

【 使用环境 】 测试环境
【 OB or 其他组件 】observer
【 使用版本 】社区版3.1.4
【问题描述】利用备份执行跨集群恢复时,一直卡住
【复现路径】1.对集群所有机器进行挂载,2.创建资源单元,3.创建资源池,4.执行恢复,5.查看CDB_OB_RESTORE_PROGRESS表,status一直卡在RESTORE_SYS_REPLICA状态,FINISH_PARTITION_COUNT一直卡在22
备份集群基本没什么数据。恢复集群的资源单元是2c2g的。试了几次是必现的,这个问题应该怎么排查。
多谢,我安装确认下
在目标集群上查询下面事件视图,不断变换条件过滤掉无关的记录,看有没有 跟 restore 有关的事件一直在报错(value3 或 value4 是负值)。
SELECT gmt_create ,module,event ,name1 ,value1 ,name2,value2,name3,value3,name4,value4
FROM `__all_rootservice_event_history`
WHERE 1=1
-- AND module IN ('daily_merge')
ORDER BY gmt_create DESC LIMIT 1000;

需要发一下备集群的资源信息,跑下下面SQL:
select zone,concat(SVR_IP,':',SVR_PORT) observer,
cpu_capacity_max cpu_total,cpu_assigned_max cpu_assigned,
cpu_capacity-cpu_assigned_max as cpu_free,
round(memory_limit/1024/1024/1024,2) as memory_total,
round((memory_limit-mem_capacity)/1024/1024/1024,2) as system_memory,
round(mem_assigned/1024/1024/1024,2) as mem_assigned,
round((mem_capacity-mem_assigned)/1024/1024/1024,2) as memory_free,
round(log_disk_capacity/1024/1024/1024,2) as log_disk_capacity,
round(log_disk_assigned/1024/1024/1024,2) as log_disk_assigned,
round((log_disk_capacity-log_disk_assigned)/1024/1024/1024,2) as log_disk_free,
round((data_disk_capacity/1024/1024/1024),2) as data_disk,
round((data_disk_in_use/1024/1024/1024),2) as data_disk_used,
round((data_disk_capacity-data_disk_in_use)/1024/1024/1024,2) as data_disk_free
from gv$ob_servers;
select t1.name resource_pool_name, t2.`name` unit_config_name,
