

OBD 部署的集群重启方式
使用 OBD 重启 OceanBase
1、使用 OBD 重启 OceanBase 所有服务
[admin@obtest004 ~]$ obd cluster restart testob2
2、使用 OBD 重启指定 OceanBase 组件服务
[admin@obtest004 ~]$ obd cluster restart testob2 -c oceanbase-ce
3、使用 OBD 重启指定组件和指定节点的 OceanBase 服务
[admin@obtest004 ~]$ obd cluster restart testob2 -c oceanbase-ce -s 172.xxx.xxx.250
Get local repositories and plugins ok
Load cluster param plugin ok
Open ssh connection ok
Cluster status check ok
Connect to observer ok
Server check ok
Observer restart ok
Wait for observer init ok
+---------------------------------------------------+
| observer |
+-----------------+---------+------+-------+--------+
| ip | version | port | zone | status |
+-----------------+---------+------+-------+--------+
| 172.xxx.xxx.250 | 4.0.0.0 | 2881 | zone1 | ACTIVE |
+-----------------+---------+------+-------+--------+
obclient -h172.xxx.xxx.250 -P2881 -uroot -pRoot123@@Root123 -Doceanbase -A
succeed
参数说明:
| 选项名 | 是否必选 | 数据类型 | 默认值 | 说明 |
|---|---|---|---|---|
| -s/–servers | 否 | string | 空 | 机器列表,后跟 yaml 文件中 servers 对应的 name 值,用 , 间隔,用于指定需要重启的机器。 |
| -c/–components | 否 | string | 空 | 组件列表,用 , 间隔。用于指定需要重启的组件。如果配置下的组件没有全部启动,该配置不会进入 running 状态。 |
| –wp/–with-parameter | 否 | bool | false | 带参重启。用于让重启生效的配置项生效。 |
说明
若不指定具体机器及或组件,则会重启所有 OBServer 节点和组件。
使用 OBD 重启 OBProxy
1、查看 obproxy 进程
[admin@obtest002 ~]$ ps -ef | grep obproxy
admin 20144 19946 0 14:01 pts/0 00:00:00 grep --color=auto obproxy
admin 31204 1 0 Mar03 ? 00:02:20 bash /home/admin/obproxy/obproxyd.sh /home/admin/obproxy 172.xxx.xxx.250 2883 daemon
admin 31225 1 1 Mar03 ? 01:07:40 /home/admin/obproxy/bin/obproxy --listen_port 2883
从上述示例中可以看到两个进程:obproxy 就是 ODP 的进程名,obproxyd.sh 是 ODP 的守护脚本。
2、使用 OBD 重启全部节点的 OBProxy 服务
[admin@obtest004 ~]$ obd cluster restart testob2 -c obproxy-ce
3、使用 OBD 重启指定节点的 OBProxy 服务
[admin@obtest004 ~]$ obd cluster restart testob2 -c obproxy-ce -s 172.xxx.xxx.250
Get local repositories and plugins ok
Load cluster param plugin ok
Open ssh connection ok
Cluster status check ok
Stop obproxy ok
Start obproxy ok
obproxy program health check ok
Connect to obproxy ok
+---------------------------------------------------+
| obproxy |
+-----------------+------+-----------------+--------+
| ip | port | prometheus_port | status |
+-----------------+------+-----------------+--------+
| 172.xxx.xxx.250 | 2883 | 2884 | active |
