先华为后天
#1
1、 4.0版本未找到参数minor_merge_concurrency, OceanBase分布式数据库-海量数据 笔笔算数
2、根据文档 OceanBase分布式数据库-海量数据 笔笔算数 描述,L0层有多层 ,层数、每层数量或大小是什么,有没有参数可以设置?
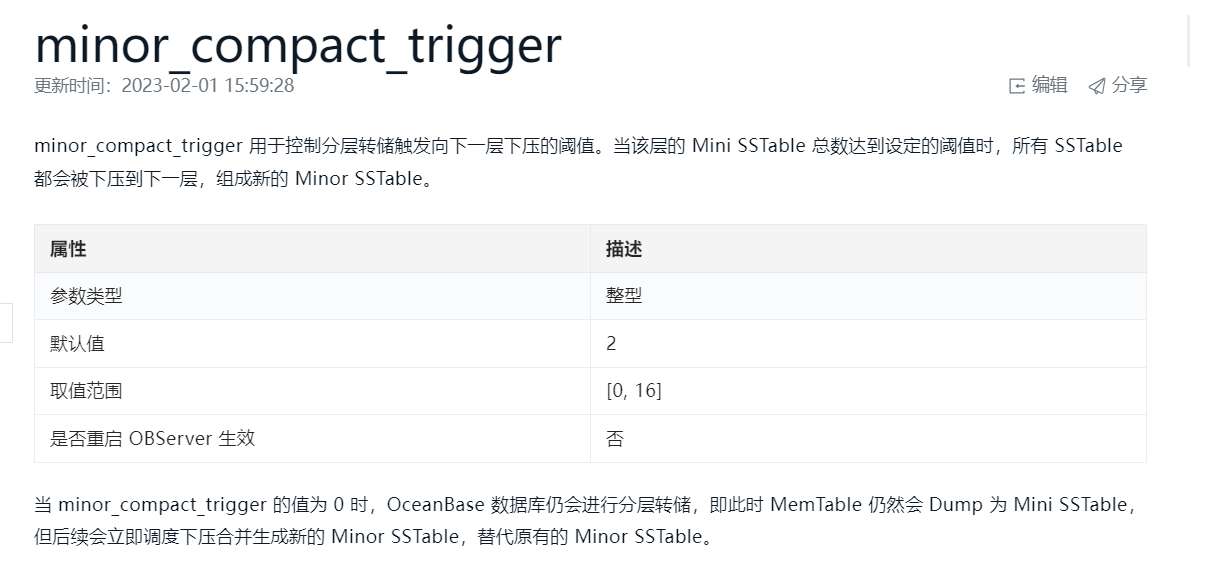
minor_compact_trigger(用于控制分层转储触发向下一层下压的阈值。当该层的 Mini SSTable 总数达到设定的阈值时,所有 SSTable 都会被下压到下一层,组成新的 Minor SSTable) 这个值4.0版本默认是2个,就是说L0层有2层,每层1个文件吗?
文档说 ‘当 L0 层的最大 Level 内的 SSTable 个数达到上限后,开始做 L0 层到 L1 层的整体合并来释放空间。’ 感觉又和上面描述有些冲突,L0到L1的合并触发_minor_compaction_amplification_factor 是以哪些的比例为准(层级间的总大小、总数量、 还是 L0max的数量)?
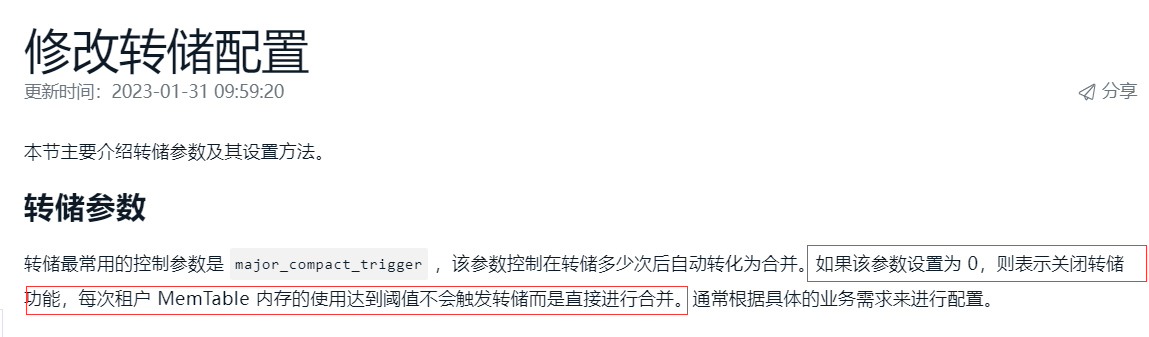
3、 major_compact_trigger: 该参数控制在转储多少次后自动转化为合并。如果该参数设置为 0,则表示关闭转储功能,每次租户 MemTable 内存的使用达到阈值不会触发转储而是直接进行合并。通常根据具体的业务需求来进行配置。 在4.0版本默认是为0,出于什么样的考虑? 和上面的minor_compact_trigger的相互作用是什么样?
