桃纭
#1
【 使用环境 】 测试环境
【 OB or 其他组件 】
OceanBase 4.0.0
【问题描述】清晰明确描述问题
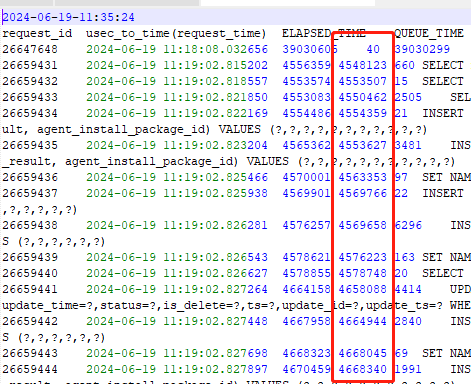
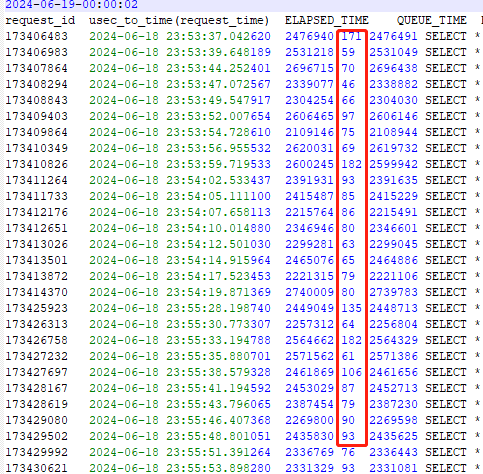
通过这条语句查询慢sql时,发现等待时间太长,和其他环境比起来慢太多了
select request_id,usec_to_time(request_time),ELAPSED_TIME,QUEUE_TIME,EXECUTE_TIME,query_sql
from v$OB_SQL_AUDIT where ELAPSED_TIME > 200000 limit 10;
提问数据库
其他数据库
为什么等待时间这么久,有什么方法排查嘛
靖顺
#3
按照这个文档中:【SOP系列 22 】——故障诊断第一步(自助诊断和诊断信息收集) 自助排查的思路把,第二步巡检结果和第四步的日志分析结果发出来看看
1 个赞
桃纭
#4
obdiag check日志
check_report.7z (1.5 KB)
obdiag analyze log 日志分析
result_details.txt (2.2 MB)
election.7z (7.5 MB)
observer.7z (8.4 MB)
rootservice.7z (5.5 MB)
靖顺
#5
看上面提供的obdiag 日志分析的结果,这个集群问题还挺多的。看起来是一个单节点的集群吧。
再拿点信息出来:
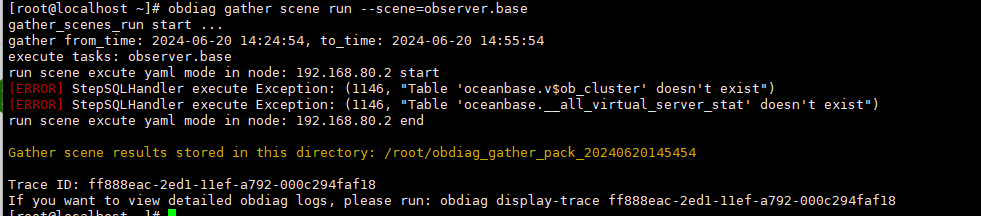
obdiag gather scene run --scene=observer.base
1 个赞
桃纭
#6
是的,这个是单节点
我的obdiag是,部署在另外一边的设备上面。执行这个会报错
有没有方法查看数据库中,等待中的sql
靖顺
#9
另外你这个问题非常像这篇知识库中提及的:OceanBase分布式数据库-海量数据 笔笔算数
例如有不少4122的错误日志在
[2024-06-20 07:41:26.447763] WARN [RPC.FRAME] create_session (ob_req_transport.cpp:242) [18232][LSSysTblUp0][T0][YCEE7F000001-00061AAE36D752E0-0-0] [lt=31] address in blacklist(ret=-4122, addr=“127.0.0.1:3310”)
1 个赞
桃纭
#10
[root@test log]# cat observer.log* | grep “KeepAliveClient”
[2024-06-20 07:39:12.158371] WARN [RPC.OBRPC] mark_white_black (ob_net_keepalive.cpp:258) [18411][KeepAliveClient][T0][Y0-0000000000000000-0-0] [lt=50] mark black, addr: 127.0.0.1:3310
[root@test log]#
这样表示加入到了黑名单嘛,只有早上7.35-7.40之间出现这个错误码
1.txt (4.2 KB)
后面就没有了
桃纭
#12
config.txt (2.0 KB)
这个是配置文件
感觉不要用4.0.0这个版本,能升级就升级,能升级就升级,这个init大版本,有一些莫名的问题,排查浪费浪费时间。
桃纭
#18
应该是的一开始用的4.0.0,后面升级成为了4.2.0了