【 使用环境 】生产环境Obdiag obdiag_check_report_observer_2024-08-14-19-31-04.zip (1.7 KB)
【复现路径】问题出现前后相关操作
【SOP系列 22 】——故障诊断第一步(自助诊断和诊断信息收集)
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手 ] 即可召唤小助手,欢迎试用!
1 个赞
论坛小助手:
在执行truncate操作时是否有其他类型的SQL操作正在运行
能否提供更多关于THisPosition表的数据量信息例如每张表大概有多少条记录
您提到有的客户很快有的客户很慢这里的客户是指不同的租户还是指同一租户下不同的实例
您能否提供执行truncate操作的具体SQL语句
1)无其它类型的sql在操纵,因为所有sql任务都是顺序执行的
1 个赞
shiyh
2024 年8 月 14 日 20:41
#6
针对你这个truncate分区慢的问题:
需要弄清楚这15min都花在哪些地方了?可以尝试用show trace找找答案,SQL Trace能够交互式的提供上一次执行的SQL请求执行过程信息及各阶段的耗时。 找到问题的原因,才好解决问题。
步骤:
故障重现,也即执行truncate partition操作。
运行show trace; 命令
2 个赞
1)CPU占用高达 150%左右 mem占用在15%左右
1 个赞
论坛小助手
2024 年8 月 14 日 20:45
#8
根据您提供的信息,我们可以尝试分析一下问题的原因:
CPU占用率高 :您提到在执行TRUNCATE操作时,CPU占用率高达150%左右,这表明在执行TRUNCATE操作时,系统确实处于较高的负载状态。需要注意的是,OceanBase的多核并行处理能力可能会导致CPU占用率超过100%,但这并不一定意味着存在问题。不过,如此高的CPU占用率可能会影响TRUNCATE操作的性能。
内存占用低 :您提到内存占用仅为15%左右,这表明内存资源相对充足,并不太可能是导致TRUNCATE操作耗时的主要原因。
网络和磁盘I/O正常 :您提到没有观察到网络延迟或磁盘I/O方面的问题,这意味着网络和磁盘I/O不太可能是导致问题的原因。
不同租户间的差异 :您提到不同租户间在操作上没有区别,但处理速度却有明显差异。这可能意味着某些硬件配置或系统设置上的差异影响了TRUNCATE操作的性能。
日志信息 :您询问如何提供日志。通常可以通过obdiag工具来收集日志信息。您可以使用obdiag collect命令来收集相关日志,然后使用obdiag upload命令将这些日志上传至OceanBase的支持团队进行进一步分析。
检查系统配置 :确保您的系统配置(如resource_hard_limit等)适合您的工作负载。例如,您提到的CPU配置为26C,最低为3C,这表明您已经预留了一定的资源余量。但是,如果resource_hard_limit设置不当,可能会影响到资源的分配。
查看日志 :通过obdiag工具收集并上传日志,以便进一步分析。特别是关注TRUNCATE操作期间的系统日志和错误日志,看是否存在异常信息。
性能监控 :持续监控系统性能指标,包括CPU、内存、磁盘I/O等,以确定是否有瓶颈存在。
联系支持团队 :如果问题仍然无法解决,建议联系OceanBase的技术支持团队,他们可以提供更深入的帮助和技术支持。
