【 使用环境 】生产环境
【 OB or 其他组件 】OB 4.2.1.7
【 使用版本 】OB 4.2.1.7
【问题描述】
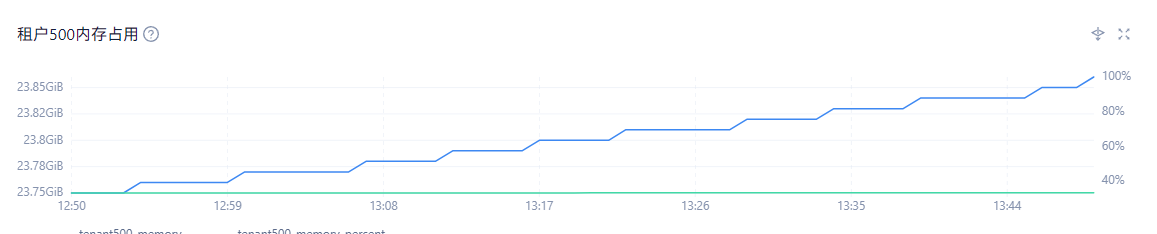
我是1:1:1模式部署的系统在最近OCP升级到4.3.0、OB升级到4.2.1.7以后OB经常自己挂掉
备注:之前的日志找不到了,这不是道为什么全是下面文件的日子信息
挂以后OCP会记录错误信息:
告警详情:[OBServer 非预期的内部错误] 集群:obcluster1,主机:10.10.10.147,日志类型:observer,日志文件:/home/admin/observer/log/observer.log,日志级别:ERROR,关键字=Unexpected internal error happen,错误码=4388,日志详情=[2024-07-06 19:32:12.732481] ERROR issue_dba_error (ob_log.cpp:1875) [2405246][T1001_ReplaySrv][T1001][Y0-0000000000000000-0-0] [lt=3830][errcode=-4388] Unexpected internal error happen, please checkout the internal errcode(errcode=-4389, file=“ob_ls_adapter.cpp”, line_no=106, info=“single replay task cost too much time. replay may be delayed”)。
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
observer.log.zip (330.9 KB)