案例一 和 案例二 , 并没有不同。
案例二的表仅仅只是多col3列。
那,为什么同样的查询语句,执行计划会不同呢 ?
案例一 和 案例二 , 并没有不同。
案例二的表仅仅只是多col3列。
那,为什么同样的查询语句,执行计划会不同呢 ?
支持支持
2个查询的OPERATEOR不同。
加油
| 特性 | TABLE RANGE SCAN | DISTRIBUTED TABLE RANGE SCAN |
|---|---|---|
| 执行位置 | 单个 OBServer 节点 | 多个 OBServer 节点(分布式) |
| 是否涉及 RPC | 否(本地执行) | 是(需远程调用) |
| 适用场景 | 数据局部性好、可下推 | 跨分区/跨节点查询 |
您的问题关于为什么在添加了一个额外的列(col3)之后,同样的查询语句会产生不同的执行计划。这主要涉及到 OceanBase 数据库如何优化查询以及索引的使用策略。
col1, col2) 的情况下,使用了 TABLE RANGE SCAN 操作符。col3) 后,使用了 DISTRIBUTED TABLE RANGE SCAN 操作符。idx2 索引仅包含 col2 列,而查询需要返回所有列(*)。因此,即使 col2 的值小于2,也需要通过主键查找其他列的值(col1),这导致了 TABLE RANGE SCAN。idx2 索引还是只包含 col2 列,但查询仍然需要返回所有列(包括新添加的 col3)。由于 col3 不在索引中,数据库可能选择了一种更复杂的分布式的范围扫描方式来获取数据,这就是 DISTRIBUTED TABLE RANGE SCAN。DISTRIBUTED TABLE RANGE SCAN 是一种分布式操作,它可以在多个节点上并行执行范围扫描,从而提高查询性能。这种操作符在处理大量数据时更为有效。希望这些解释能帮助您理解为什么在添加了一个额外的列后,查询的执行计划会有所不同。如果还有其他问题,请随时提问!
详情请参考:
您的理解是正确的。在OceanBase这样的分布式数据库中,"分布式表"确实指的是该表的数据被划分成多个分区,并且这些分区分布在集群中的多个节点上。这种设计的主要目的是为了实现数据的水平扩展以及提高系统的整体处理能力和容错性。
以您提供的案例为例,表 t1 通过 partition by hash(col1) partitions 5 定义了5个分区,这些分区根据 col1 的值通过哈希函数计算后被分配到集群的不同节点上。这样做的好处包括但不限于:
希望这能帮助您更好地理解分布式表的概念及其在OceanBase中的应用方式。如果还有进一步的问题,请随时提问!
检索到的文档如下:
分布查询性能会差,尽量本地
支持
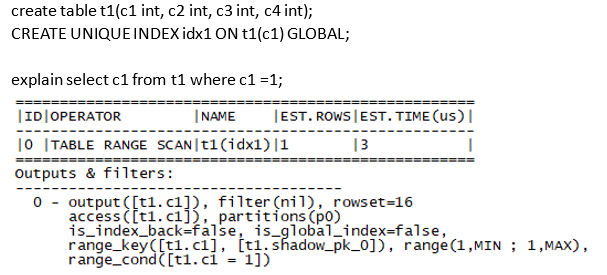
根据您提供的信息和OCR提取的文本内容,您提到的是一个唯一索引的等值查询。在理想情况下,对于唯一索引的等值查询,OceanBase 通常会使用 TABLE GET 算子来直接获取单行数据。然而,在您的例子中,执行计划显示使用了 TABLE RANGE SCAN 算子。这可能有几个原因:
统计信息不准确:
TABLE RANGE SCAN 而不是 TABLE GET。索引选择策略:
TABLE RANGE SCAN 而不是 TABLE GET。虽然 TABLE GET 适用于唯一索引的等值查询,但优化器可能认为 TABLE RANGE SCAN 在某些情况下更优。配置或版本差异:
全局索引的影响:
GLOBAL),这意味着索引的数据分布在多个节点上。在这种情况下,优化器可能选择 TABLE RANGE SCAN 来更好地处理分布式环境中的数据访问。TABLE GET 是最优选择,因为它可以直接定位到唯一的行。TABLE RANGE SCAN 的使用可能是因为优化器认为在这种情况下 TABLE RANGE SCAN 更适合。具体来说,TABLE RANGE SCAN 仍然可以有效地找到唯一的一行数据,尤其是在全局索引的情况下。更新统计信息:
ANALYZE TABLE t1;
强制使用 TABLE GET:
TABLE GET 是最优选择,可以尝试使用 Hint 来强制优化器使用 TABLE GET。EXPLAIN SELECT /*+ USE_INDEX(t1 idx1) */ c1 FROM t1 WHERE c1 = 1;
检查配置:
在您的案例中,优化器选择了 TABLE RANGE SCAN 而不是 TABLE GET,这可能是由于统计信息不准确、优化器的索引选择策略或其他配置因素。建议您更新统计信息并尝试使用 Hint 来强制优化器使用 TABLE GET。如果问题仍然存在,可能需要进一步检查具体的配置和环境。
希望这些解释能帮助您理解为什么会出现这种情况。如果还有其他问题,请随时提问!
