rocH
2024 年4 月 16 日 18:38
#1
【 使用环境 】 测试环境xxxxstore_id int UNSIGNED NOT NULL COMMENT ‘店铺id’ ;
ALTER TABLE xxxxid, store_id);
ALTER TABLE xxxx PARTITION BY HASH(store_id) PARTITIONS 64 ;
表xxxx当前是张空表,无任何数据。
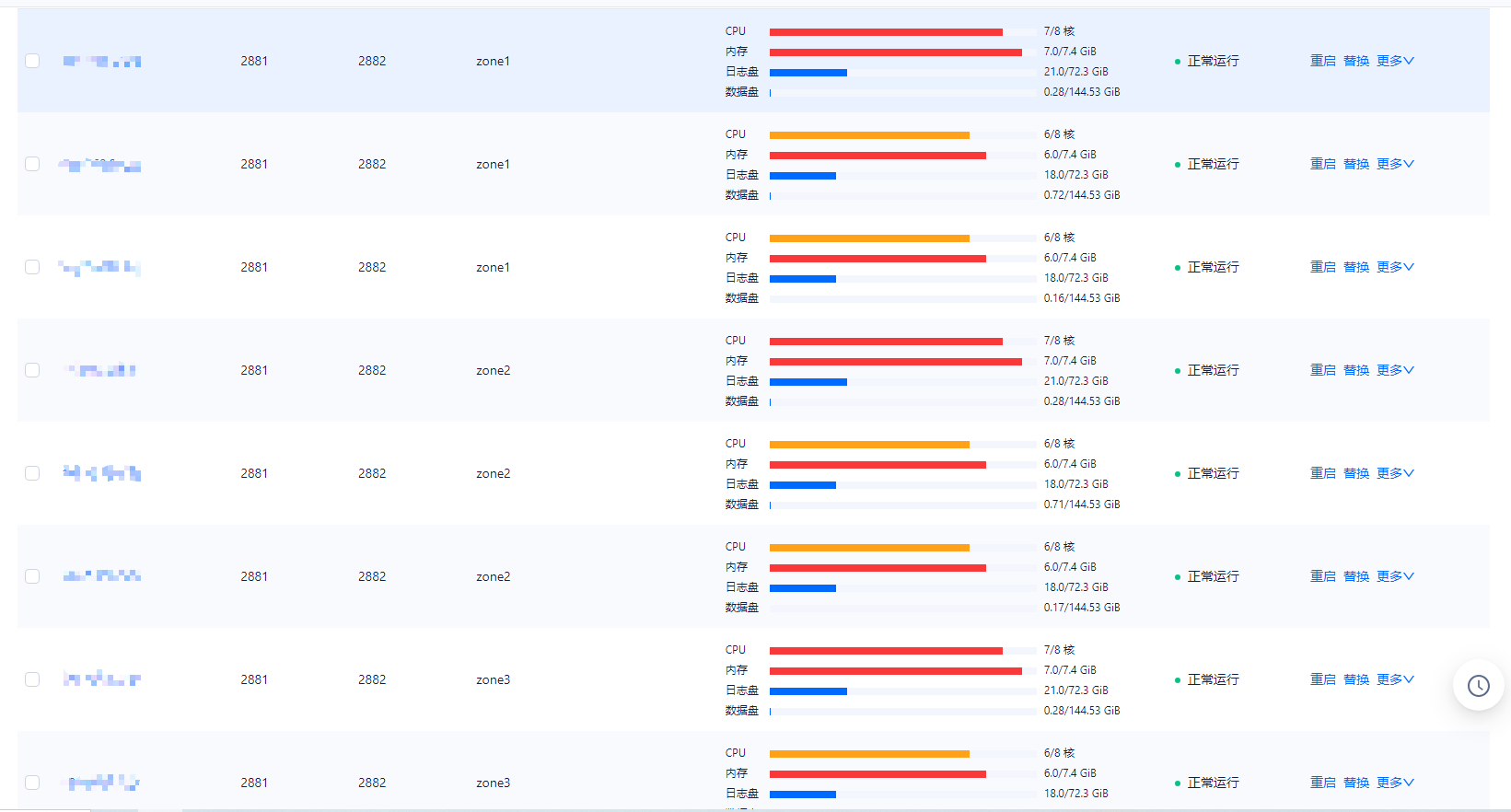
下面是服务器配置信息
zone
SVR_IP
SVR_PORT
STATUS
cpu_capacity
cpu_assigned_max
cpu_free
memory_total_gb
system_memory_gb
mem_assigned_gb
memory_free_gb
log_disk_capacity_gb
log_disk_assigned_gb
log_disk_free_gb
data_disk_gb
data_disk_used_gb
data_disk_free_gb
zone1
192.168.0.124
2882
ACTIVE
8
7
1
12.41
5.00
7.00
0.41
72.25
21.00
51.25
144.53
0.28
144.25
zone1
192.168.0.125
2882
ACTIVE
8
6
2
12.41
5.00
6.00
1.41
72.25
18.00
54.25
144.53
0.72
143.81
zone1
192.168.0.126
2882
ACTIVE
8
6
2
12.41
5.00
6.00
1.41
72.25
18.00
54.25
144.53
0.16
144.37
zone2
192.168.0.127
2882
