observer.rar (6.7 MB)
rootservice.rar (3.7 MB)
【 使用环境 】 测试环境
【 OB or 其他组件 】OB
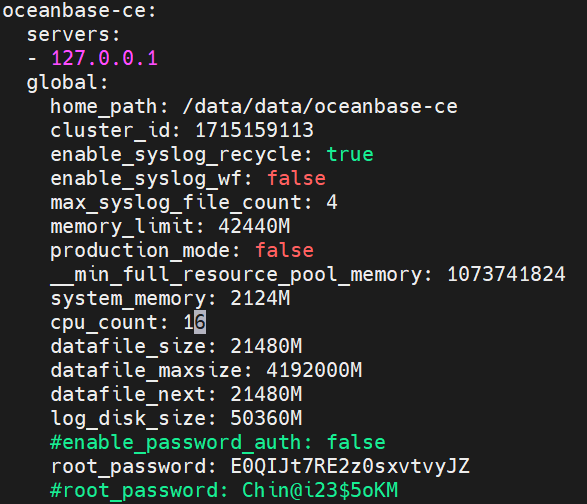
【 使用版本 】4.3.0.1
【问题描述】突然收到OB数据库无法登陆,看到observer 连接超时,重启obd cluster stop demo,然后obd cluster start demo,无法启动,提示如下
【复现路径】
Get local repositories and plugins ok
Load cluster param plugin ok
Open ssh connection ok
Cluster status check ok
Search plugins ok
Load cluster param plugin ok
Check before start observer ok
Check before start obproxy ok
Check before start obagent ok
Check before start prometheus ok
Check before start grafana ok
Start observer ok
observer program health check ok
obshell program health check ok
Connect to observer x
[ERROR] OBD-1006: Failed to connect to oceanbase-ce
[ERROR] OBD-1005: Some of the servers in the cluster have been stopped
See OceanBase分布式数据库-海量数据 笔笔算数 .
Trace ID: ff5fc01c-4af6-11ef-9001-0050568c4d06
If you want to view detailed obd logs, please run: obd display-trace ff5fc01c-4af6-11ef-9001-0050568c4d06
具体
[2024-07-26 10:35:26.856] [DEBUG] — connect 127.0.0.1 -P2881 -uroot -pE0QIJt7RE2z0sxvtvyJZ
[2024-07-26 10:35:26.860] [ERROR] Traceback (most recent call last):
[2024-07-26 10:35:26.861] [ERROR] File “core.py”, line 2532, in reload_cluster
[2024-07-26 10:35:26.861] [ERROR] File “core.py”, line 2572, in _reload_cluster
[2024-07-26 10:35:26.861] [ERROR] File “core.py”, line 2158, in _start_cluster
[2024-07-26 10:35:26.861] [ERROR] File “core.py”, line 197, in call_plugin
[2024-07-26 10:35:26.861] [ERROR] File “_plugin.py”, line 347, in call
[2024-07-26 10:35:26.861] [ERROR] File “_plugin.py”, line 305, in _new_func
[2024-07-26 10:35:26.861] [ERROR] File “/root/.obd/plugins/oceanbase-ce/4.2.2.0/connect.py”, line 625, in connect
[2024-07-26 10:35:26.862] [ERROR] cursor = Cursor(ip=server.ip, port=server_config[‘mysql_port’], tenant=’’, password=password if password is not None else ‘’, stdio=stdio)
[2024-07-26 10:35:26.862] [ERROR] File “_stdio.py”, line 908, in wrapper
[2024-07-26 10:35:26.862] [ERROR] File “/root/.obd/plugins/oceanbase-ce/4.2.2.0/connect.py”, line 517, in init
[2024-07-26 10:35:26.862] [ERROR] self._connect()
[2024-07-26 10:35:26.862] [ERROR] File “/root/.obd/plugins/oceanbase-ce/4.2.2.0/connect.py”, line 547, in _connect
[2024-07-26 10:35:26.862] [ERROR] self.db = mysql.connect(host=self.ip, user=self.user, port=int(self.port), password=str(self.password),
[2024-07-26 10:35:26.862] [ERROR] File “pymysql/connections.py”, line 353, in init
[2024-07-26 10:35:26.862] [ERROR] File “pymysql/connections.py”, line 633, in connect
[2024-07-26 10:35:26.863] [ERROR] File “pymysql/connections.py”, line 907, in _request_authentication
[2024-07-26 10:35:26.863] [ERROR] File “pymysql/connections.py”, line 725, in _read_packet
[2024-07-26 10:35:26.863] [ERROR] File “pymysql/protocol.py”, line 221, in raise_for_error
[2024-07-26 10:35:26.863] [ERROR] File “pymysql/err.py”, line 143, in raise_mysql_exception
[2024-07-26 10:35:26.864] [ERROR] pymysql.err.OperationalError: (8001, ‘Server is initializing’)
[2024-07-26 10:35:26.864] [ERROR]
[2024-07-26 10:35:29.958] [ERROR] OBD-1006: Failed to connect to oceanbase-ce
[2024-07-26 10:35:29.959] [DEBUG] – sub connect ref count to 0
[2024-07-26 10:35:29.959] [DEBUG] – export connect
[2024-07-26 10:35:29.959] [ERROR] OBD-1005: Some of the servers in the cluster have been stopped
[2024-07-26 10:35:29.966] [INFO] See OceanBase分布式数据库-海量数据 笔笔算数 .
[2024-07-26 10:35:29.966] [INFO] Trace ID: ff5fc01c-4af6-11ef-9001-0050568c4d06
[2024-07-26 10:35:29.967] [INFO] If you want to view detailed obd logs, please run: obd display-trace ff5fc01c-4af6-11ef-9001-0050568c4d06
然后我多次重启一样报错,但是ps -ef|grep observer有进程
[root@localhost log]# ps -ef|grep observer
root 6549 1 99 10:30 ? 00:21:12 /data/data/oceanbase-ce/bin/observer -p 2881
root 8388 3433 0 10:49 pts/1 00:00:00 grep observer
[root@localhost log]# obclient -uroot -p -h172.17.9.29 -P2881
Enter password:
ERROR 8001 (08004): Server is initializing
[root@localhost log]# obclient -uroot -p’E0QIJt7RE2z0sxvtvyJZ’ -h172.17.9.29 -P2881
ERROR 8001 (08004): Server is initializing
[root@localhost log]#
日志见附件
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):r