【 使用环境 】生产环境
【 OB or 其他组件 】OB4.2.0版本和OCP express 4.2.0版本
【 使用版本 】4.2.0升级
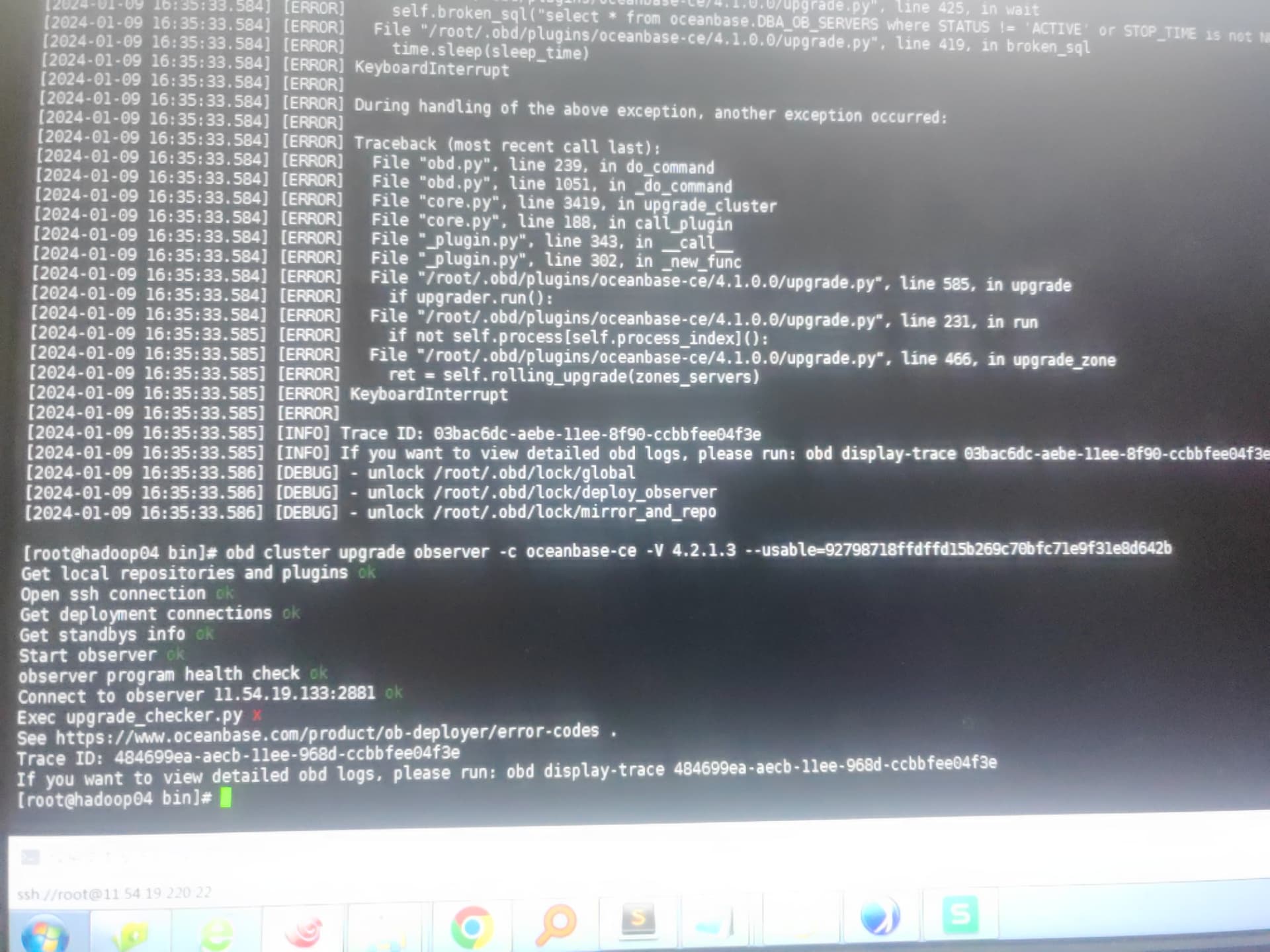
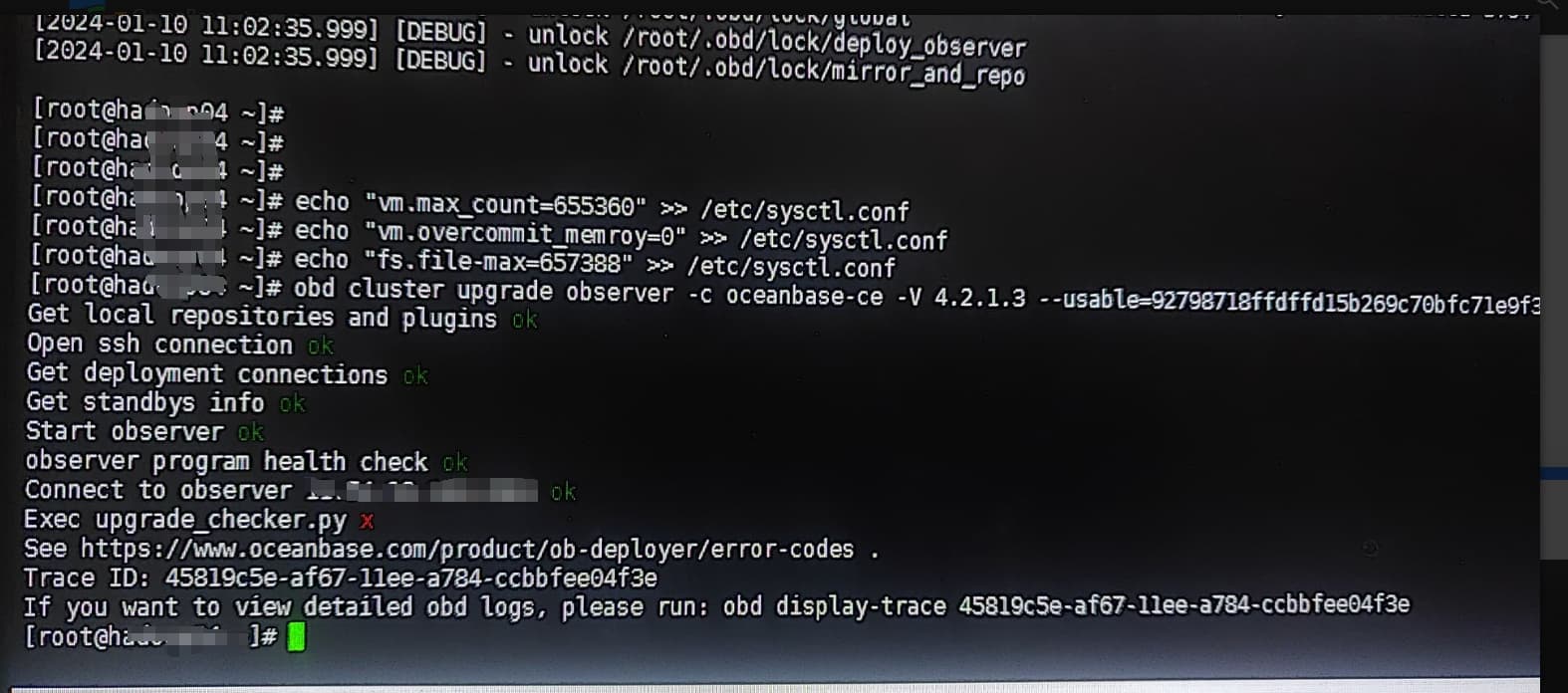
【问题描述】OB4.2.0版本升级到4.2.1社区版,不成功,报错update_checker.py
【复现路径】重新执行升级命令,还是报错
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【SOP系列 