used from GV$OB_MEMORY where tenant_id = 500 and mod_name <> ‘OB_KVSTORE_CACHE_MB’;
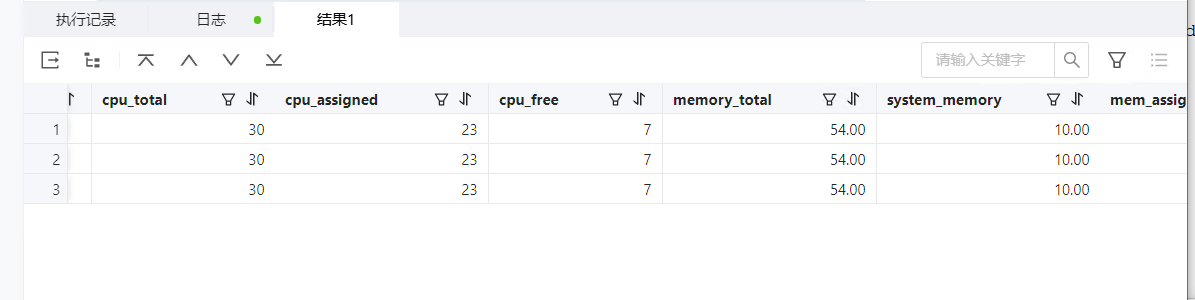
集群 server 级资源分配情况
select zone,concat(SVR_IP,’:’,SVR_PORT) observer,
cpu_capacity_max cpu_total,cpu_assigned_max cpu_assigned,
cpu_capacity-cpu_assigned_max as cpu_free,
round(memory_limit/1024/1024/1024,2) as memory_total,
round((memory_limit-mem_capacity)/1024/1024/1024,2) as system_memory,
round(mem_assigned/1024/1024/1024,2) as mem_assigned,
round((mem_capacity-mem_assigned)/1024/1024/1024,2) as memory_free,
round(log_disk_capacity/1024/1024/1024,2) as log_disk_capacity,
round(log_disk_assigned/1024/1024/1024,2) as log_disk_assigned,
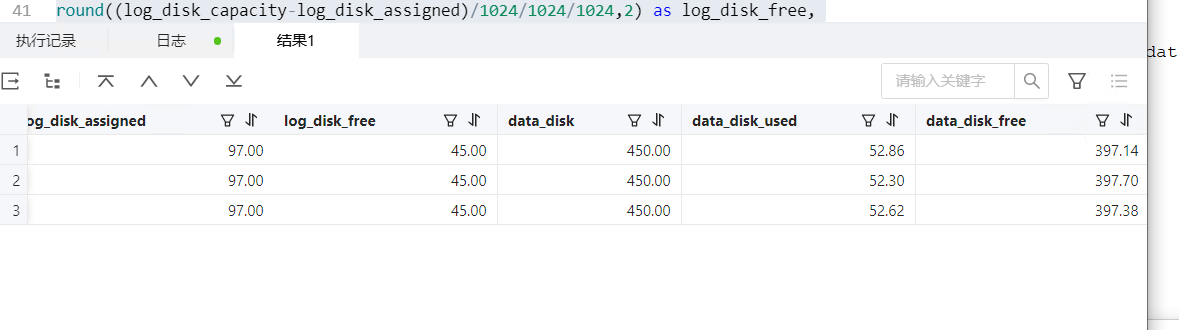
round((log_disk_capacity-log_disk_assigned)/1024/1024/1024,2) as log_disk_free,
round((data_disk_capacity/1024/1024/1024),2) as data_disk,
round((data_disk_in_use/1024/1024/1024),2) as data_disk_used,
round((data_disk_capacity-data_disk_in_use)/1024/1024/1024,2) as data_disk_free
from oceanbase.gv$ob_servers;
查看集群 CPU、内存、磁盘参数配置信息
show parameters where name in (‘memory_limit’,‘memory_limit_percentage’,‘system_memory’,‘log_disk_size’,‘log_disk_percentage’,‘datafile_size’,‘datafile_disk_percentage’);