

集群之间执行相同sql,相同数据情况下为什么执行的时间不一样?
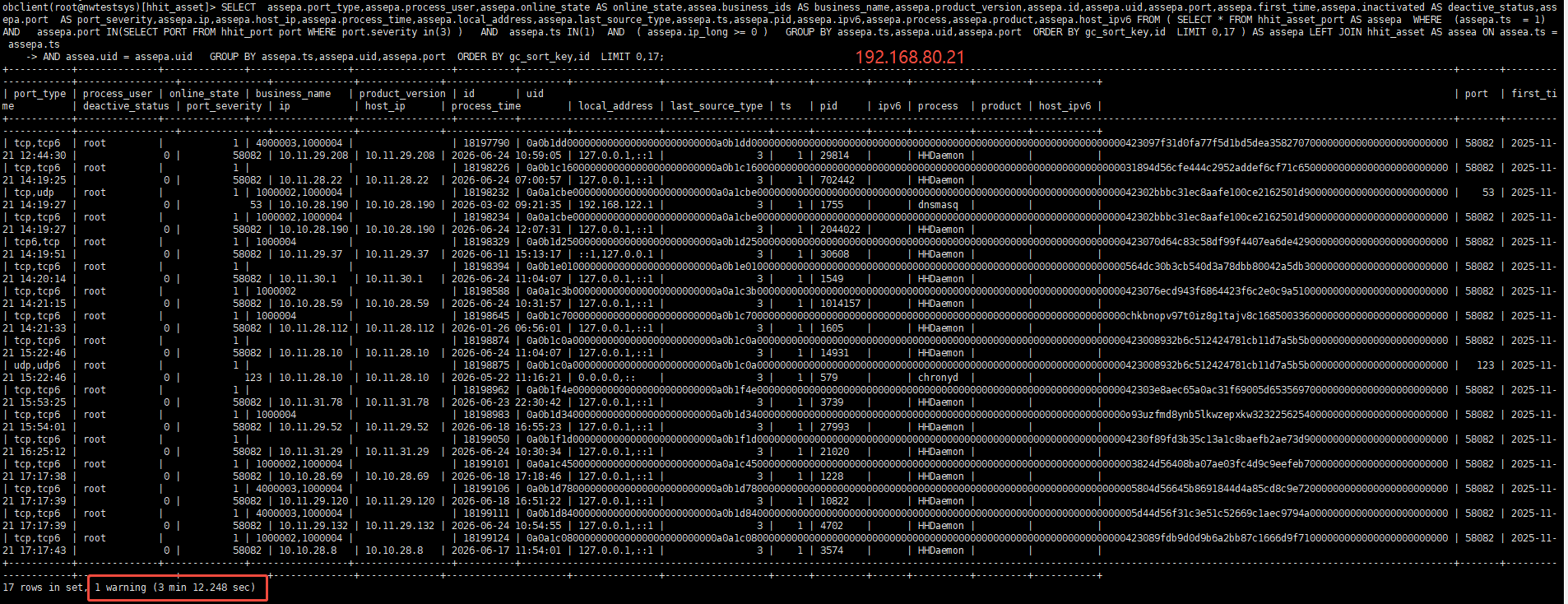
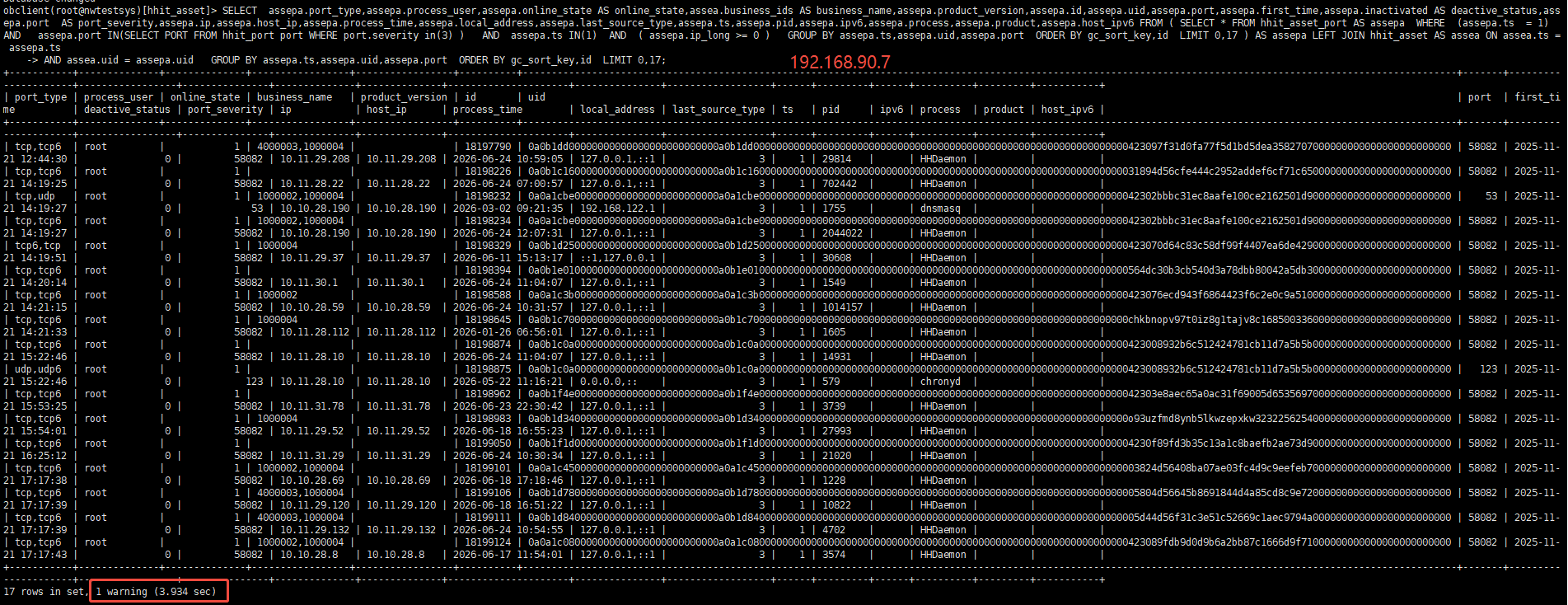
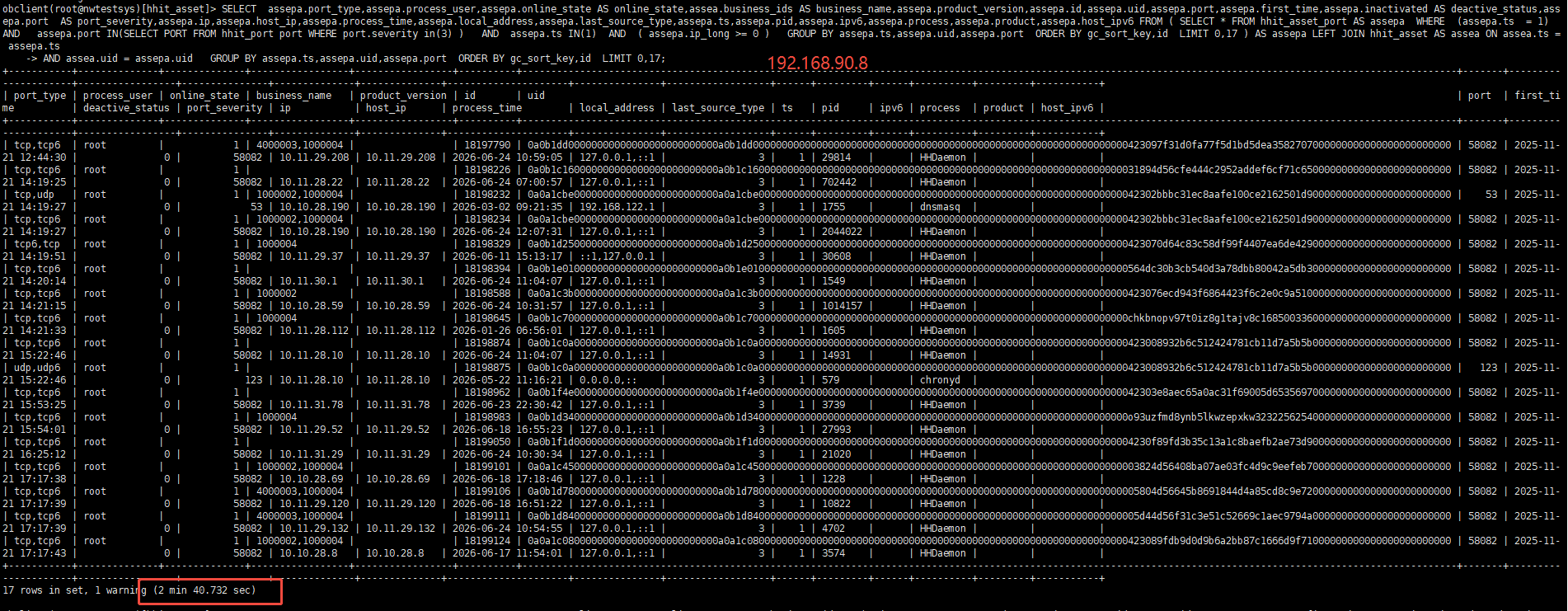
具体的执行耗时
有什么会影响吗,有odp有业务链接,数据库集群
在 OceanBase(OB)集群中,即使 SQL 语句和底层数据完全一致,不同集群或节点间的执行时间差异主要源于分布式架构特性、资源竞争状态及优化器决策机制等。
有没有优化的点呀,主要执行时间相差的有点多
换集中式。
加油!!!
执行计划也发一下看看呢
根据不同的observer节点的ip sql_id过滤一下信息
SELECT svr_ip,usec_to_time(request_time),trace_id,query_sql, request_id, is_hit_plan, get_plan_time, plan_hash,plan_id, sid, client_ip