22 】——故障诊断第一步(系统巡检和诊断信息收集)
日志附件:
2024-01-09_obd_log.rar (7.1 MB)
1 个赞
王利博
#4

可以尝试下重复执行升级命令。。
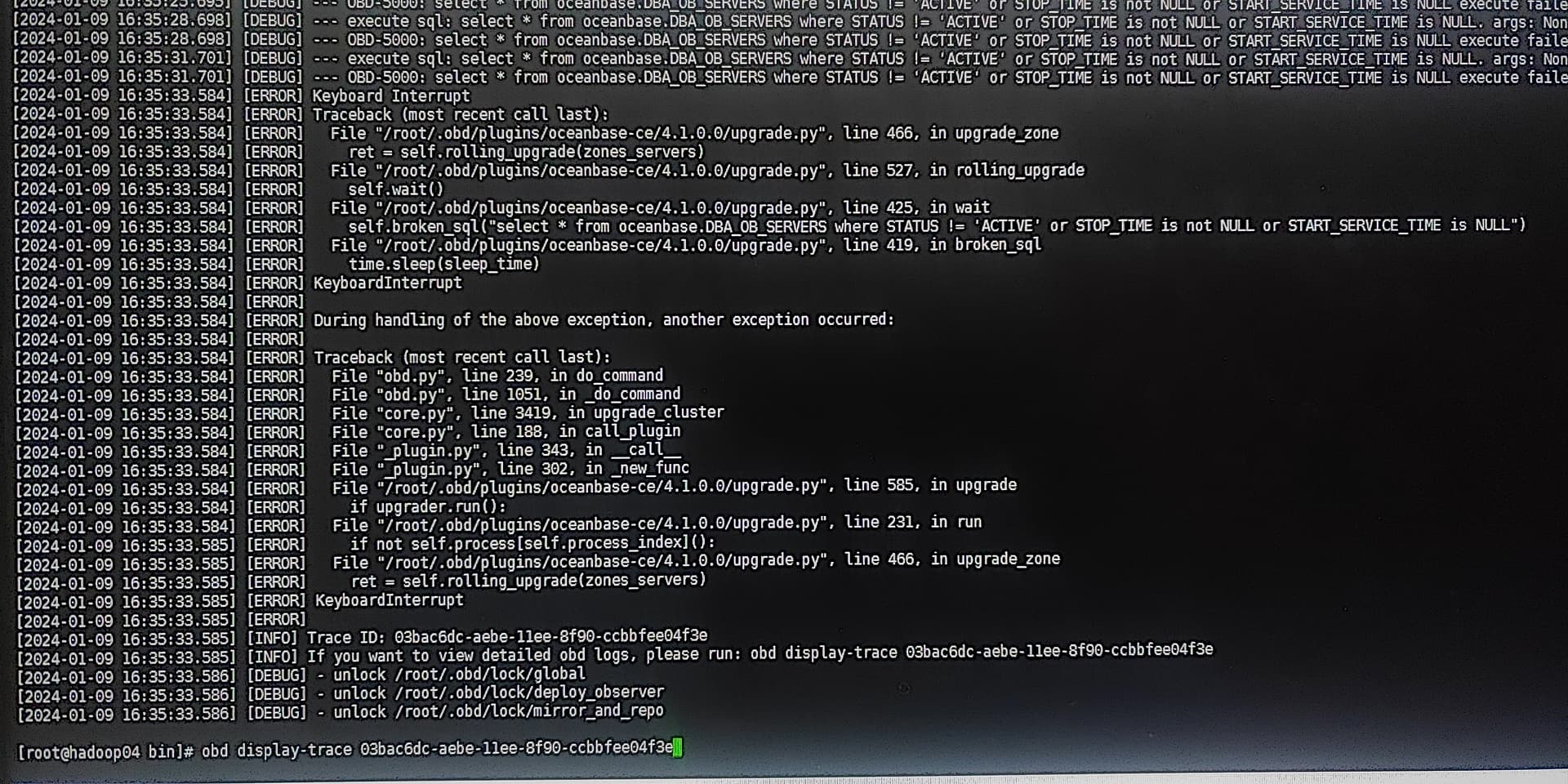
如果还报错发下 obd display-trace 命令日志信息
秃蛙
#5
OBD日志报错一些系统参数配置不符合预期,可以按提示执行下。
王利博
#6
echo “vm.max_map_count=655360” >> /etc/sysctl.conf