具体信息可参考以下文档:
根据您提供的信息和OCR提取的文本内容,您展示了两个不同的执行计划,尽管查询语句是相同的。让我们详细分析一下这两个执行计划的不同之处以及可能的原因。
create table t1(col1 int primary key, col2 int, col3 int) partition by hash(col1) partitions 5;
create index idx2 on t1(col2) GLOBAL;
explain select * from t1 where col2 < 2;
执行计划:
| ID | OPERATOR INAME | EST. ROWS | EST. TIME(us) |
|----|----------------------------------|-----------|---------------|
| 0 | DISTRIBUTED TABLE RANGE SCAN | t1(idx2) | 1 |
outputs & filters:
0 - output([t1.col1], [t1.col2], [t1.col3]), filter(nil), rowset=16
access([t1.col1], [t1.col2], [t1.col3]), partitions(p0)
is_index_back=true, is_global_index=true, keep_ordering=true,
range_key([t1.col2], [t1.col1]), range(NULL,MAX ; 2,MIN),
range_cond([t1.col2] < 2)
create table t1(col1 int primary key, col2 int, col3 int) partition by hash(col1) partitions 5;
create index idx1 on t1(col2);
explain select * from t1 where col2 < 2;
执行计划:
| ID | OPERATOR INAME | EST. ROWS | EST. TIME(us) |
|----|----------------------------------|-----------|---------------|
| 0 | PX COORDINATOR | 1 | 25 |
| 1 | └─EXCHANGE OUT DISTR | :EX10000 | 1 |
| 2 | └─PX PARTITION ITERATOR | | 1 |
| 3 | └─TABLE RANGE SCAN | t1(idx1) | 1 |
outputs & filters:
0 - output([INTERNAL_FUNCTION(t1.col1, t1.col2, t1.col3)]), filter(nil), rowset=16
1 - output([INTERNAL_FUNCTION(t1.col1, t1.col2, t1.col3)]), filter(nil), rowset=16, dop=1
2 - output([t1.col1], [t1.col2], [t1.col3]), filter(nil), rowset=16
force partition granule
3 - output([t1.col1], [t1.col2], [t1.col3]), filter(nil), rowset=16
access([t1.col1], [t1.col2], [t1.col3]), partitions(p0-4)
is_index_back=true, is_global_index=false,
range_key([t1.col2], [t1.col1]), range(NULL,MAX ; 2,MIN),
range_cond([t1.col2] < 2)
索引类型不同
idx2。全局索引的数据分布在多个节点上。idx1。本地索引的数据与表数据一起存储在同一个分区中。执行计划差异
DISTRIBUTED TABLE RANGE SCAN 算子。这表明优化器认为通过全局索引进行分布式范围扫描是最优的选择。PX COORDINATOR、EXCHANGE OUT DISTR 和 PX PARTITION ITERATOR 算子,最终使用 TABLE RANGE SCAN 算子。这表明优化器选择了并行处理的方式来执行查询,并且使用本地索引来访问数据。全局索引 vs 本地索引
优化器的选择
idx2,执行计划选择了 DISTRIBUTED TABLE RANGE SCAN,因为全局索引的数据分布在多个节点上,适合分布式范围扫描。idx1,执行计划选择了并行处理的方式,使用 PX COORDINATOR、EXCHANGE OUT DISTR 和 PX PARTITION ITERATOR 算子,最终使用 TABLE RANGE SCAN 算子,因为本地索引的数据与表数据一起存储在同一个分区中,适合并行处理。希望这些解释能帮助您理解为什么同样的查询语句会有不同的执行计划。如果还有其他问题,请随时提问!
详情请参考:
学习一下
两个案例计划不同,主要看全局索引能不能覆盖 select 的列。案例一表里只有 col1、col2,全局索引 idx2(col2) 本身已包含主键 col1,能覆盖 select *,所以直接走索引不回表(is_index_back=false);案例二多了 col3,索引覆盖不到,select * 必须回表取数,代价变了,执行计划自然就不同了。
第二个用的是das获取数据方式,如果数据不在本节点,并且数据量比较少,那么通过存储层rpc方式将远程数据get过来。如果在本地就不用了。
读完关于DISTRIBU的内容,感触很多。
学到了