+-----------------+------+-----------------+--------+
obclient -h172.xxx.xxx.250 -P2883 -uroot -pRoot123@@Root123 -Doceanbase -A
succeed
3、确认 obproxy 进程
[admin@obtest002 ~]$ ps -ef | grep obproxy
admin 20633 1 0 14:01 ? 00:00:00 bash /home/admin/obproxy/obproxyd.sh /home/admin/obproxy 172.xxx.xxx.250 2883 daemon
admin 20654 1 1 14:01 ? 00:00:00 /home/admin/obproxy/bin/obproxy --listen_port 2883
admin 20818 19946 0 14:02 pts/0 00:00:00 grep --color=auto obproxy
后台手动重启 OceanBase
1、节点停服(可选)
如果是在测试环境中,或者比较着急的情况下可以不用发起节点停服命令,直接进行下一步强行"杀"进程。
alter system stop server '节点ip:2882' ;
节点停服后,节点上如果有主副本,会自动切换为备副本。节点的备副本依然参与投票,但不会当选为主副本。
OceanBase 节点停服和 OceanBase 宕机性质不同,节点停服时间可以超出参数永久下线时间 server_permanent_offline_time 而不会导致节点真的下线。
节点停服后,大概 1~2 秒后就可以观察到有主备副本切换事件。确认 SQL 如下:
SELECT DATE_FORMAT(gmt_create, '%b%d %H:%i:%s') gmt_create_ , module, event, name1, value1, name2, value2, rs_svr_ip FROM __all_rootservice_event_history WHERE 1 = 1 AND gmt_create > SUBDATE(now(),interval 1 hour) ORDER BY gmt_create DESC LIMIT 20;
2、杀进程
# 除非是测试用或者评估过风险,否则不要用 `kill -9`。
[admin@obtest002 ~]$ kill `pidof observer`
# 等待 60s,等进程完全退出
[admin@obtest002 ~]$ sleep 60
# 反复确认进程完全退出
[admin@obtest002 ~]$ ps -ef | grep observer |grep -v grep
3、配置环境变量,否则启动 observer 会报错:找不到 libmariadb.so.3: cannot open shared object file
#将 OceanBase 数据库的 LIB 加到环境变量 LD_LIBRARY_PATH 中
echo 'export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/oceanbase-ce/lib/' >> ~/.bash_profile
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/oceanbase-ce/lib/
4、启动进程
# 启动进程 (注意:直接执行./observer 不会启动成功)
[admin@obtest002 ~]$ cd /home/admin/observer && bin/observer
# 等待 10s 进程启动
[admin@obtest002 ~]$ sleep 10
# 反复确认进程启动时没有退出
[admin@obtest002 ~]$ ps -ef | grep observer | grep -v grep
# 等待 60s,等进程完全启动并恢复完毕
[admin@obtest002 ~]$ sleep 60
5、启动节点服务(可选)
若之前将节点停服了,需要先启动该节点服务。
alter system start server '节点IP:2882' ;
6、重启后验证
# 在集群中查看节点状态(status)、开始服务时间(start_service_time)是否正常。
#V4.x 版本
SELECT * FROM oceanbase.DBA_OB_SERVERS\G
说明
节点的start_service_time状态正常之后方可重启其他 Zone 所在的机器。同一个 Zone 的多台机器可以并行重启。
后台手动重启 OBProxy
1、杀进程
# 查看 obproxy 进程
[admin@obtest002 ~]$ ps -ef|grep obproxy |grep -v grep
#kill 方式杀掉进程
[admin@obtest002 ~]$ kill 守护进程pid
[admin@obtest002 ~]$ kill 进程pid
# 反复确认进程完全退出
[admin@obtest002 ~]$ ps -ef | grep obproxy
2、启动进程
#使用业务用户在 obproxy 安装目录下执行,否则无法拉起
[admin@obtest002 obproxy]$ cd ~/obproxy && ./bin/obproxy
#启动守护进程