echo “vm.overcommit_memory=0” >> /etc/sysctl.conf
echo “fs.file-max=6573688” >> /etc/sysctl.conf
还有可以使用OceanBase敏捷诊断工具obdiag来进行收集集群诊断信息。看看集群还有那些隐患。
已经重复执行了,还是同样的错误。而且原来的升级进程一直在执行
秃蛙
#11
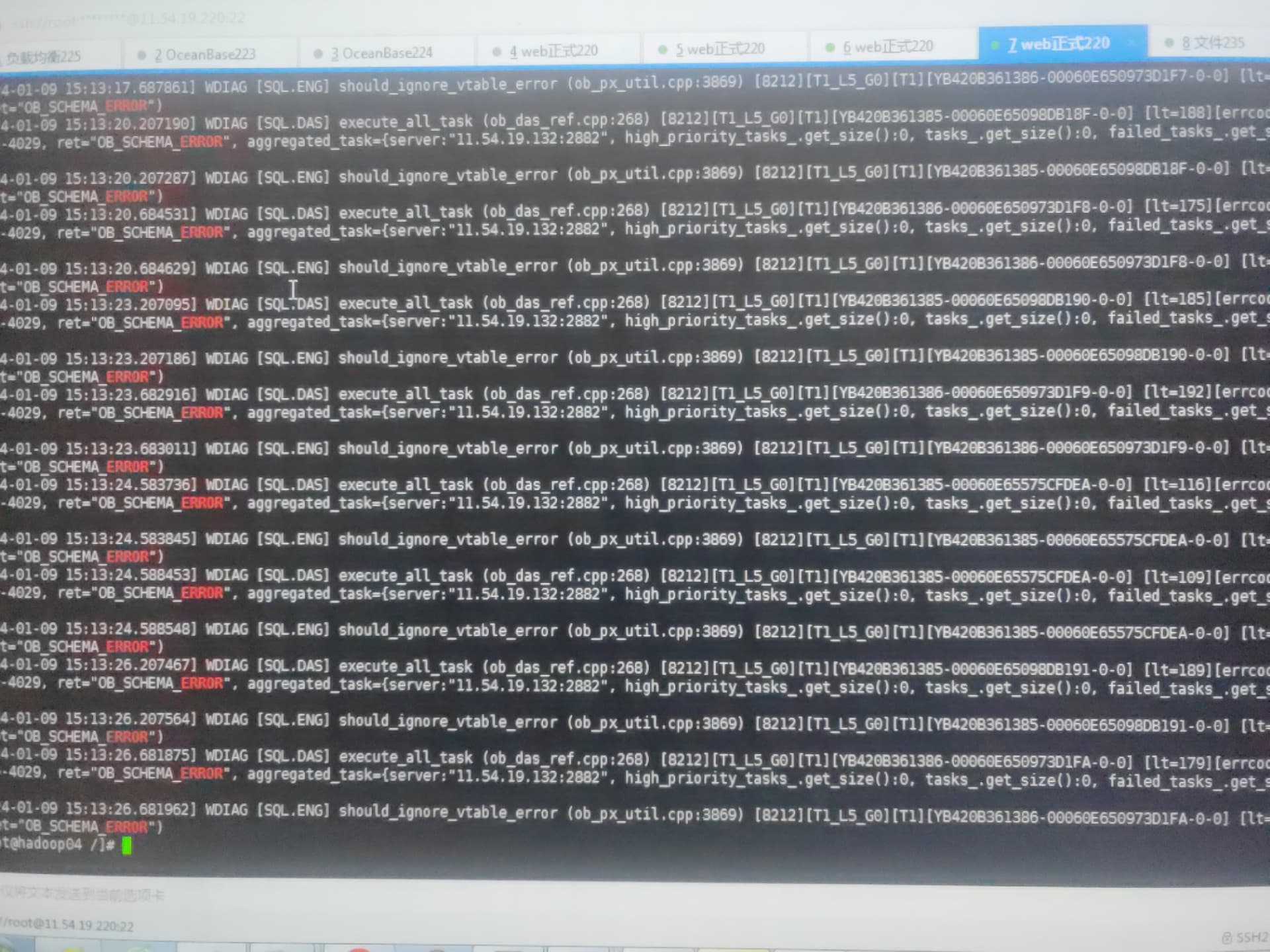
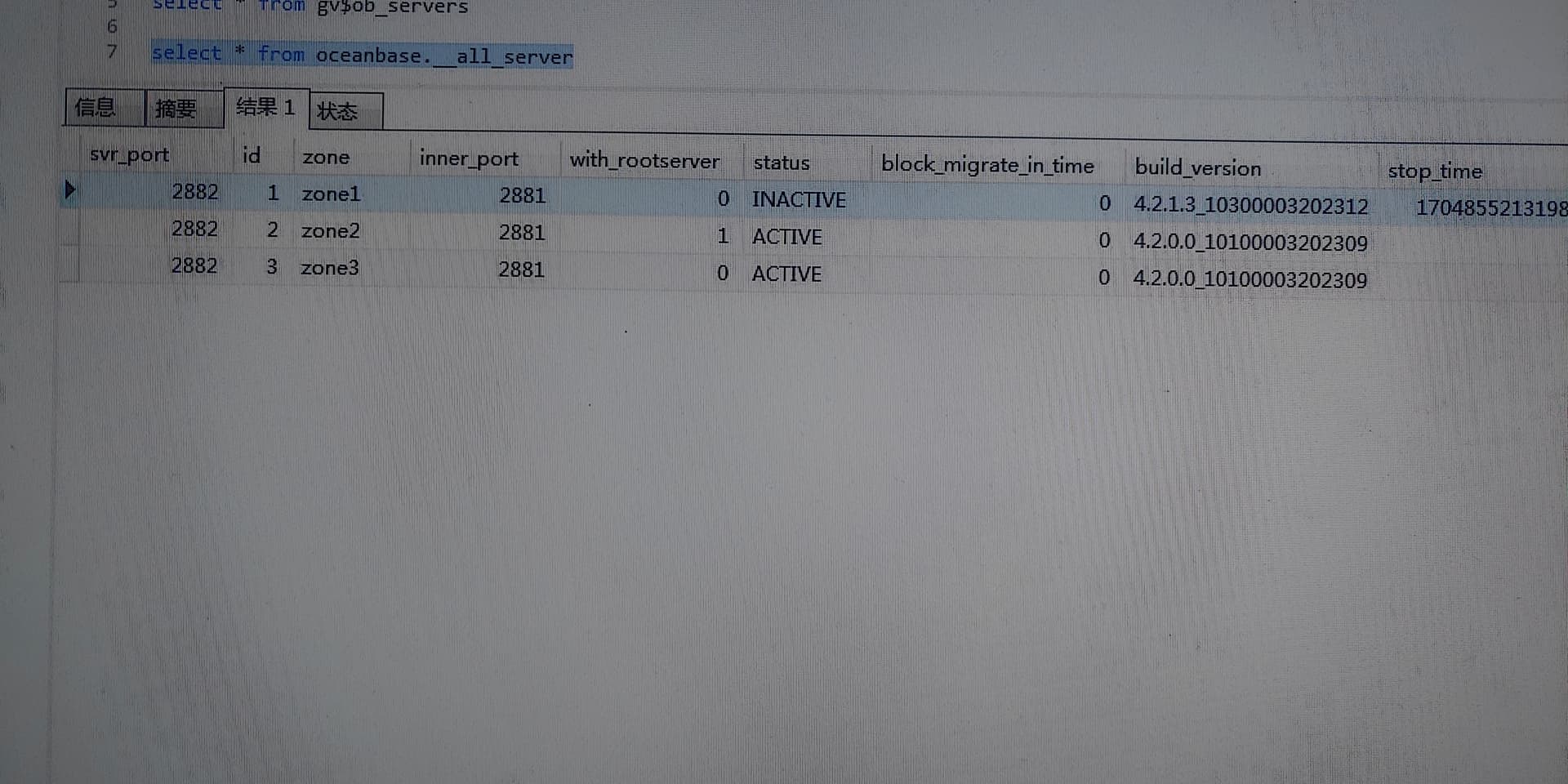