t2.max_cpu, t2.min_cpu,
round(t2.memory_size/1024/1024/1024,2) mem_size_gb,
round(t2.log_disk_size/1024/1024/1024,2) log_disk_size_gb, t2.max_iops,
t2.min_iops, t3.unit_id, t3.zone, concat(t3.svr_ip,':',t3.`svr_port`) observer,
t4.tenant_id, t4.tenant_name
from __all_resource_pool t1
join __all_unit_config t2 on (t1.unit_config_id=t2.unit_config_id)
join __all_unit t3 on (t1.`resource_pool_id` = t3.`resource_pool_id`)
left join __all_tenant t4 on (t1.tenant_id=t4.tenant_id)
order by t1.`resource_pool_id`, t2.`unit_config_id`, t3.unit_id;
看看 还原的时候这个租户资源池还原出来么?
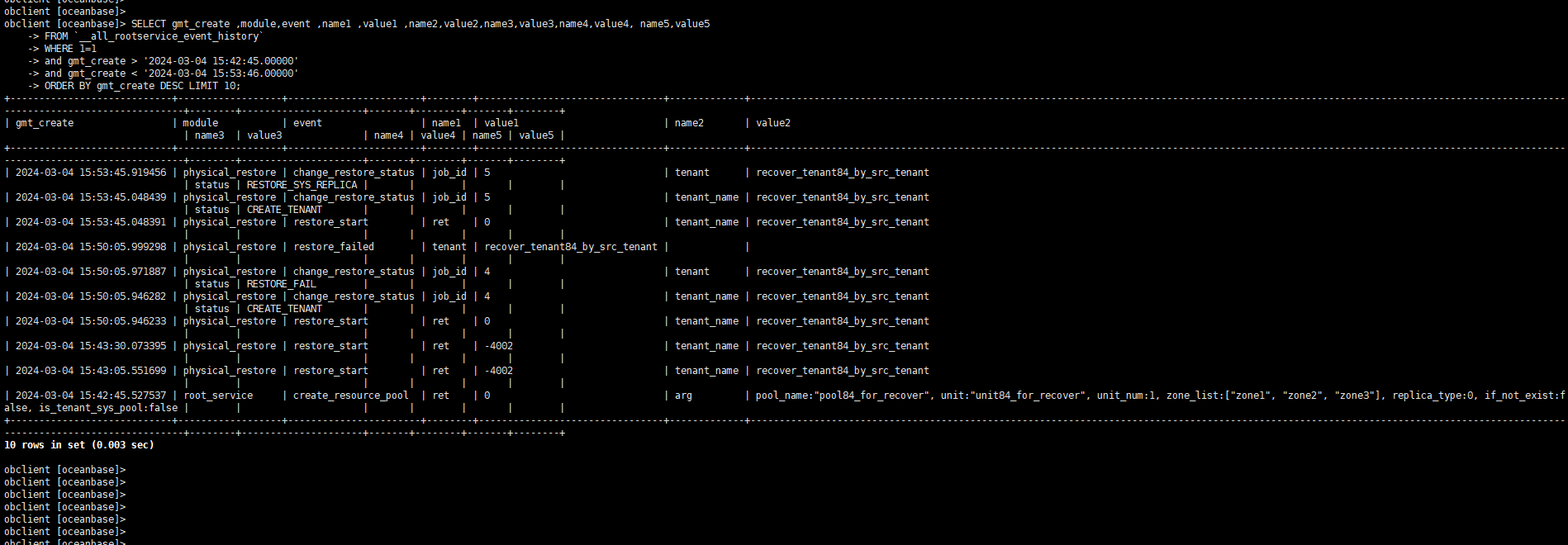
再查一下,把 列 name5,value5 放出来。
SELECT gmt_create ,module,event ,name1 ,value1 ,name2,value2,name3,value3,name4,value4, name5,value5
FROM `__all_rootservice_event_history`
WHERE 1=1
-- AND module IN ('physical_restore','root_service')
ORDER BY gmt_create DESC LIMIT 10;

不好意思,给错版本了。
select a.zone,concat(a.svr_ip,':',a.svr_port) observer, cpu_total, (cpu_total-cpu_assigned) cpu_free
, round(mem_total/1024/1024/1024) mem_total_gb, round((mem_total-mem_assigned)/1024/1024/1024,2) mem_free_gb
, round(disk_total/1024/1024/1024) disk_total_gb, round((disk_total-disk_assigned)/1024/1024/1024) disk_free_gb
from __all_virtual_server_stat a join __all_server b on (a.svr_ip=b.svr_ip and a.svr_port=b.svr_port)
order by a.zone, a.svr_ip
;
select t1.name resource_pool_name, t2.`name` unit_config_name, t2.max_cpu, t2.min_cpu