ACTIVE
8
7
1
12.41
5.00
7.00
0.41
72.25
21.00
51.25
144.53
0.28
144.25
zone2
192.168.0.128
2882
ACTIVE
8
6
2
12.41
5.00
6.00
1.41
72.25
18.00
54.25
144.53
0.71
143.82
zone2
192.168.0.129
2882
ACTIVE
8
6
2
12.41
5.00
6.00
1.41
72.25
18.00
54.25
144.53
0.17
144.36
zone3
192.168.0.131
2882
ACTIVE
8
7
1
12.41
5.00
7.00
0.41
72.25
21.00
51.25
144.53
0.28
144.25
zone3
192.168.0.133
2882
ACTIVE
8
6
2
12.41
5.00
6.00
1.41
72.25
18.00
54.25
144.53
0.72
143.81
zone3
192.168.0.134
2882
ACTIVE
8
6
2
12.41
5.00
6.00
1.41
72.25
18.00
54.25
144.53
0.18
144.35
【复现路径】问题出现前后相关操作
【SOP系列 22 】——故障诊断第一步(自助诊断和诊断信息收集)
夏进
2024 年4 月 17 日 11:09
#3
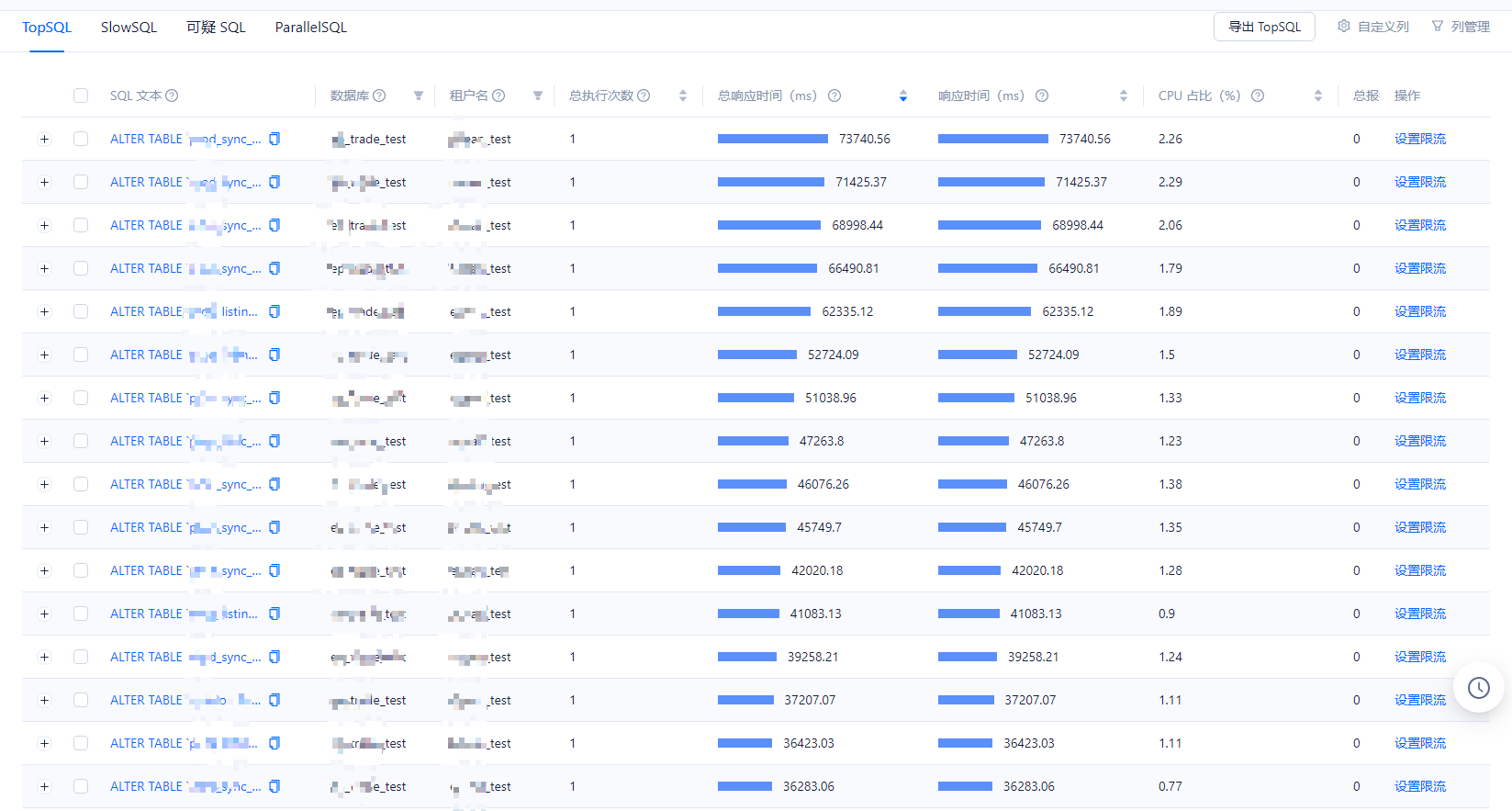
系统租户下,执行下 select * from _all_rootservice_event_history where module like '%ddl %’ and event=‘switch_state’; 看下上面执行DDL的耗时情况
rocH