报错集群状态不正常 系统租户登录 查询:select * from oceanbase.__all_server;
附件里就是完整的。OBD和observer.log
秃蛙
#16
obclient -uroot@sys -P2881 -h xx.xx.xx.xx -D oceanbase
查询:select * from oceanbase.__all_server;
王利博
#17
SELECT * FROM oceanbase.DBA_OB_TENANTS limit 10; 这个看下。
秃蛙
#19
看下zone1节点进程还在吗 ps -ef|grep obs 然后取一下zone1和zone2节点的 observer.log和rootserice.log。
秃蛙
#22
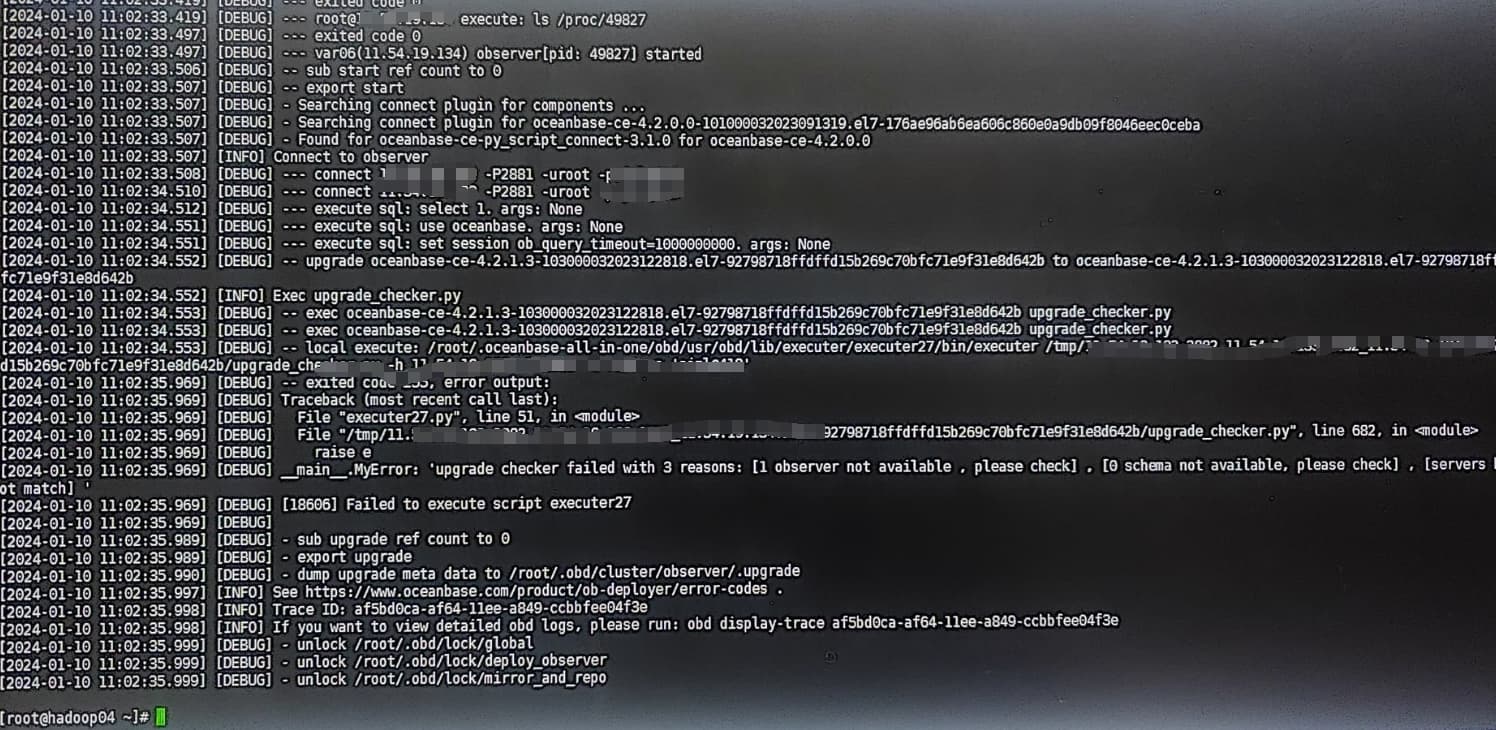
问题已解决,问题原因:
1)OB服务器上有hadoop集群,占用内存,导致OB设置的内存一直未生效。
2)升级zone1后,重启observer失败,日志报错大量内存不足信息:No memory or reach tenant memory limit([OOPS]=“alloc failed reason”,导致无法启动,状态inactive,阻塞后续zone升级。
解决方案:
1)./bin/observer -o memory_limit=‘60G’; 先指定一个内存大小,暂时拉起节点。
2)关闭hadoop程序,释放内存空间。
3)内存释放出来后,express上重新设置内存,memory_limit:150G system_memory:27G 。
4)再继续执行obd 升级 ob动作,可重复执行。
注意:现场环境开启swap,建议关闭。ob需要独占服务器资源,强烈建议hadoop程序迁走。
3 个赞