, round(t2.max_memory/1024/1024/1024) max_mem_gb, round(t2.min_memory/1024/1024/1024) min_mem_gb
, round(t2.max_disk_size/1024/1024/1024) max_disk_size , t4.tenant_name
from __all_resource_pool t1 join __all_unit_config t2 on (t1.unit_config_id=t2.unit_config_id)
join __all_unit t3 on (t1.`resource_pool_id` = t3.`resource_pool_id`)
left join __all_tenant t4 on (t1.tenant_id=t4.tenant_id)
order by t1.`resource_pool_id`, t2.`unit_config_id`, t3.unit_id
;
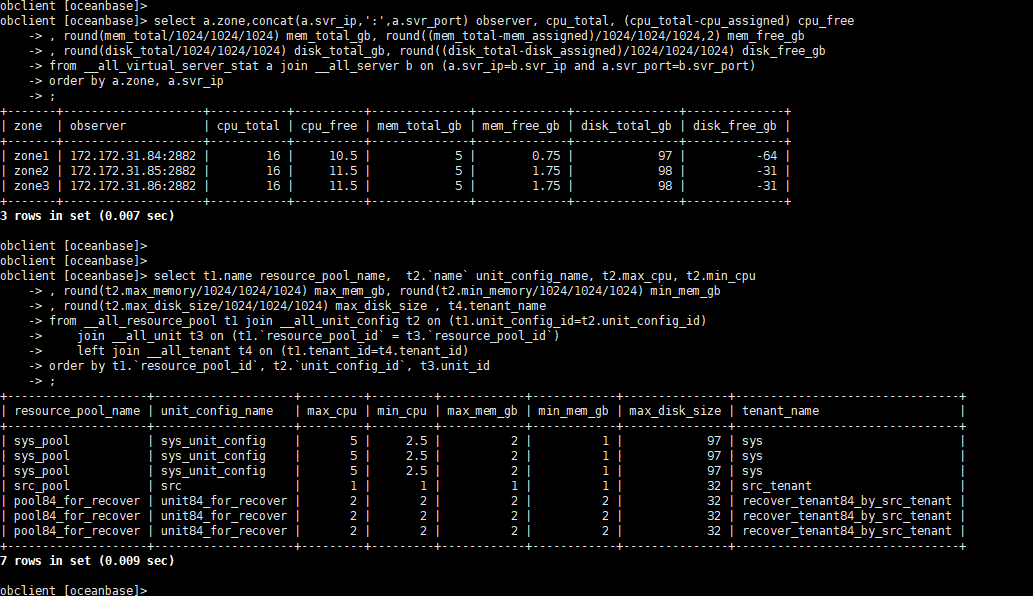
disk 这个应该没啥关系。
我看整个集群的节点主机内存估计很小,8G 不到吧。 这么小规格的 OB 做 恢复演练我不确定能不能成功。
具体可能要用 obdiag 收集相关日志进行分析。这个会比较费精力,不建议做。
如果你能把集群节点内存扩容到 16G 再做这个实验,成功的概率会高很多。
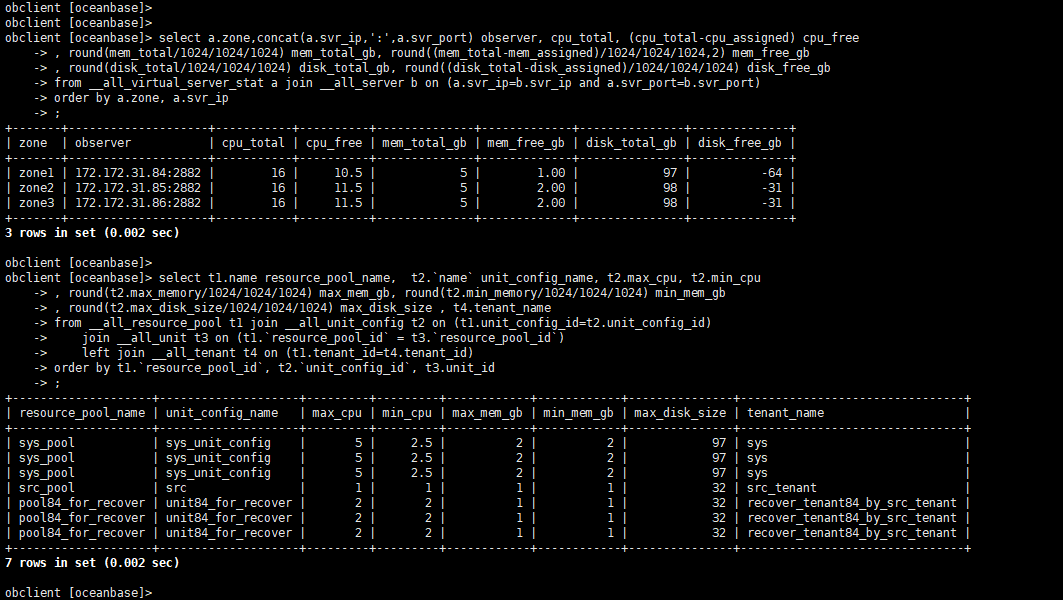
此外,看起来像是 zone1的节点内存用完了。
sys_unit_config的最小最大内存没有拉平,这个导致剩余内存的计算总不是那么直观。
你先执行下面SQL
alter resource unit sys_unit_config max_memory='2G',min_memory='2G';
然后再跑一下前面 2个 SQL。
看看 节点的剩余内存是不是负数。或者上面 alter 语句可能就直接失败了。
然后执行下面SQL
alter system set __min_full_resource_pool_memory=1073741824;
alter resource unit unit04_for_recover max_memory='1G',min_memory='1G';
然后再执行 前面那个 alter resource unit sys_unit_config max_memory='2G',min_memory='2G';
再重新执行前面2个查询语句,看剩余内存。
然后等一会再查看 __all_rootservice_event_History 看恢复事件是不是在成功推进。
obdiag 支持按照场景来收集信息,比如恢复问题直接执行:
obdiag gather scene run --scene=observer.recovery
1 个赞
obdiag gather scene list 可以查看所有支持的版本。用obdiag来排查问题/收集信息更高效,一键执行就行。
我执行试试,谢谢
问题是否已解决?
内存暂时没加上,没继续往下测
恢复不了的问题前面有同学确认是内存问题了。
建议后续使用4.x的OceanBase吧,3.1分支的版本已经很老了。
2 个赞