

【 使用环境 】生产环境
【 OB or 其他组件 】observer 4.2.2 obd 2.6.1
【 使用版本 】
【问题描述】
修改了starck_size重启集群,报错无法启动
先后修改了三次stack_size的值,1M,2M,5M,前两次重启正常,第三次无法重启
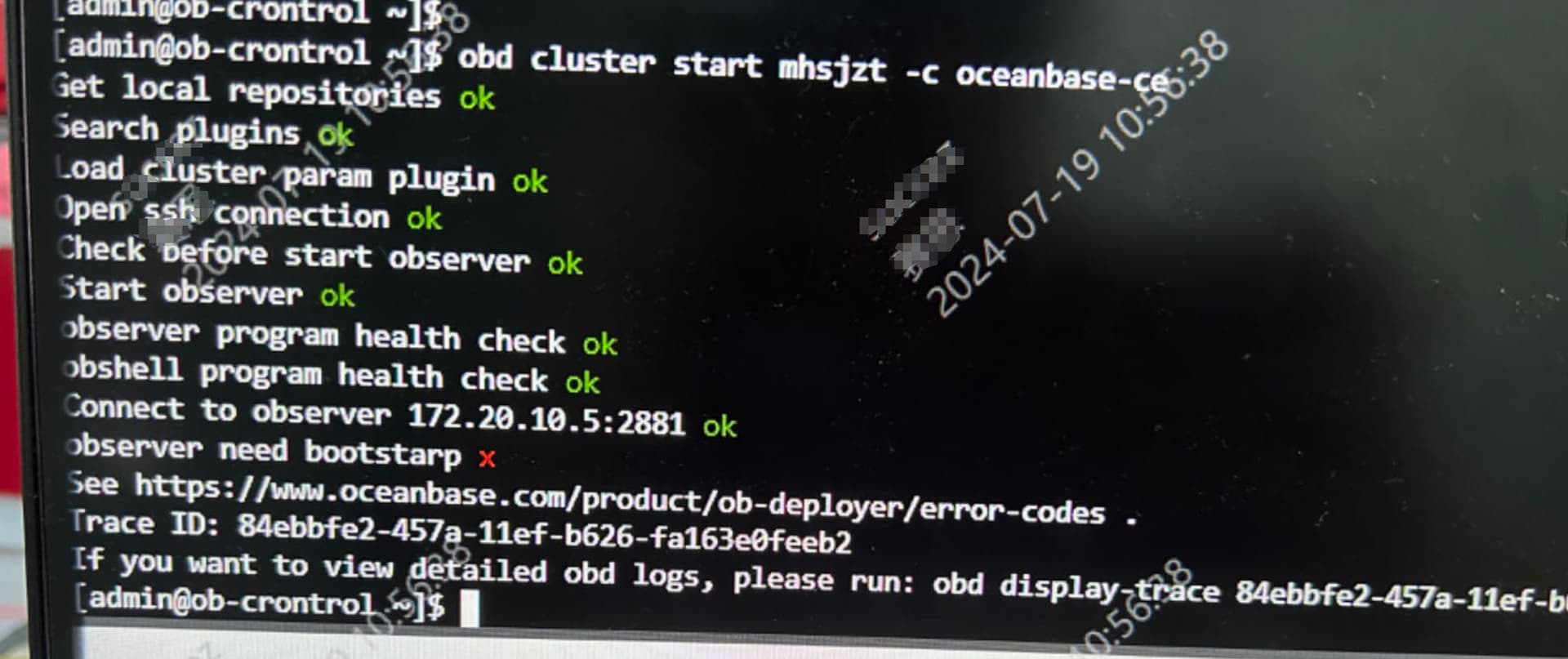
1、obd cluster start 启动一直卡在ocp-express
2、obd cluster start -c oceanbase-ce 启动报错 observer need bootstarp
【附件及日志】
obd.log (68.7 KB)
查看下ob日志 grep一下看看是否存在4147报错
发现了4013的错误 好像和内存有关系
提供一份obd日志,并贴一下config.ymal参数配置文件看看
是生产环境么,observer能麻烦截取一下发出来么。这边使用不了百度云盘
可以先使用obdiag去查下问题
obdiag gather scene run --scene=observer.memory --内存问题
obdiag analyze log --since 1h # 在线分析最近一小时的日志,诊断出出现过的错误
定位到了是调整stack_size的问题 用observer -o “stack_size=2M” 可以把集群起来
调整到3M就已经起不来了
是因为load data 的时候sql太长报错size overflow,所以调整栈大小
1 个赞
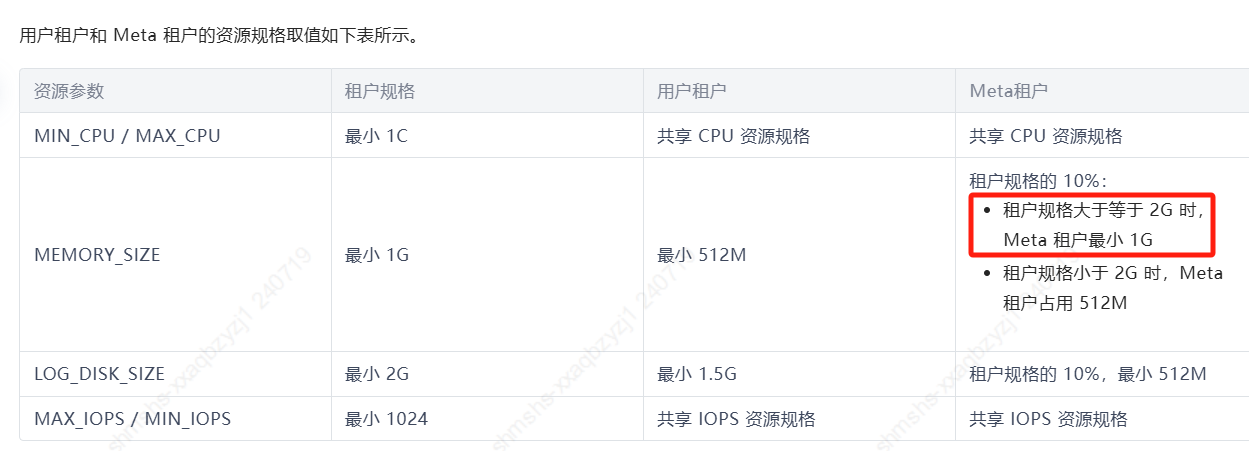
租户内存是不是不够了啊,才给1G
[2024-07-19 11:21:57.306899] WARN common_alloc (ob_tenant_ctx_allocator.cpp:458) [1220596][observer][T1002][Y0-0000000000000000-0-0] [lt=1][errcode=-4013] No memory or reach tenant memory limit([OOPS]=“alloc failed reason”, msg=tenant memory has reached the upper limit(tenant_id: 1002, tenant_hold: 1071906816, tenant_limit: 1073741824, alloc_size: 5373952))
[errcode=-4013] CO_STACK alloc failed(size=5356608)
是的 我看配置文件也不缺内存,ocp租户给的也很少,建议扩容一下
sys 2G ocp express的租户 2G 另外还有两个业务上的租户 20G和70G
想问问stack_size这个参数和内存之间的关系和影响 是不是和分配的线程数有关系 调大会影响系统性能吗
stack_size会影响到租户的线程数量,但一般不建议修改