FROM oceanbase.GV$OB_SQL_AUDIT WHERE sql_id = ‘FF6D3AF8A3F1B89BEA3DC22E4B3DF635’ and svr_ip=’’ ORDER BY request_time DESC LIMIT 50;
查一下计划缓存信息
SELECT plan_id, plan_hash, plan_status, adaptive_feedback_times, first_load_time, executions, hit_count FROM oceanbase.GV$OB_PLAN_CACHE_PLAN_STAT
WHERE sql_id = ‘FF6D3AF8A3F1B89BEA3DC22E4B3DF635’
ORDER BY first_load_time;
方法一:重新收集统计信息(ANALYZE TABLE hhit_port UPDATE HISTOGRAM ON port; ANALYZE TABLE hhit_asset_port UPDATE HISTOGRAM ON port;)
方法二:SQL Hint 强制 Hash Join
方法三:SQL 改写(避免 IN 子查询被展开为 NLJ);
这个是因为统计信息不同步导致的嘛
方法一是在每一个数据库里面都执行一次,还是只在一台执行
慢的上面
你发的是逻辑执行计划 没有发物理执行计划 不能确定一下 数据库执行的确实是不一样的
对节点下不一样 或许和你查询的表的分布有关系 如果表是分区表 primary_zone如果是默认的 分区leader应该是打散的 会在不同的节点上生成不同计划 只要在同一个节点上 不是来回突变 就不是问题
有没有一次性整体同步的sql
统计信息是不是有问题
如果是统计信息不同步这个要怎么解决,里面有不是一个库一张表。
方法一执行过后还是一样的情况
学到了
有没有大佬帮忙看看为什么