[admin@obtest002 obproxy]$ chmod 733 obproxyd.sh
[admin@obtest002 obproxy]$ sh obproxyd.sh /home/admin/obproxy xxx.xxx.xxx.xxx 2883
3、 确认 obproxy 进程
# 确认进程是否启动成功
[admin@obtest002 ~]$ ps -ef | grep obproxy | grep -v grep
# 查看进程监听成功(默认监听 2883 和 2884 端口)
[admin@obtest002 ~]$ netstat -ntlp
OCP 部署的集群重启方式
使用 OCP 重启 OceanBase
详细步骤请参见 OceanBase 云平台。
使用 OCP 重启 OBProxy
详细步骤请参见 OceanBase 云平台。
后台手动重启 OceanBase
注意
OCP 创建的集群默认使用 admin 启动,若重启时使用 root 启动了,会导致 OCP 无法管理集群。解决方法请见下文 **常见问题处理。
1、杀进程
# 除非是测试用或者评估过风险,否则不要用 `kill -9`。
[admin@obtest001 ~]$ kill `pidof observer`
# 反复确认进程完全退出
[admin@obtest001 ~]$ ps -ef | grep observer |grep -v grep
2、启动进程
说明
若需要带参启动,则在 -o 后指定需要修改的参数即可。
[admin@obtest001 ~]$ cd /home/admin/oceanbase && bin/observer -o "datafile_size=80G"
3、确认 observer 进程,等待一段时间后刷新 OCP 页面,确认集群是否恢复正常。
# 确认进程是否启动成功
[admin@obtest001 ~]$ ps -ef | grep observer | grep -v grep
# 查看进程监听成功(默认监听 2881 和 2882 端口)
[admin@obtest001 ~]$ netstat -ntlp
后台手动重启 OBProxy
注意
OCP 创建的 OBProxy 集群也需要使用 admin 启动。
1、杀进程
# 查看 obproxy 进程
[admin@obtest001 ~]$ ps -ef|grep obproxy |grep -v grep
#kill 方式杀掉进程
[admin@obtest001 ~]$ kill 守护进程pid
[admin@obtest001 ~]$ kill 进程pid
# 反复确认进程完全退出
[admin@obtest001 ~]$ ps -ef | grep obproxy
2、启动进程
#使用业务用户在 obproxy 安装目录下执行,否则无法拉起
[admin@obtest001 obproxy-4.0.0]$ cd ~/obproxy-4.0.0 && ./bin/obproxy
#启动守护进程
[admin@obtest001 obproxy-4.0.0]$ cd ~/obproxy-4.0.0 && ./bin/obproxyd.sh -c start
3、 确认 obproxy 进程
# 确认进程是否启动成功
[admin@obtest001 ~]$ ps -ef | grep obproxy | grep -v grep
# 查看进程监听成功(默认监听 2883 和 2884 端口)
[admin@obtest001 ~]$ netstat -ntlp
常见问题处理
问题现象:OCP 部署的 OceanBase 集群,使用 root 用户后台启动 observer 后,会导致 OCP 管理失败。在后台再使用 admin 用户启动也会失败。
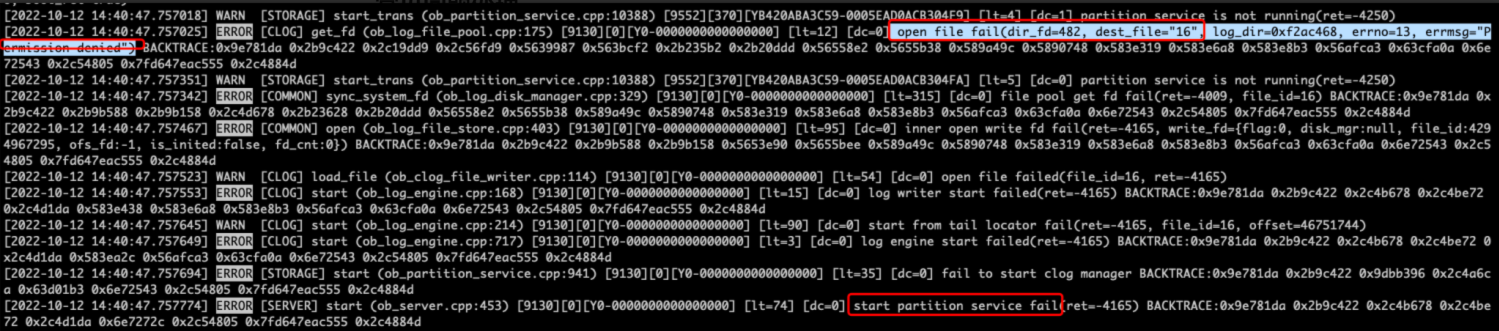
报错: ERROR [COMMON] inner_open_fd (ob_log_disk_manager.cpp:1043) [5889][0][Y0-0000000000000000] [lt=5] [dc=0] open file fail(ret=-4009, fname="/home/admin/oceanbase/store/lzq/slog/4", flag=1069122, errno=13, errmsg=“Permission denied”)
ERROR [SERVER] init (ob_server.cpp:172) [4195][0][Y0-0000000000000000] [lt=2] init config fail(ret=-4009)
信息:3.1.2
问题原因:OCP 部署或接管的 OceanBase 集群,默认均是 admin 用户权限,使用 root 启用后会导致observer.conf.bin 文件和 redo 日志目录下的文件权限变更,无法再使用 admin 启动成功 。
解决方案:修改所有 observer 目录的权限,重新使用 admin 用户启动。
chown -R admin.admin /home/admin/oceanbase/
chown -R admin.admin /data/1
chown -R admin.admin /data/log1
重启 OCP 服务方式
注意
该文档只针对 4.x 版本,3.x 版本 OCP 容器内有 ocp-proxy 服务,4.x 移除该服务。
OCP 服务重启方式:
重启 OCP 涉及 3 个组件,OCP 容器、MetaDB 元数据库、OBProxy 服务。其中 MetaDB 分 2 种使用场景,自建MetaDB 和已有的 OceanBase 集群作为 MetaDB 使用。
1、停止 OCP 容器
#查看正在使用的容器
[root@test004 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
aca888292e98 reg.docker.alibaba-inc.com/oceanbase/ocp-all-in-one:v4.0.0-ce "/usr/bin/supervis..." 23 hours ago Up 23 hours ocp
#停止OCP容器
[root@test004 ~]# docker stop aca888292e98
aca888292e98
2、停止 MetaDB
1)使用自建 MetaDB
部署 OCP 时如果配置文件中参数设置是create_metadb_cluster: true ,会创建一个 OceanBase 集群当做 OCP 的元数据库(MetaDB),MetaDB 使用内置 OBD 方式自动安装的,无法直接使用 OBD 命令进行管理,只能通过杀进程的方式关闭 MetaDB。
#查看 metadb 进程
ps -ef|grep observer |grep -v grep
#推荐使用软杀方式,此方法进程退出需要 30s~60s,较为安全
kill pid
2)使用已有 OceanBase 集群作为 MetaDB,基本是上 OBD 部署的,可以直接使用 OBD 管理。
#停止 metadb
[root@test004 ~]# obd cluster stop test11
Get local repositories ok
Search plugins ok
Open ssh connection ok
Stop observer ok
Stop obproxy ok
test11 stopped
3、停止 OBProxy
使用已有的 OceanBase 集群作为 MetaDB,则可以直接使用 OBD 管理,执行上述 obd cluster stop test11命令时,会同时停止 OBProxy 服务。
若使用 OCP 的配置文件 config.yaml 部署时,部署了 OBProxy 服务,也是通过 OBProxy 连接 MetaDB 的,则只能通过杀进程的方式关闭。
#查看 obproxy 进程
ps -ef|grep obproxy |grep -v grep
#kill 方式杀掉进程
kill 守护进程pid
kill 进程pid
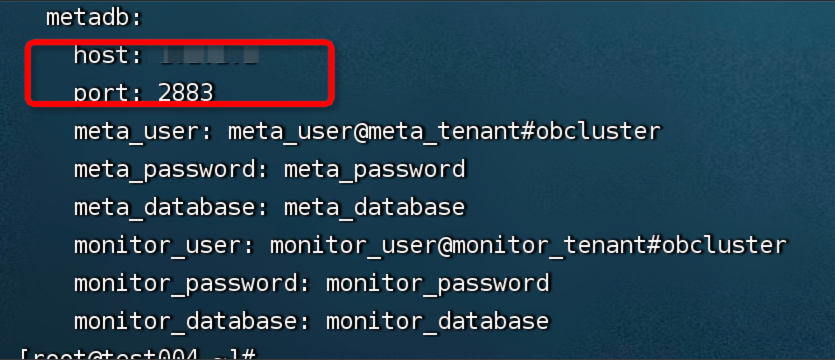
若不确定是否采用 OBProxy 连接的,可以通过部署 OCP 配置文件 config.yaml 的 metadb 模块确认。
判断方式:host:port 值对应 OBServer 服务还是 OBProxy 服务。
4、启动 MetaDB
1)使用自建 MetaDB
#使用业务用户在 observer 安装目录下执行,否则无法拉起
cd ~/observer && ./bin/observer
#如果报错 libmariadb.so.3: cannot open shared object file
#需要将 OceanBase 数据库的 LIB 加到环境变量 LD_LIBRARY_PATH 中
echo 'export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/observer/lib/' >> ~/.bash_profile
2)使用已有 OceanBase 集群作为 MetaDB,基本是上 OBD 部署的,可以直接使用 OBD 管理。
#启动 metadb
[root@test004 ~]# obd cluster start test11
5、启动 OBProxy
若使用已有的 OceanBase 集群作为 MetaDB,执行上述 obd cluster start test11 命令时,会同时启动 OBProxy 服务。若使用 OCP 自建的 OBProxy 服务,则需要执行如下命令手动拉起。
#使用业务用户在 obproxy 安装目录下执行,否则无法拉起
[admin@obtest002 obproxy]$ cd ~/obproxy && ./bin/obproxy
#启动守护进程
[admin@obtest002 obproxy]$ chmod 733 obproxyd.sh
[admin@obtest002 obproxy]$ sh obproxyd.sh /home/admin/obproxy xxx.xxx.xxx.xxx 2883
6、启动 OCP 容器
#查看所有容器
[root@test004 ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
aca888292e98 reg.docker.alibaba-inc.com/oceanbase/ocp-all-in-one:v4.0.0-ce "/usr/bin/supervis..." 24 hours ago Exited (137) 56 minutes ago ocp
#启动 OCP 容器
[root@test004 ~]# docker start aca888292e98
aca888292e98