文档地址: 3.3 OceanBase 的 Compaction 设计-开发者进阶教程-OceanBase文档中心-分布式数据库使用文档
这两部分的描述,感觉像是L0层的Mini SSTable 直接Compaction到 L2层的Major SSTable中去了,按理不是L0层的 Compaction到L1,L1 compaction到L2层吗?
不知道是不是我理解有误?
文档地址: 3.3 OceanBase 的 Compaction 设计-开发者进阶教程-OceanBase文档中心-分布式数据库使用文档
这两部分的描述,感觉像是L0层的Mini SSTable 直接Compaction到 L2层的Major SSTable中去了,按理不是L0层的 Compaction到L1,L1 compaction到L2层吗?
不知道是不是我理解有误?
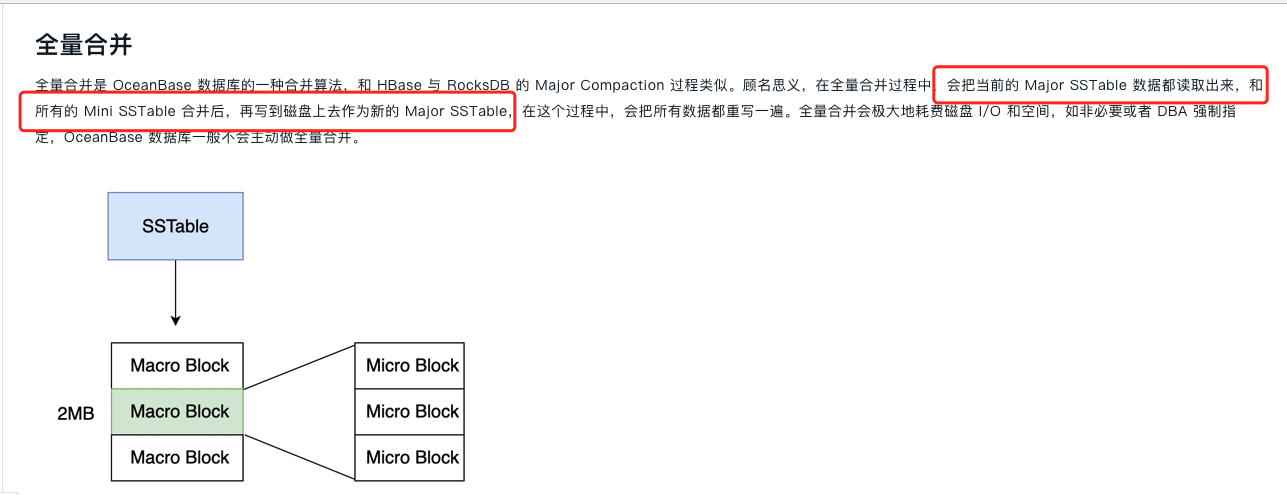
OceanBase 数据库的转储分为以下三层:
level-0 到 level-n 层,每层最大容纳的 SSTable 个数相同。当 L0 层 level-n 的 SSTable 到达一定数目上限或阈值后开始整体合并,合并成一个 SSTable 写入 level-n +1 层。当 L0 层的最大 Level 内的 SSTable 个数达到上限后,开始做 L0 层到 L1 层的整体合并来释放空间。在存在 L0 层的转储策略下,冻结 MEMTable 直接转储在 L0-level-0 写入一个新的 Mini SSTable,L0 层每个 Level 内的多个 SSTable 根据 base_version 有序,后续本层或跨层合并时需要保持一个原则,参与合并的所有 SSTable 的 Version 必须邻接,这样新合并后的 SSTable 之间仍然能维持 Version 有序,简化后续读取合并逻辑。L0 层的内部分层会延缓到 L1 的合并,更好地降低写放大,但同时会带来读放大,假设共 n 层,每层最多 m 个 SSTable,则最差情况 L0 层会需要持有 (n * m + 2) 个 SSTable,因此实际应用中层数和每层 SSTable 上限都需要控制在合理范围。https://www.oceanbase.com/docs/enterprise-oceanbase-database-cn-10000000000886122