综上所述,尽管目前的信息不足以完全解决问题,但上述建议可以帮助您进一步排查问题。如果您能够提供更多的日志信息,我们将能够更好地帮助您定位问题。
具体信息可参考以下文档:
(小助手的答复已结束,如未能解决您的问题,请继续提问并等待其他同学的回复,谢谢!)
2 个赞
发一下 sys租户的资源规格。
看看有没有改善?
2 个赞
Giant
2024 年8 月 15 日 15:25
#12
再说一个关于truncate 表较慢的案例
环境:polardb-x 1.0
我还是怀疑您的空分区表太多导致
truncate分区 后,还有创建一个新的空分区,还需要维护分区表的逻辑,可以尝试drop操作看看
3 个赞
1)我们的历史数据都是需要保存的,都是客户的明细,不可以删除
疑问:
1 个赞
将尝试帖子的解决方式“通过调小以下参数来控制 schema 历史信息的回收”。观测是否有效果
schema_history_expire_time
schema_history_recycle_interval
1 个赞
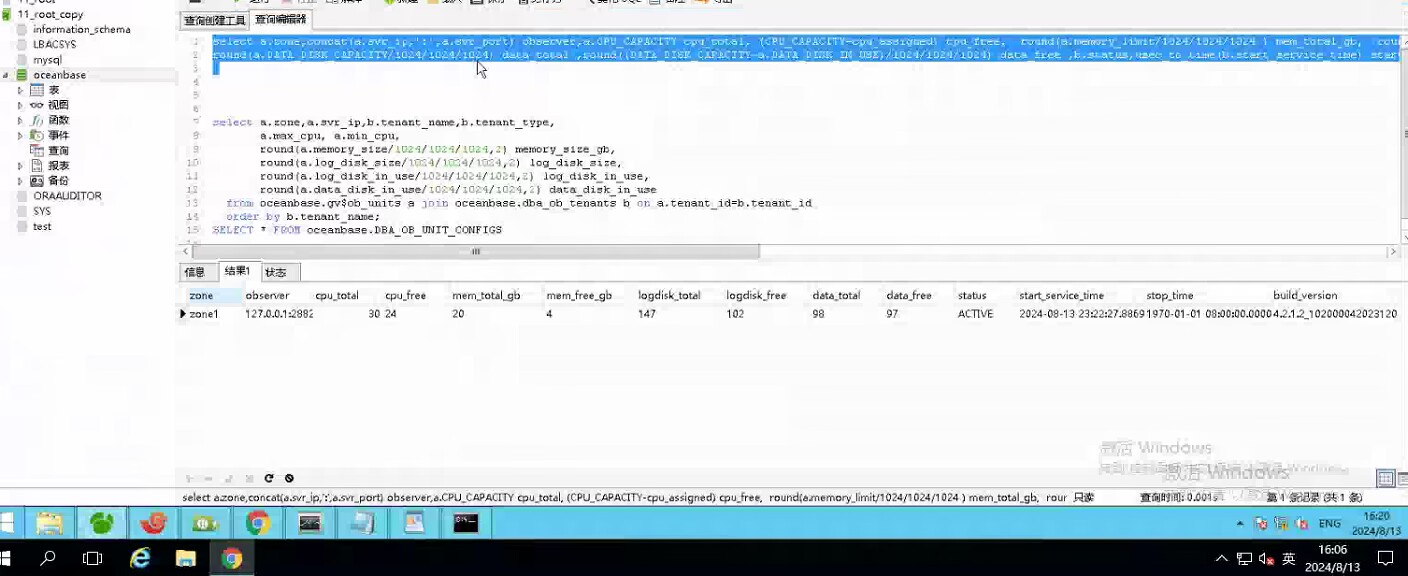
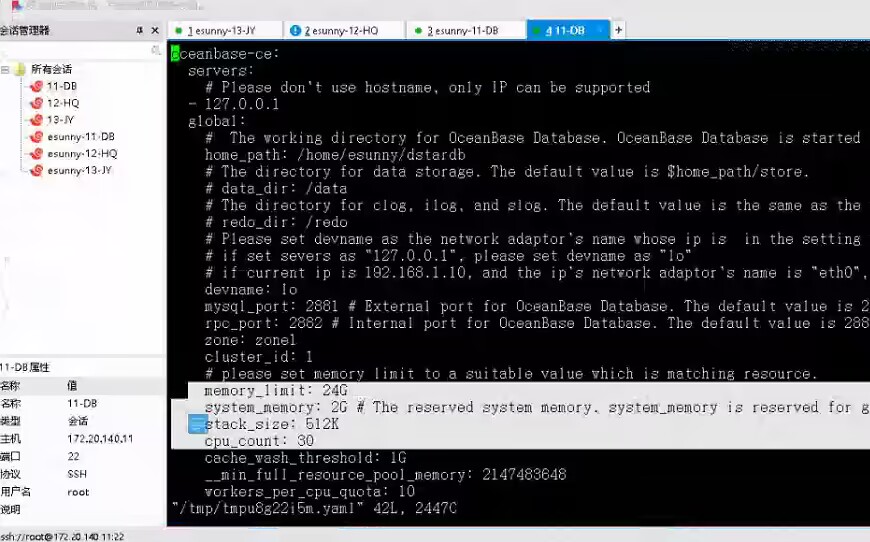
老师,图片是客户方提供的,不是很清楚。客户本身是32C 32G内存的机器,分给observer的是26C了。24G内存。您可以看一下
sys租户3个C
2)"CREATE TENANT IF NOT EXISTS dstar PRIMARY_ZONE=‘zone1’,RESOURCE_POOL_LIST=(‘user_pool’) SET OB_TCP_INVITED_NODES=’%’,LOWER_CASE_TABLE_NAMES = 0;
1 个赞
老师,有以下几点向您补充说明D20231011 VALUES LESS THAN (“2023-10-11”);
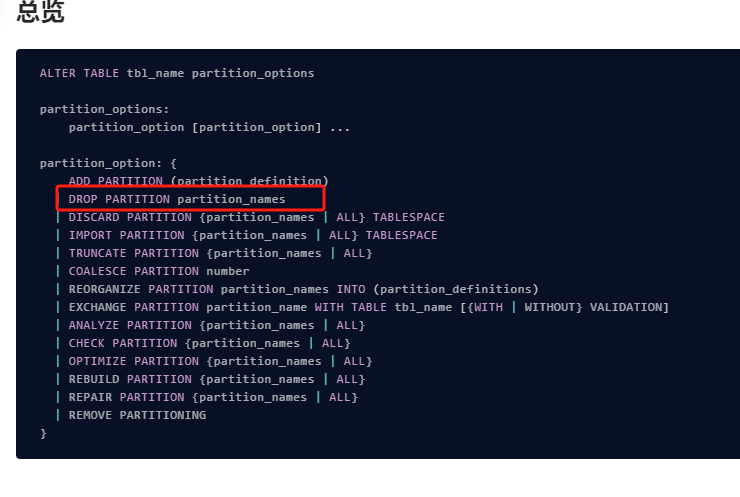
drop语句执行成功,分区D20231011原来是已经创建好的,他的后边原来就是D20231012
drop语句:ALTER TABLE THisPosition DROPPARTITION D20231011
1 个赞
淇铭
2024 年8 月 16 日 09:35
#19
我看你的另一个帖子说的 是有一个全局索引和两个本地索引
2、你可以尝试一下 调整这两个参数
schema_history_expire_time
schema_history_recycle_interval
https://www.oceanbase.com/knowledge-base/oceanbase-database-1000000000514283?back=kb
3、你可以用obdiag 收集执行的信息 贴一下 分析分析https://www.oceanbase.com/docs/common-obdiag-cn-1000000001102504
2 个赞
老师,我在数据库里查schema_history_expire_time和schema_history_recycle_interval,这两个变量,查不到都
1 个赞
淇铭
2024 年8 月 16 日 15:15
#21
这两个参数都是集群级配置项 查询的方式show parameters like ‘schema_history_expire_time’;
1 个赞