2024 年4 月 17 日 12:27
#5
ddl.zip (362.4 KB)
补充一下资源分配详情。可以在 OCP 集群的资源管理页面看,也可以跑下面 SQL :
select t1.name resource_pool_name, t2.`name` unit_config_name,
t2.max_cpu, t2.min_cpu,
round(t2.memory_size/1024/1024/1024,2) mem_size_gb,
round(t2.log_disk_size/1024/1024/1024,2) log_disk_size_gb, t2.max_iops,
t2.min_iops, t3.unit_id, t3.zone, concat(t3.svr_ip,':',t3.`svr_port`) observer,
t4.tenant_id, t4.tenant_name
from __all_resource_pool t1
join __all_unit_config t2 on (t1.unit_config_id=t2.unit_config_id)
join __all_unit t3 on (t1.`resource_pool_id` = t3.`resource_pool_id`)
left join __all_tenant t4 on (t1.tenant_id=t4.tenant_id)
order by t1.`resource_pool_id`, t2.`unit_config_id`, t3.unit_id;
夏进
2024 年4 月 17 日 14:06
#7
excel里面的记录太多了,麻烦你那边确认下上面慢的3个ddl的task_id,例如执行 select * from __all_virtual_ddl_error_message; 找到ddl的task_id,然后再填入: select * from _all_rootservice_event_history where module like '%ddl %’ and event=‘switch_state’ and value4=“xxx”; (xxx是找到的task_id)
rocH
2024 年4 月 17 日 14:52
#9
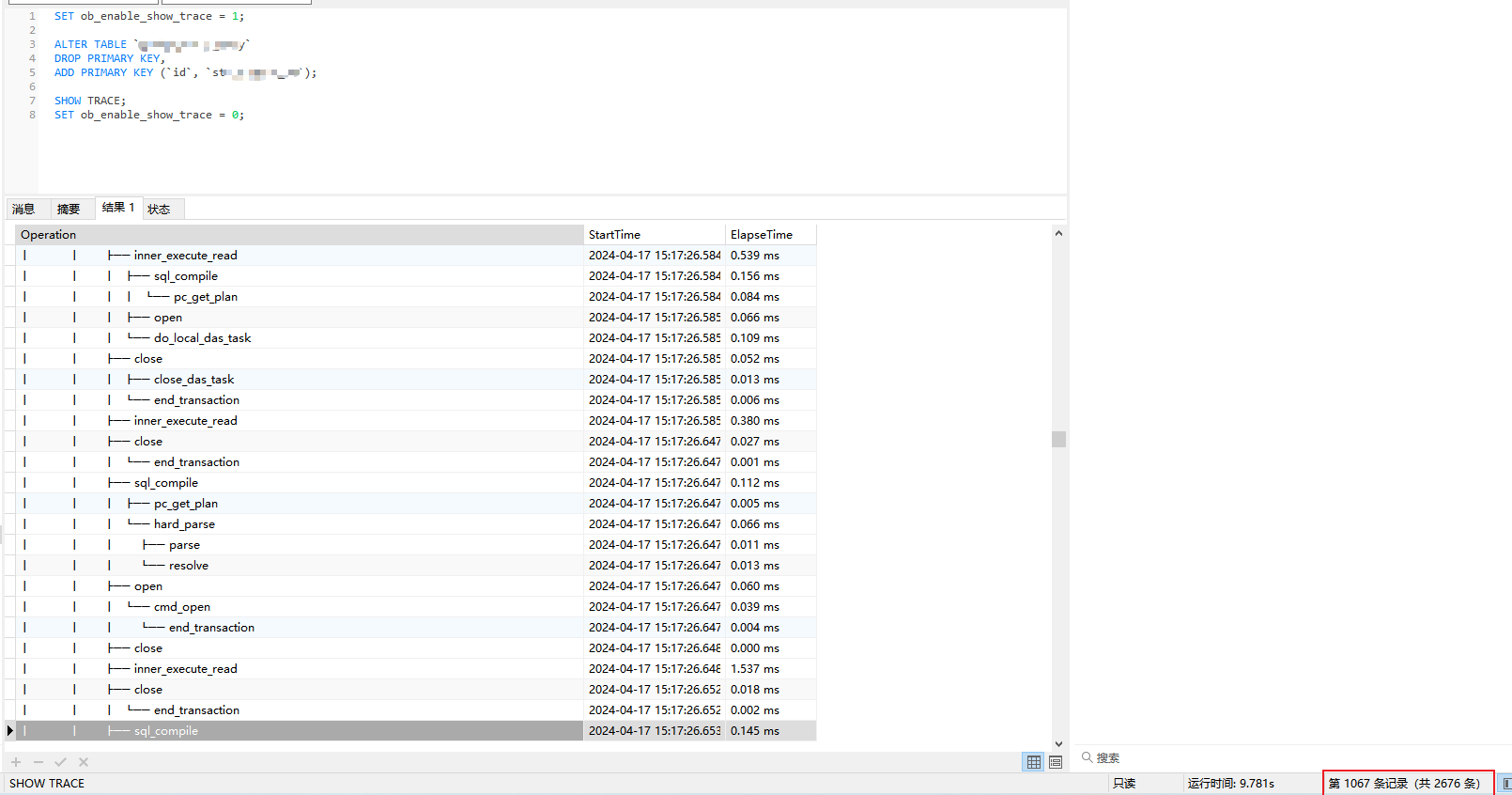
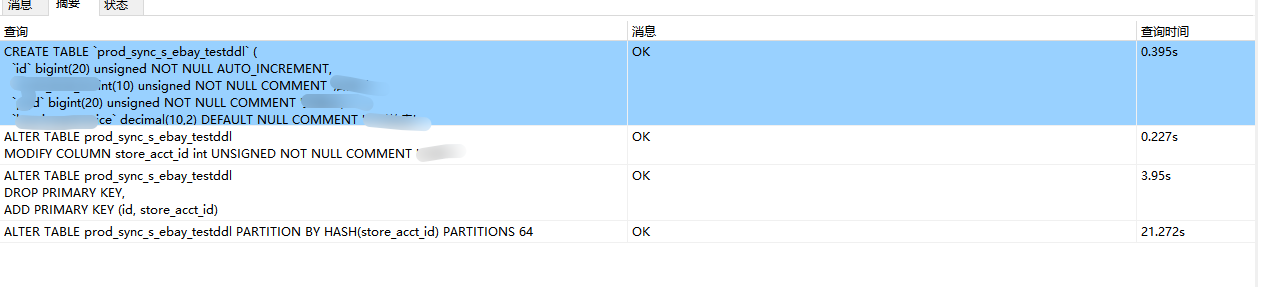
基本所有ddl都挺慢的。正常mysql空表ddl,是秒出结果的。
云深月隐
2024 年4 月 17 日 15:05
#10
夏进
2024 年4 月 17 日 15:12
#11
现在OB空表DDL,和有数据时走的是同一个流程,如果分区数比较多,或者索引比较多的情况下,会比较慢,但针对DDL性能的优化,预计下个版本会带上。
资源方面 sys 租户建议调整到 4c4g 。
云深月隐
2024 年4 月 17 日 15:54
#14
这个ddl操作的执行,确实太复杂了,需要优化一下。
rocH
2024 年4 月 17 日 16:40
#15
我之前的sys租户, 是1unit。 1C1G。
夏进
2024 年4 月 18 日 11:35
#16
只是一张空表,并且没有索引吗?或者有没有外键依赖?
rocH
2024 年4 月 24 日 15:04
#18
有建索引。 没有外键依赖。但索引表应该也是无数据的
rocH
2024 年4 月 24 日 15:13
#20
直接使用test库或者随便自己创建一个数据库。
直接create table 然后ddl。 也是很慢的。
夏进
2024 年4 月 24 日 19:47
#22
目前可以通过加hint或修改一些底层配置,可以加快速度