4、关于合并方式中的几个问题:
(1) 文中说增量合并是现在默认方式,是哪些情况下的,比如达到 major_compact_trigger还是每日的自动合并?
(2) 渐进合并是为了处理DDL的回写数据,这个有什么特殊性吗,按照前面的正常流程做增量或全量合并有什么问题? 渐进合并过程中是不是也是增量的方式?
(3) 全量合并中说 ‘和内存中的动态数据合并后’ 这里内存中动态数据合并时是怎么处理,是直接读内存和文件数据一起合并还是触发一个内存数据落盘后 只读所有磁盘文件来合并? 合并时是从l0 到l1 在到l2 一层合并,还是所有数据读取后一起写到L2 ,删除l0/l1的数据?
(4) 前面这几种方式都是用并行方式吗? 所有的方式是否有参数可控制?
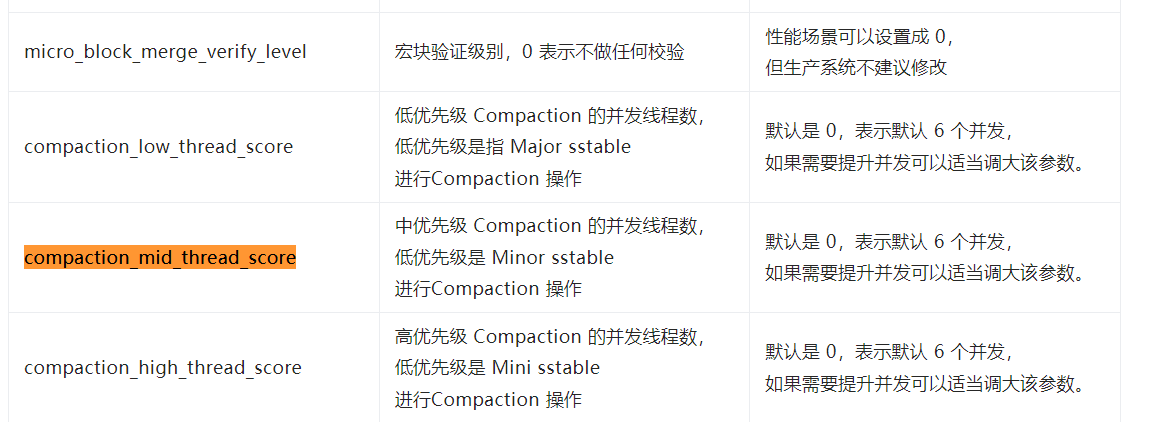
5、compaction_high_thread_score 指的L0 内的mini sst compact还是L0 写到L1 . compaction_mid_thread_score L1的compact指的的L0 写到L1 还是L1写到L2,貌似没看到有L1写到L2描述?
镜水
#3
1.4.0中该参数改为了compaction_mid_thread_score,minor merge属于中级优先级任务
2. “这个值4.0版本默认是2个,就是说L0层有2层,每层1个文件吗?” 按文档你可以理解L0层就是一堆mini sstable,L1层是minor sstable,两者的区别在于大小。我理解现在应该没有分层转储这种概念。
先华为后天
#6
感谢!
第2个问题: 如果minor_compact_trigger指的是数量,那是不是文档中描述有误,还是版本变化后没有更新文档?
第3个问题 : major_compact_trigger在4.0版本里我看我的库里默认是0,按照参数解释描述,0关闭转储了直接进行合并,这个考虑是什么? 还是说版本变化后文档没更新? 关于minor_compact_trigger 我是想问如果major_compact_trigger=0表示关闭转储那是不是minor_compact_trigger怎么设置都不会有效果?
第4个问题: (2) 渐进合并过程大概了解,但是为什么DDL中需要回填的数据要采用这种方式处理?
(3) 能在详细说下过程吗?
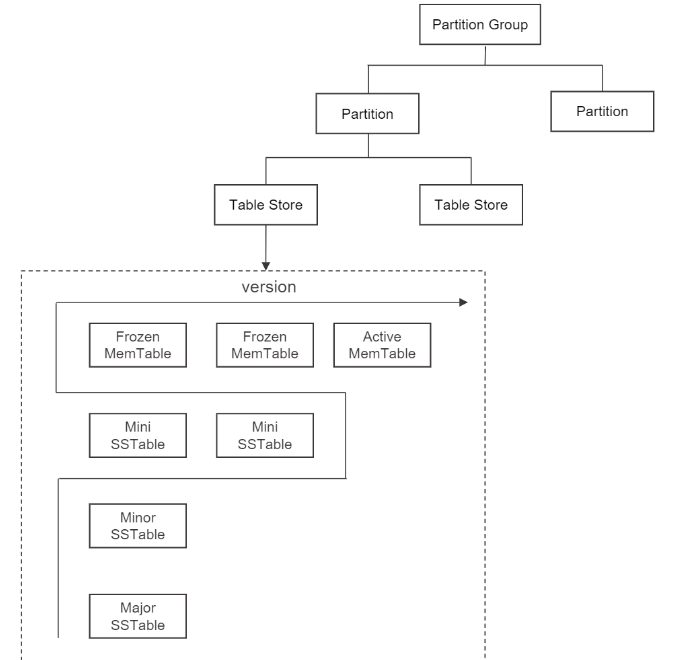
新增问题5: 按照下图描述 一个分区包含有多个table store, table store大小或范围划分的依据是什么? 这个图看上去每个table store就是一个ob的lsm tree,在转储 合并时 每层是在自己的table storen内完成还是多个table store作为一个整体处理的?
