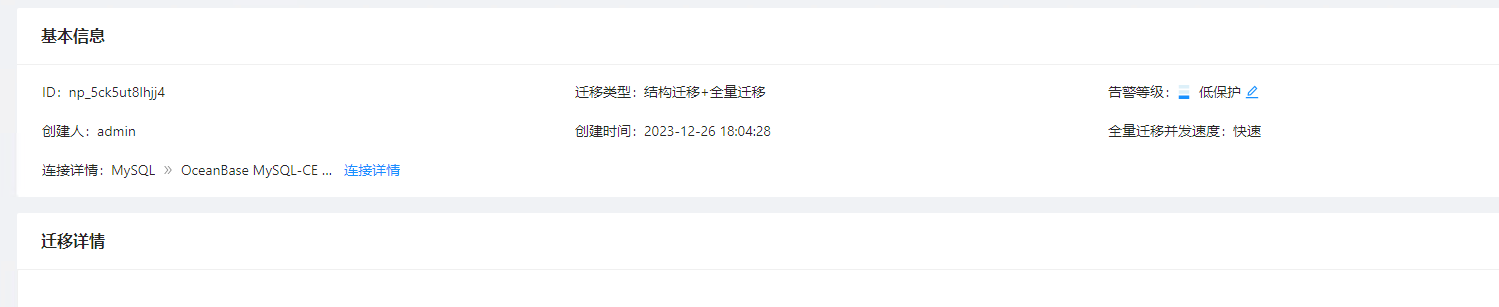
【 使用环境 】 测试环境
【 OB or 其他组件 】OMS
【 使用版本 】4.2.1_CE
【问题描述】OMS结构迁移时大量失败
【复现路径】
迁移一个公网环境的数据库到测试OB集群里,在结构迁移时出现了大量表结构迁移失败问题,且租户所在的服务器CPU占用过高(个人判断),失败原因大致如下:
(conn=3221933522) Lock wait timeout exceeded; try restarting transaction Query:
(conn=3221904278) Timeout Query:
(conn=3221967417) Lock wait timeout exceeded; try restarting transaction Query:
(conn=3221904291) RPC session not found Query:
由于失败太多以上是抽查表里的失败提示,跑了200张表失败的差不多80张了。
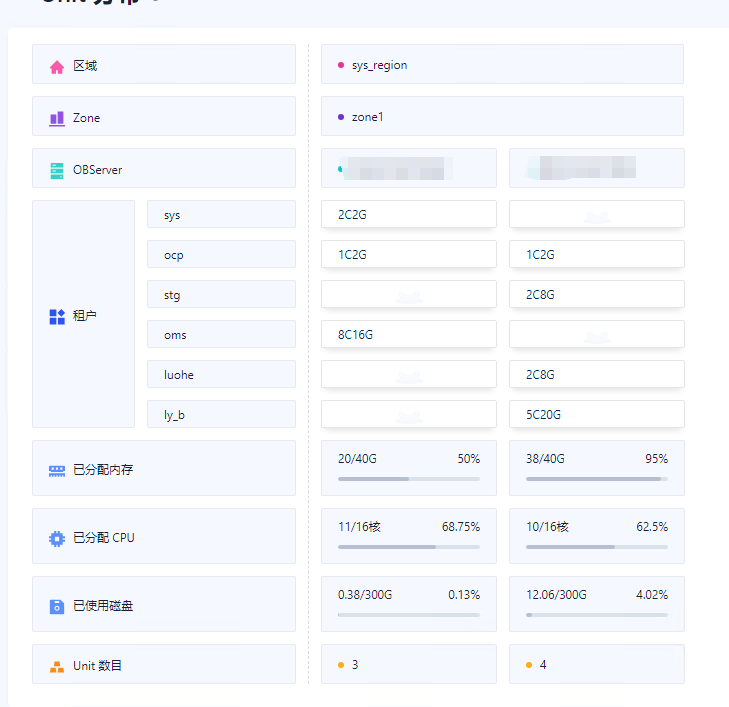
上图是迁移任务的大概配置
上图是集群的大概配置
这种情况可能是什么原因导致的?
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【SOP系列 22 】——故障诊断第一步(系统巡检和诊断信息收集)
经过多次重试失败对象最终完成了迁移,但是体验很差。200多张表结构迁移花了3个多小时,而1亿行数据只花了36分钟
所有表结构在没有做修改的情况下最终都成功了,失败原因绝大部分和锁、超时有关,不知道是不是我的集群部署问题还是什么情况。源数据库中一些表有字符集不统一问题,迁移时做了字符集转换,但是一部分做过转换的表也能成功,看不出来问题出在哪。我的集群data与log在同一个磁盘上不知道有没有关系,如果有关系迁移数据时又没有出现类似的问题导致数据迁移失败。
(conn=3221933522) Lock wait timeout exceeded; try restarting transaction Query:
(conn=3221904278) Timeout Query:
(conn=3221967417) Lock wait timeout exceeded; try restarting transaction Query:
(conn=3221904291) RPC session not found Query:
就是这些类型和表结构信息,失败的处理时间都在900000ms以上,没有更多的信息了
刘彻
#8
这个应该是目标端建表超时了,这个跟你目标库繁忙应该有关
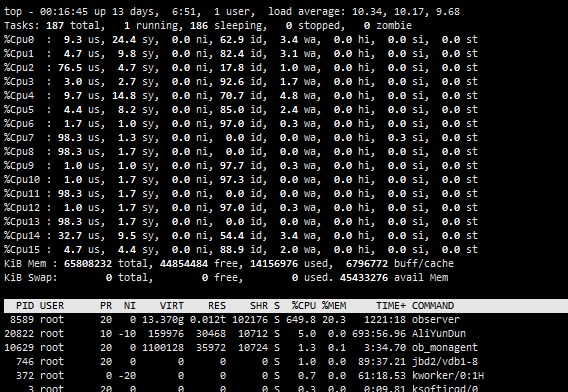
结构迁移时目标库什么都干不了,同时CPU占用过高。而且目前时测试阶段没有任务在ob集群上跑,有什么方法能排查一下问题出在哪吗?
王小A
#10
看监控截图已经蛮高了,在Linux平台上可以直接使用 perf 命令看下消耗CPU比较多的几个函数是什么