“是L0层的Mini SSTable 直接Compaction到 L2层的Major SSTable中去了”,这个理解是对的。
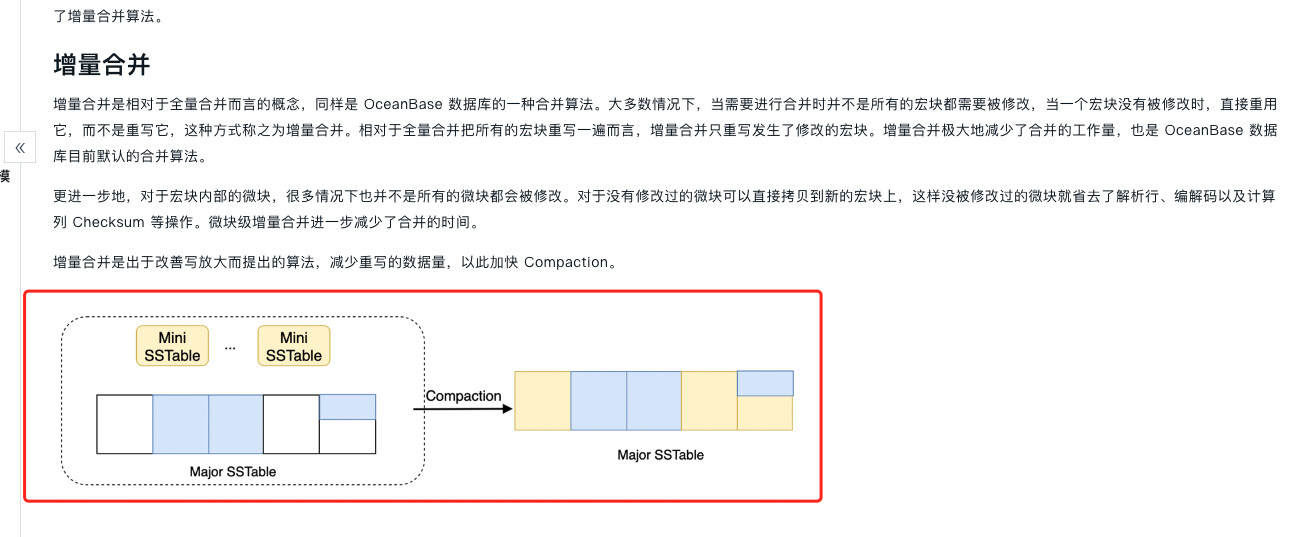
L0层和L1层本质上是同种sstable,只是大小不同,合并会将L0/L1/L2的sstable在一个时间位点上合成一个major sstable。增量和全量的区别主要在于对于未修改的宏块是否打开
那我是不是可以这么理解:
frozen memtable 到L0只是转储
L0层到L1层并没有发生压缩,只是有合并
L1或者L0 到L2才会发生压缩
如果不对,您能方便告知下L1层(minor sstable)和L0(mini sstable)层有什么区别吗?或者L0(mini sstable)做了什么操作变成了L1 minor sstable(详细点的)
压缩都是会发生的。
frozen memtable->L0是转储。
L0->L0是mini minor merge,多个mini合成一个更大的mini,L0->L1是minor merge,多个mini和一个minor合成一个minor。
合并是多个mini,minor和major合成一个major。
区别就是L1层是一个minor sstable(很大的mini sstable),L0层是多个mini sstable。
具体操作都是类似的,就是将多个sstable的数据读出来,然后排序写回新的sstable,和LSM-Tree的基础概念是一样的。但我们是微块/宏块的数据块大小,如果微块/宏块内数据没有做修改是可以直接重用的。
我会推进一下文档的修改
![]()
![]()
![]()
![]()
![]()
你有看过源码吗??
不好意思,我看官方文档。
不一定必须看源码才知道
文档和代码有误
那就有劳你进行源码和文档反馈,进行更正了。
还有我看的是3.x版本文档,并不是4.x