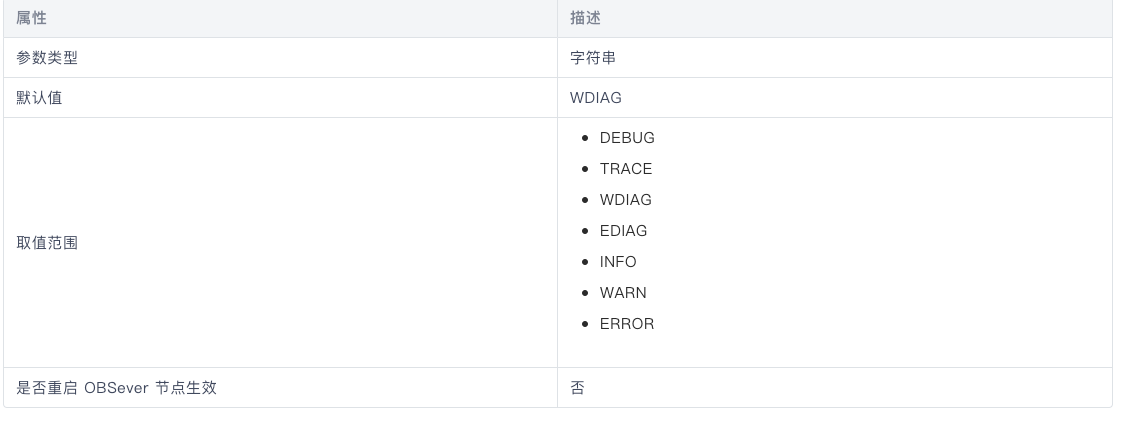
SQL语句比较长, 用的stack比较大,建议调整stack_size:
如下命令重启ob实例
./bin/observer -o “stack_size=1M”
不过在按照楼上发的 在获取一次日志信息 可以在具体看看
不过在按照楼上发的 在获取一次日志信息 可以在具体看看
按照则个方法我试了几次都拿不到日志,查询确实返回trace_id了, 但是在执行grep搜索rootservice.log和observer.log里就是找不到
没有问题呀 我执行测试了 如果执行报错可以的 你这个执行没有报错 是执行成功了吗?
这样设置后的日志内容和我在帖子里放出来的observer.log的日志内容会有所差异么? 我看经过这种参数配置,还是从observer.log里取日志。 我原帖子里已经有这个日志里。
想看看是不是还有其他日志信息 那你按着我楼上说的 那你把stack_size这个值调整一下
observer.log (58.2 KB)
抱歉,刚才没注意到grep搜索到时候引号是全角,现在已经收到日志了,但是rootservice.log里确实没有traceid的日志,我下载下来ctrl+f都没找到
rootservice.log没有找到 没有关系 先看看日志信息
可以试试,但是有几个细节确认一下:
1.我们使用obd部署的,没有用命令启动示例,是不是可以用obd cluster edit-config name的方式配置stack_size。和cpu_count这个参数在同一个级别
2.没想明白,这个SQL语句在这个业务系统里真不算长,我们其他业务报表比这个SQL长的有很多,那些报表貌似没有遇到过这个问题,计算stack_size的规则是什么,之前没有注意个过这个参数,ERP里大查询SQL很多
3.我搜集了其他遇到同样问题的帖子。截取了个回复
集群重启异常 - 社区问答- OceanBase社区-分布式数据库
我找相关的同学 在确定一下
改成1M看看吧,4x默认值从1M改成512k了
补充一下细节,把SQL最后的
limit 0,100
改成
limit 100
就可以正常执行,感觉跟Oceanbase内核对SQL语句的分析有关系
你limit 0,100 比limit 100解析的时候多了 几个字节 目前日志报的信息是stack_size小了 建议先修改一下
我们使用obd部署的,没有用命令启动示例,是不是可以用obd cluster edit-config name的方式配置stack_size。和cpu_count这个参数在同一个级别
这样会有效么
可以配置 不过都要重启
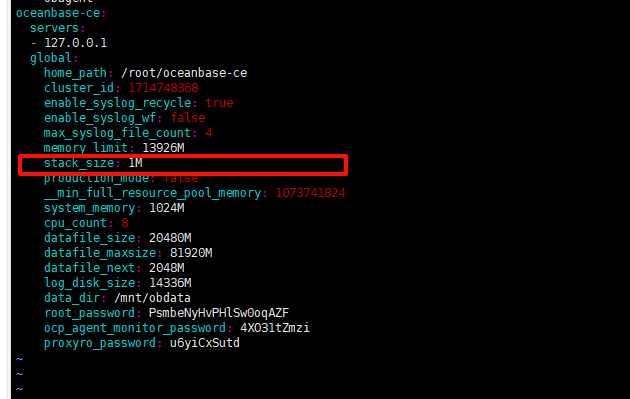
实测这样不行,可以通过执行
ALTER SYSTEM SET stack_size = '1M';
来修改,重启集群后通过查询
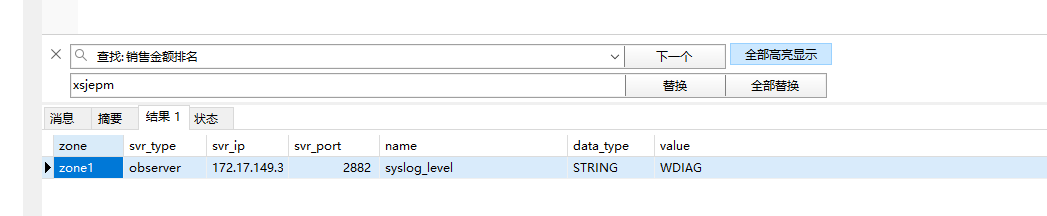
SELECT * FROM oceanbase.V$OB_PARAMETERS WHERE NAME = 'stack_size';
配置成功,也不报 Size overflow了。
但我始终还是觉得官方应该从内核上去确认一下看看什么情况下会出现这种错误,如果512不能应对比较复杂的查询,那4x版本将其默认值缩小到512KB的初衷是什么? 而且出现这种情况经过测试也绝不是SQL语句太长造成的,只要不简化SQL语句逻辑的复杂性,SQL语句减少多少字节是徒劳的。
换句话说我自己认为我们的业务属于小微应用,Oceanbase超大型企业都服务了,他们的业务应该更复杂吧,512KB的默认值是基于什么考量的呢?希望科普一下。
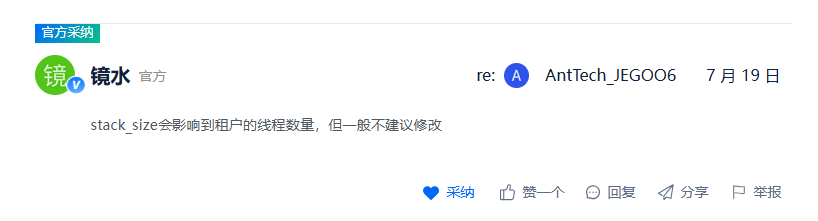
好的 感谢你的反馈 这个是ob后期的一个优化 租户的最大线程数 和这个堆栈的大小有关系
可以用命令重启吗,我看教程都是用云平台重启的,我同事之前没装云平台