镜水
#7
2.目前文档是有些没更新的地方,后续应该会有更新,抱歉
3.这个设置为0是指将转储多少次触发合并的这个触发方式关闭,并不是指不转储
4.(2)因为ddl可能会导致全部数据的重写,这个过程如果一次完成的话开销比较难以接受
(3)前面的说法不够准确,本质上讲全量合并是合并时未修改的宏块仍然会打开去处理/重写,而增量合并时未修改的宏块不会打开,而是直接重用。 合并方式按文档来说你可以简单理解L0/L1/L2所有数据一起写到L2。其实不用拘泥于L0/L1/L2层级,简单来说,从上到下分成mini/minor/major sstable三类,mini和minor是同种sstable,只有残量数据,区别只是数据量大小不同,而major是全量数据。合并就是mini/minor/major sstable->major sstable的过程。
5.多个table store不是指多个范围,而是可以理解为多个版本,多个table store内部的结构是共用的。比如一个table store刚开始有一个memtable,经过mini merge会下刷到一个sstable里,此时新建一个table store作为下刷memtable后的版本,而老版本的memtable在没有回收的情况下保留在旧table store中。这样做的目的是防止memtable下刷后直接使用新table store查询sstable,相对于查旧memtable而言性能会快速下降,因此通过这种预热的方式让查询性能相对稳定。
是在一个table store里完成。
先华为后天
#8
非常感谢!
2. 只是为了确认描述的和自己理解的是否正确,并不是为了听道歉,您客气了 , 我现在是不是就可以理解为在4.0版本中 minor_compact_trigger 就是指的sstfile的数量、没有文档中描述的L0 分了很多层那样?
3. 关闭转储这个描述 同样也是官方文档里写的。 应该也是描述有误吧?
4、(2) 每日合并是L0-L2全量的数据读取然后写入L2,那么增量合并是哪些场景下能触发呢?
5、 table store是这个memetable和L0有关系吗?在memtable 达到freeze_trigger_percentage 阈值转储后其内存空间并不释放,这块内存空间再什么时候回被重用或释放?
镜水
#9
2.可以这样理解,就是mini sstable的上限
3.是的,描述不够准确
4.(2)增量与全量合并是合并时的一种策略,通过该参数进行设置
简单解读就是为0会以默认的次数进行渐进合并:每轮一部分做全量,另外的部分做增量(见之前的回答)
为1时不做渐进合并,而是每次合并都是全量合并;
大于1则以设定的次数进行渐进合并
5.table store是一个集合体,简单来说就是包含指向memtable/sstable的指针;
内存回收则涉及具体的一些策略,与留存时间/版本有关系
镜水
#11
这个是3.x的概念,通过 minor_warm_up_duration_time参数设置。
4.0上不再有这个概念,会尽快回收memtable,下刷的sstable会有中间层的一些索引直接缓存在cache。文档里确实有很多描述不准确的地方,并且4.0的很多细节更新文档也没有完全覆盖,这方面会持续加强,见谅。
先华为后天
#12
非常感谢,再问下,
1、 L0 层分层的问题 是在哪个版本后就没有了像官方文档提到的那样 ‘分多层,每层文件数相同’ ?
2、关于minor_warm_up_duration_time 找到两个看上去不太一样的解释:第一个强调的是把memtable请求在预热时间内‘转移’到sstable上,第二个是强调的是提前装载。这个一个具体的流程是什么样? 4.0废弃这个参数后的变化是什么样呢?
—1
— 2
镜水
#13
1.个人理解这是文档描述不准确的问题,一直是没有L0内部分多层,每层文件数相同这种概念的
2.第二个描述有问题,简单来说开启预热,Memtable会在老版本的table_store中被持有引用计数,预热时间(即该参数)结束前,Memtable不能释放;4.0有cache预热,会将新sstable的一些信息预热到cache,具体方式我不太了解,但新的预热方式能够更合理的使用内存。
先华为后天
#14
感谢!
1、 写文档的这人…,这个描述误差实在是太大了。
2、 4.0之前的预热除了引用计数外有其他什么磁盘数据加载吗? 比如类似 :读老的memtable时同时会触发一个磁盘读取加载到kv cache,然后到超过30秒预热阈值后直接释放memtable
镜水
#15
4.0之前还有在轮转合并时的预热。 当一个数据副本在进行合并时,会将这个副本上的查询流量切到其他没在合并的集群上面。为了避免流量切过去后,cache较冷造成的rt波动,合并前leader会将本地 SSTable 上的读请求进行记录,并按照时间控制比例渐进的通过 RPC 发送给follower,由备机在本地 SSTable 上模拟执行,这相当于一个预热过程。 merger_warm_up_duration_time是用来控制这个合并前预热过程时长的。